Populaţie şi şcoli (de la INSse la Python şi R)
Câtă populaţie şi câte şcoli are fiecare judeţ ? Cât de adevărat ar fi, că numărul de locuitori influenţează „liniar” numărul de şcoli ?
Sunt oare importante (sau… corect puse), aceste întrebări ⁈ Mai degrabă nu; dacă ar fi, probabil că am găsi uşor datele brute necesare investigării—dar constatăm că nu prea este cazul şi pentru a obţine totuşi numerele necesare, avem de conceput anumite programe „intermediare” (iar aceasta, împreună cu ce-i prin jur, face ca şi lucrurile neimportante să devină măcar interesante).
Căutarea firească a datelor brute
Pe //data.gov.ro găsisem în 2016 – în setul de date "Demografie" – fişierul Excel "populatia-romaniei-pe-judete.xls" (descris cu tot dichisul şi exploatat în [1]); un asemenea fişier (dar actualizat pentru 2019), ar fi necesar acum. Astăzi însă (prin martie 2020) – n-am reuşit să mai dau de vreun set de date demografice.
În schimb, am remarcat desigur noua „faţă” a site-ului; se foloseşte ca şi mai înainte, CKAN ("a tool for making open data websites", bazat intern pe Python, Apache, PostgreSQL şi pe JDK) şi se folosesc bineînţeles Bootstrap, jQuery şi Jinja2. Lucrurile arată nemaipomenit, totuşi decent, dar nicidecum simplu şi sobru ca pentru sarcina de a furniza celor interesaţi seturi de date; pe de altă parte, probabil că "open data websites" implică şi asigurarea către terţi (instituţii) a posibilităţii de "upload"-are directă a seturilor de date (în diverse formate) – încât o asemenea complexitate a instrumentării lucrurilor poate să pară justificată (cu atât mai mult desigur, cu cât se permit şi comentarii din parte utilizatorilor).
Pe //insse.ro/cms/ (Institutul Naţional de Statistică) am avut mai mult noroc: deja pe pagina de bază găsim afişat mare "Populaţia rezidentă 19,4 mil. persoane" (la 1 ianuarie 2019); însă nu am reuşit imediat, să găsesc şi vreo statistică pe judeţe.
În schimb, am remarcat ştirea despre conferinţa internaţională Use of R in Official Statistics, în care se recunoaşte că „R a devenit «lingua franca» pentru statisticieni, metodologi și cercetători de date din întreaga lume”. Această ştire ar trebui să încurajeze şi la noi, preocupările faţă de R; dar ştiind aplecarea obstinentă (şi în învăţământ şi în instituţii) faţă de produsele Microsoft şi tehnologia "point-and-click" – estimez că la noi, conferinţa respectivă nu va avea cine ştie ce urmări…
Totuşi, pe de o parte, am identificat pagina Site-urile Direcțiilor Regionale și Județene de Statistică, pe care se precizează că site-ul asociat unui judeţ se poate accesa prin www.[nume_judet].insse.ro. De exemplu, //vaslui.insse.ro/ ne conduce la site-ul "Direcţia Judeţeană de Statistică VASLUI" – iar aici vedem imediat (afişat mare) ceea ce ne interesează: "Populaţia la 01.01.2019" este 495779.
Pe de altă parte, am identificat link-ul TEMPO-ONLINE („baze de date statistice”) şi acesta iată că furnizează datele dorite, anume cam aşa:
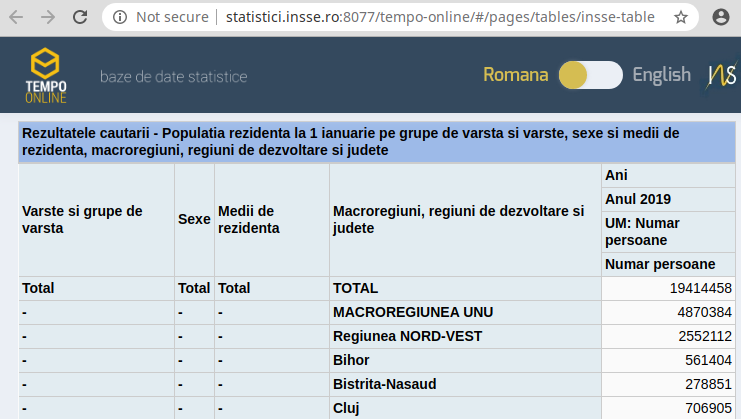
Tabelul furnizat poate că este frumos colorat (şi nobil liniat), dar altfel este oribil (îi lipseşte doar celebra coloană iniţială "Nr.Crt.", ca să fie cotat ca funcţionăresc); un tabel de vreo 60 de rânduri merită prezentat mai simplu şi mai convenabil. Dar nu „cum arată” ne interesează, ci cum putem extrage datele din acest tabel (spre a le folosi eventual în programele proprii; preferam desigur, să ni se dea un fişier CSV simplu).
Dar să nu ne grăbim să extragem de aici datele… Pe linia judeţului Vaslui găsim în coloana "Numar persoane" valoarea 373863 – ori aceasta diferă semnificativ faţă de aceea menţionată la "Populaţie" pe site-ul //vaslui.insse.ro (valoare pe care am redat-o mai sus). Diferenţele între valorile din tabel şi cele furnizate de site-urile judeţene s-ar explica prin faptul că "Numar persoane" exclude persoanele care au emigrat, în timp ce "Populaţie" vizează toate persoanele cu domiciliul în judeţ.
Prin urmare, avem de ales între cele două categorii de date - cele furnizate prin tabelul redat parţial mai sus şi respectiv, cele pe care le putem prelua de pe site-urile //nume_judet.insse.ro. Dar nu ne gândim aici, la o alegere „ştiinţifică”, ci doar la aceea care este mai interesantă pentru programare: vom accesa cele 42 de site-uri judeţene, preluând de pe fiecare valoarea înscrisă la "Populaţie".
Extragerea datelor din tabele „invizibile”
Ca să accesăm site-urile //nume_judet.insse.ro avem nevoie de "nume_judet"; nu putem obţine împreună aceste valori, prin procedeul obişnuit (sau vulgar): selectăm cu mouse-ul zona respectivă din pagina "Site-urile Direcțiilor Regionale..." afişată în fereastra browserului şi o copiem prin Ctrl-C – am obţine doar un text precum "Arad, Caras-Severin, Timis, Hunedoara", ori "nume_judet" nu este "Caras-Severin" ci "carasseverin" (şi nu este "Municipiul Bucuresti", ci "bucuresti").
Ca să obţinem link-urile respective trebuie să vizualizăm sursa paginii, folosind Ctrl-U; cel mai probabil, ele sunt conţinute într-un element <table> (nu-i obligatoriu; ar putea fi înscrise şi într-un <div>) – şi căutând prin Ctrl-F descoperim că există un <table> (şi numai unul singur) care într-adevăr, conţine link-urile pe care le vrem.
Tabelul HTML depistat astfel este „stufos”, specificând şi stilări sau atribute care nu ne interesează (precum <td style="background-color:rgb(...)"><a class="link"...); în loc să-l „periem” în gedit cum am face de obicei, preferăm să folosim Python astfel:
from bs4 import BeautifulSoup as BS import requests, csv f = csv.writer(open("nume_jud.csv", "w")) f.writerow(["Jud", "Link"]) # antetul fişierului CSV url = 'https://insse.ro/cms/ro/content/' + \ 'site-urile-directiilor-regionale-si-judetene-de-statistica' req = requests.get(url, headers = {'User-Agent': "and I'm a Browser"}) page = BS(req.content, 'html.parser') tabel = page.find('table') links = tabel.find_all('a') for lk in links: f.writerow([lk.get_text(), lk.get('href')])
Încărcăm în gedit fişierul CSV rezultat prin execuţia acestui program şi eliminăm toate porţiunile "http://www." şi ".insse.ro" (acestea încadrează "nume_judet"); deasemenea, corectăm denumirile judeţelor unde este cazul – se ştie că de obicei, pe site-urile instituţiilor publice lipsesc „diacriticele” (în plus, spaţiul este folosit defectuos: de exemplu apare "Nord - Est", dar apoi fară spaţiu "Sud-Vest").
Redăm fişierul final "nume_jud.csv", dar formatându-l aici pe coloane (după regiuni, pentru care am păstrat numai denumirea):
Jud,Link
Nord-Est, Sud-Est, Sud, Sud-Vest,
Botoşani,botosani Brăila,braila Argeş,arges Dolj,dolj
Neamţ,neamt Buzău,buzau Călăraşi,calarasi Gorj,gorj
Iaşi,iasi Galaţi,galati Dâmboviţa,dambovita Mehedinţi,mehedinti
Bacău,bacau Tulcea,tulcea Giurgiu,giurgiu Olt,olt
Suceava,suceava Constanţa,constanta Ialomiţa,ialomita Vâlcea,valcea
Vaslui,vaslui Vrancea,vrancea Prahova,prahova
Teleorman,teleorman
Vest, Nord-Vest, Centru, Bucureşti,
Arad,arad Bihor,bihor Alba,alba Ilfov,ilfov
Caraş-Severin,carasseverin Bistriţa-Năsăud,bistrita Braşov,brasov Bucureşti,bucuresti
Timiş,timis Cluj,cluj Covasna,covasna
Hunedoara,hunedoara Maramureş,maramures Harghita,harghita
Satu-Mare,satumare Mureş,mures
Sălaj,salaj Sibiu,sibiu
Printr-un program analog celui redat mai sus, vom accesa site-urile judeţene sintetizate în "nume_jud.csv" – urmând să vedem cum „extragem” de pe fiecare, valoarea pentru "Populatie".
Populaţia din fiecare judeţ
Accesând aleatoriu câteva site-uri //judet.insse.ro, conchidem că toate aceste 42 de site-uri au aceeaşi structură – bazată pe un acelaşi fişier-şablon, reflectând pe de o parte un conţinut comun tuturor judeţelor şi pe de altă parte, un conţinut adaptat judeţului. Pe toate, apare o „linie” cu trei coloane precum:

sau, pentru încă o exemplificare:

Ne interesează numai prima coloană ("populaţia după domiciliu") – ultimele două coloane variază după judeţ, în privinţa categoriei statistice reflectate. Majoritatea site-urilor reflectă populaţia de la 01.01.2019 şi probabil (neintenţionând o analiză sociologică riguroasă), o să ignorăm faptul că pe unele au fost făcute actualizări, vizând 01.07.2019 sau chiar "1 ian 2020".
Desigur, datele sunt redate încântător (ne mirăm că purtând mouse-ul pe prima coloană nu şi auzim ceva melodie "PO-pu-LAT-i-AA-aa--AA---LAaa- ..."); ce obiecte să fie, cele trei coloane? Sunt "link"-uri, cum vedem purtând mouse-ul pe fiecare şi observând "bara de stare" a browser-ului; şi anume, toate trei sunt link-uri identice, spre pagina care le cuprinde (https://[nume_judet].insse.ro/#) – cu una sau poate mai multe excepţii, când click-ul trimite la o pagină "OOPS! THAT PAGE CAN’T BE FOUND."
Vizualizând sursa paginii putem identifica <section class="frontpage-statistical"> care conţine o diviziune <div class="container"> care conţine o diviziune <div class="row"> care conţine trei diviziuni <div class="col-sm-12 col-md-12 col-lg-4" style="margin: 0.5em 0; z-index: 999;"> – câte una pentru fiecare coloană; fiecare coloană conţine un link <a class="btn btn-primary text-center" style="width: 100% !important; margin: 1.5em auto 0 auto !important; height: 10em !important;" href="#"> şi apoi, un element ca <h3 class="text-center">Populația la 01.01.2019</h3> urmat de un element ca <h1 class="text-center" style="font-size: 4em !important;">495779</h1>.
Esenţiale sunt cele două elemente (ultimul, de fapt) cu class="text-center", din fiecare coloană. Celelalte aşa de numeroase specificaţii (pe care m-am străduit să le redau mai sus), au un rol decorativ dubios, ţinând mai degrabă de spectacol şi de lipsa bunului simţ, decât de vreo sugestie de „ştiinţă”.
Următorul program Python mapează fişierul "nume_jud.csv" pe un dicţionar având drept chei "Jud" şi "Link" (din antetul CSV); pentru fiecare linie pentru care valoarea din "Link" nu este nulă (deci pentru judeţe, nu şi pentru regiuni) se accesează (folosind requests.get()) site-ul corespunzător acelui link (folosind un nume fictiv de "User-Agent", fără de care accesul ar fi interzis) şi folosind metode din BeautifulSoup, se extrage de pe pagina respectivă conţinutul primului dintre elementele <h1 class="text-center" ...>, scriind rezultatul obţinut într-un fişier CSV:
from bs4 import BeautifulSoup as BFS import requests, csv readNJ = csv.DictReader(open("nume_jud.csv")) f = csv.writer(open("jud_pop.csv", "w")) f.writerow(["Jud", "Pop"]) for row in readNJ: Jud = row['Jud']; Link = row['Link'] if Link: # ignorăm "regiunea" url = 'https://'+ Link +'.insse.ro/' req = requests.get(url, headers = {'User-Agent': "and I'm a Browser"}) page = BFS(req.content, 'html.parser') Pop = page.find('h1', class_='text-center') # numai primul <h1> if Pop: # la Hunedoara lipseşte <h1 class="text-center"> f.writerow([Jud, Pop.contents[0]]) else: f.writerow([Jud, ''])
Redăm parţial fişierul "jud_pop.csv" rezultat, constatând anumite gafe şi greşeli:
Jud,Pop Botoşani,454919 Neamţ,566870 Iaşi,<h2>956.216 persoane</h2> # H2 conţinut în H1 (??) ... Brăila,<h1>342663 pers.</h1> Buzău,462942 pers. ... Timiş,<h4> noiembrie 2019</h4> Hunedoara, Bihor,616264 Bistriţa-Năsăud,COVID-19 ... Sibiu,"<font color=""Coral""><h2>467.568 persoane</h2></font>" ...
Este o dovadă de proastă învăţare, să pui drept conţinut al unui element <h1> un element de aceeaşi natură – cum vedem pe liniile Iaşi, Brăila, Timiş, Sibiu redate mai sus (e drept că browserele nu te reclamă în mod explicit pentru gafele tale din codul HTML).
Bineînţeles că vom elimina de peste tot "persoane" şi "pers.". Pe de altă parte, constatăm că avem de corectat cumva (inspectând eventual chiar site-ul judeţului) în trei locuri: la Timiş nu este indicată populaţia, ci "Efectivul salariaţilor" (pentru "noiembrie 2019"); la Hunedoara nu există elemente <h1> (încât "Pop" a rămas necompletat); iar la Bistriţa-Năsăud primul element <h1> (dintre cele nouă aliniate acolo) are conţinutul "COVID-19" şi populaţia apare pe al treilea rând de elemente <h1>.
După corecturi (căutând eventual prin alte locuri, datele lipsă) – vom folosi fişierul "jud_pop.csv" ceva mai încolo, încercând mica analiză statistică propusă la început (vizând populaţia şi numărul de şcoli din judeţe).
Şcolile din fiecare judeţ
Mai avem nevoie de un fişier "jud_scl.csv", conţinând numărul de şcoli pe fiecare judeţ. Avem noroc (desigur): pe //data.gov.ro găsim un fişier CSV de 4.4MB denumit "datedeschise-specializari-2019-2020.csv" – o să-l redenumim "scoli19.csv" – care listează toate unităţile şcolare „subordonate Ministerului Educației Naționale care funcționează în anul școlar 2019-2020”. N-avem decât să numărăm liniile din acest fişier care corespund unui aceluiaşi judeţ (repetând pentru fiecare judeţ); secvenţa de operaţii necesară poate fi modelată foarte uşor în R, astfel:
vb@Home:~/20mar$ R -q # sesiune interactivă de lucru (workspace) în R > scoli19 <- read.csv("scoli19.csv") > jud_scl <- as.data.frame(table(scoli19$Judet)) > write.csv(jud_scl, file="jud_scl.csv", row.names=FALSE) > q() Save workspace image? [y/n/c]: y vb@Home:~/20mar$
Precizăm că dacă este cazul, se pot obţine uşor lămuriri pentru oricare comandă, tastând de exemplu help(data.frame), sau help(table), sau ?table (sau ?read.csv, etc.).
Redăm primele câteva linii din fişierul "jud_scl.csv" rezultat, pentru a lămuri ce mai avem de făcut:
"Var1","Freq" "ALBA",803 "ARAD",782 "ARGE?",1121 "BAC?U",1188 "BIHOR",1256 "BISTRI?A-N?S?UD",640
Încă se folosesc majuscule pentru denumiri (obicei general în instituţiile noastre, adoptat pe când se născuse problema semnelor "diacritice"); literele româneşti apar ca "?". Dar nu luăm mai mult seama, la niciunul dintre aceste aspecte: avem deja denumirile corecte ale judeţelor, în fişierul "jud_pop.csv"; n-avem decât să ordonăm la fel (după judeţ) cele două fişiere şi să păstrăm din "jud_scl.csv" numai coloana desemnată prin "Freq" (reprezentând numărul de şcoli din judeţ).
Populaţie, şcoli… şi greşeli
Reconstituim sesiunea de lucru în R anterioară şi ordonăm „la fel” (după coloana "Jud" şi respectiv "Var1") cele două fişiere:
vb@Home:~/20mar$ R -q > jud_pop <- read.csv("jud_pop.csv") > write.csv(jud_pop[order(jud_pop$Jud), ], file="jud_pop.csv", row.names=FALSE) > write.csv(jud_scl[order(jud_scl$Var1), ], file="jud_scl.csv", row.names=FALSE)
Deschizând în gedit cele două fişiere ordonate rezultate şi urmărindu-le „în paralel”, constatăm că în "jud_scl.csv" avem de inversat numai două sau trei linii (de exemplu, linia "MUNICIPIUL BUCURE?TI",1491 trebuie mutată după linia "BRA?OV",798).
Rămâne să „mutăm” coloana "Freq" din "jud_scl.csv" în "jud_pop.csv" şi folosim iarăşi R (nu fiindcă n-ar fi simplu de făcut şi altfel):
vb@Home:~/20mar$ R -q > rm(list=ls()) # elimină datele păstrate din sesiunea anterioară > jud_pop <- read.csv("jud_pop.csv") > jud_scl <- read.csv("jud_scl.csv") > jud_pop$Scl <- jud_scl$Freq # adaugă coloana Freq (numind-o Scl) din jud_scl > write.csv(jud_pop, file="judPopScl.csv", row.names=FALSE) > q() Save workspace image? [y/n/c]: n vb@Home:~/20mar$
Am preferat să scriem rezultatul în fişierul "judPopScl.csv"; de-acum nu vom mai avea nevoie de cele două fişiere CSV din care a provenit acesta.
Să listăm acum, datele grupate mai sus (judeţ, populaţie, şcoli):
vb@Home:~/20mar$ R -q > jPS <- read.csv("judPopScl.csv") > jPS Jud Pop Scl 1 Alba 375586 803 2 Arad 470846 782 ... ... ... ... 21 Gorj 362610 798 22 Harghita 71070 829 23 Hunedoara 464109 731 ... ... ... ... 42 Vrancea 388495 713 >
De ce ne-am temut (dat fiind modul în care am obţinut datele) nu am scăpat: pe linia 22 vedem că în judeţul Harghita ar fi numai 71070 de locuitori, ceea ce nu poate fi adevărat! Verificând //harghita.insse.ro vedem că numărul respectiv reprezintă doar "Efectiv salariaţi - dec 2019" (nu populaţia "cu domiciliul în judeţ", ca în majoritatea celorlalte cazuri – cum încă sperăm…).
Ce greşală! De fapt, greşala constă în faptul că n-am observat la timp situaţia constatată acum (trebuia observată atunci când am produs fişierul "jud_pop.csv").
Acuma, în loc să mai caut ce populaţie trebuie să înscriu pe linia 22 la Harghita (şi poate, să mai verific şi datele de la celelalte judeţe), am revenit într-o doară pe TEMPO-ONLINE ("baze de date statistice") şi am avut surpriza să văd că acum apare şi "POPULATIA DUPA DOMICILIU" (itemul de meniu "POP107A") şi încă, inclusiv la data de 01.01.2020 (la momentul când începusem să formulez cele de mai sus, apărea numai "populaţia rezidentă" şi numai până în 2019).
Nu mai descriem aici (nu că n-ar fi interesant), cum am „extras” datele furnizate prin "POP107A" (anume, cele pentru anul 2020) şi nici cum le-am înscris în locul celor existente în coloana "Pop" a fişierului "judPopScl.csv".
Şcoli vs. Populaţie (demersuri statistice)
Să listăm acum, datele grupate mai sus (judeţ, populaţie la 01.01.2020, şcoli în anul şcolar 2019-2020):
vb@Home:~/20mar$ R -q > jPS <- read.csv("judPopScl.csv") > jPS Jud Pop Scl 1 Alba 373710 803 2 Arad 470093 782 3 Argeş 632124 1121 4 Bacău 737629 1188 5 Bihor 616264 1256 6 Bistriţa-Năsăud 327886 640 7 Botoşani 456130 956 8 Brăila 340804 500 9 Braşov 638000 798 10 Bucureşti 2151665 1491 11 Buzău 461039 899 12 Călăraşi 306820 497 13 Caraş-Severin 315473 714 14 Cluj 736945 1053 15 Constanţa 763549 982 16 Covasna 225743 511 17 Dâmboviţa 518645 848 18 Dolj 686350 1129 19 Galaţi 628104 842 20 Giurgiu 269221 458 21 Gorj 355358 798
Jud Pop Scl 22 Harghita 330473 829 23 Hunedoara 453431 731 24 Ialomiţa 285100 424 25 Iaşi 965634 1473 26 Ilfov 451839 444 27 Maramureş 520551 940 28 Mehedinţi 277017 542 29 Mureş 590305 1142 30 Neamţ 566080 880 31 Olt 431248 837 32 Prahova 787529 1256 33 Sălaj 243525 530 34 Satu-Mare 386110 630 35 Sibiu 469285 725 36 Suceava 764123 1280 37 Teleorman 365976 570 38 Timiş 758380 1024 39 Tulcea 234243 406 40 Vâlcea 394725 718 41 Vaslui 504879 1003 42 Vrancea 382688 713
Am listat în ordinea alfabetică a valorilor "Jud" (uşurând astfel, eventuale confruntări cu alte surse); am redat lista pe două coloane, pentru a facilita observarea şi compararea datelor – "coloanele" fiind obţinute prin jPS[1:21, ] şi respectiv jPS[22:42, ].
Însă lucrurile pot deveni interesante ordonând nu alfabetic, ci după "Pop", sau după "Scl". Desigur, putem observa uşor şi direct pe lista redată pe două coloane mai sus, anumite discrepanţe – de exemplu, vedem că la Bihor şi Braşov populaţia diferă puţin (cu vreo 20000), dar numărul de şcoli diferă mult (cu vreo 350); probabil, explicaţia acestei „discrepanţe” ţine cel mai mult de relief (pare clar că pe o zonă muntoasă apar mai puţine construcţii decât pe o zonă întinsă). La fel poate, despre Tulcea şi Sălaj – au cam aceeaşi populaţie, dar diferenţă de vreo sută de şcoli; analog putem exersa pentru alte câteva cazuri.
Dar metoda cea mai bogată în sugestii, dacă e vorba de a confrunta una cu alta şi a sesiza anumite şabloane, constă în a reprezenta grafic mărimile respective.
Dar să vedem întâi cam ce fel de mărimi avem:
> summary(jPS[, c(2,3)]) # [, c(2,3)] selectează din toate liniile, coloanele 2 şi 3 Pop Scl Min. : 225743 Min. : 406.0 1st Qu.: 344442 1st Qu.: 632.5 Median : 458584 Median : 816.0 Mean : 527969 Mean : 842.0 3rd Qu.: 631119 3rd Qu.:1018.8 Max. :2151665 Max. :1491.0 > boxplot(jPS$Pop, horizontal=TRUE, cex.axis=0.8)
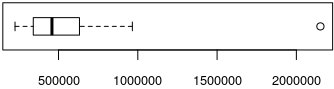
Valoarea cea mai mică de pe coloana "Pop" corespunde judeţului Covasna, iar cea mai mare – municipiului Bucureşti; aproximativ un sfert dintre cele 42 de linii au valoarea din "Pop" mai mică decât "prima quartilă" şi un alt sfert – mai mare decât a treia quartilă; celelalte 50% valori sunt reprezentate pe graficul furnizat de boxplot() printr-un dreptunghi care (pentru redarea orizontală) are latura stângă la gradaţia dată de "1st Qu" (să notăm Q1) şi latura din dreapta la abscisa "3rd Qu." (fie Q2); bara figurată în interiorul dreptunghiului are abscisa dată de mediana valorilor.
Liniile punctate care „prelungesc” dreptunghiul spre stânga şi spre dreapta se întind până la cea mai mare dintre valorile "Min." şi Q1-1.5*IRQ, respectiv până la min("Max.", Q3+1.5*IRQ) – unde IRQ este lungimea dreptunghiului (=Q3-Q1).
Valorile rămase în afară (cum este cazul valorii "Max.", reprezentate prin cerculeţul din dreapta ultimei gradaţii de pe graficul redat mai sus) sunt considerate „excepţii” faţă de tendinţa principală a distribuţiei datelor.
Vom elimina linia 10, constatând că "Bucureşti" este „excepţie” (sau "outlier"); pe de altă parte, "Iaşi" (pe linia 25) nu este un "outlier", dar are valoarea "Pop" foarte apropiată de limita dreaptă a "boxplot"-ului şi în plus, dacă ne uităm şi la coloana "Scl" – observăm aceeaşi situaţie de apropiere. Am spune atunci, că Bucureşti şi judeţul Iaşi sunt oarecum „excepţionale” în raport cu celelalte, atât ca "Pop" cât şi ca "Scl"; ignorându-le, se poate constata că pentru cele 40 de linii rămase obţinem un "boxplot" mai simetric (sau echilibrat), atât pentru "Pop" cât şi pentru "Scl".
Programul următor (lansat tastând source("work.R"), în sesiunea R curentă) produce scatterplot-ul redat dedesubt:
jPS2 <- jPS[-c(10,25), ] # exclude Bucureşti ("outliner") şi Iaşi with(jPS2, { plot(Scl ~ Pop, pch=19, cex=0.5, cex.axis=0.8, col="blue", xlab="Populaţie", ylab="Şcoli") text(Scl ~ Pop, labels=rownames(jPS2), cex=0.7, pos=3, offset=0.2) })
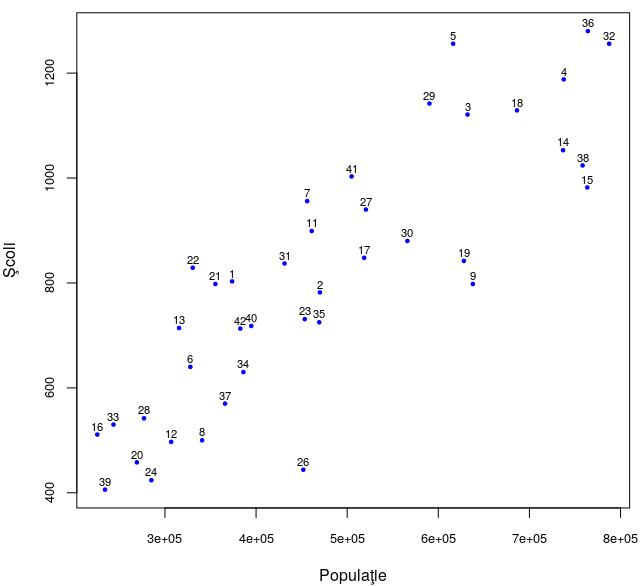
Cele 40 de judeţe reţinute în jPS2 sunt reprezentate prin puncte etichetate (prin funcţiile text() şi rownames()) cu rangul liniei corespunzătoare în jPS şi amplasate după valorile aferente lor din coloanele "Pop" şi "Scl" (dar nu cu aceeaşi unitate de măsură).
Uitându-ne pe verticală, sau pe orizontală, putem observa „discrepanţe” (mult mai uşor, decât exersam mai sus direct pe tabel); de exemplu, 19 şi 3 (adică Galaţi şi Argeş) au cam aceeaşi populaţie (punctele sunt cam pe o aceeaşi verticală, ceva mai la dreapta abscisei 6e+05=600000), dar diferă mult ca număr de şcoli (ordonatele punctelor fiind aproximativ 800 şi 1100); la fel 37 şi 1, sau 6 şi 22. Iar 7 (Botoşani) şi 15 (Constanţa) nu diferă mult pe verticală (adică au cam acelaşi număr de şcoli), dar diferă mult pe orizontală (ca populaţie); la fel de exemplu, 1 şi 9, etc. Avem şi perechi de judeţe apropiate şi ca "Pop" şi ca "Scl": 1 (Alba) şi 21 (Gorj), etc.
Dar să încercăm să vedem şi în ansamblu, „micşorând” cumva lucrurile (mai ales pe verticală, unde gradaţiile exprimă abia sute şi nu 105 cum avem pe orizontală) şi „netezind” sau ignorând unele asperităţi (precum punctul 26 (Ilfov) care este clar izolat, faţă de „norul” de deasupra lui):
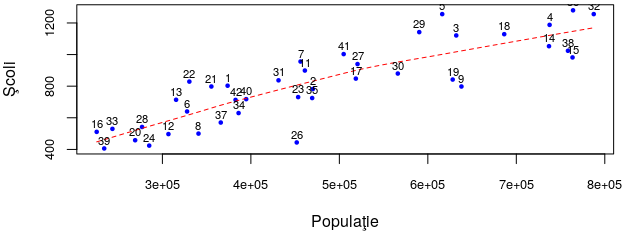
Linia roşie punctată sintetizează cumva „norul” punctelor (şi exprimă tendinţa principală a acestora), fiind obţinută printr-un proces de înlocuire din aproape în aproape a câte unui grup de puncte vecine prin câte un anumit punct considerat (în baza unui aceluiaşi algoritm de aproximare) ca reprezentativ pentru grup, unind apoi aceşti reprezentanţi; graficul este identic cu cel anterior, dar micşorat pe verticală (trăgând cu mouse-ul), iar linia roşie a fost calculată şi produsă înlocuind în programul redat mai sus funcţia plot() cu funcţia scatter.smooth().
În principiu, linia roşie este astfel calculată încât suma abaterilor pe verticală ale punctelor de deasupra liniei se compensează cu suma abaterilor de la linie ale punctelor aflate dedesubt (şi putem să ne dăm seama „din ochi” că „asperitatea” 26 semnalată mai sus contribuie totuşi la această compensare).
„Netezind” lucrurile şi mai mult, am zice că linia roşie este formată din două „drepte”; prima dreaptă merge până pe la punctul 27 (unde "Pop" este puţin peste 105), iar a doua continuă din acest punct şi are panta ceva mai mică decât prima. Interpretarea ar fi aceasta: până la 500000 de locuitori, "Scl" depinde liniar (crescător) de "Pop"; de la 500000 încolo, "Scl" depinde iarăşi liniar de "Pop", dar cu o rată de creştere ceva mai mică decât în primul caz.
Desigur, putem determina aproximativ pantele respective (raportând diferenţa de şcoli la diferenţa de populaţie, pentru câte două puncte suficient de apropiate de dreptele respective) – pentru a vedea dacă n-am greşi prea mult „unificând” cumva, cele două drepte – scurtând prin "Scl" depinde liniar de "Pop":
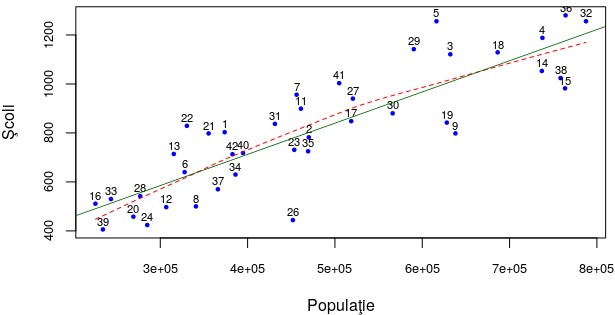
Aici, graficului anterior (dar acum, mărit puţin pe verticală) i-am adăugat dreapta colorată cu verde, care „unifică” cele două drepte roşii – ca şi cum am trage puţin de capetele fiecăreia, în direcţii contrare; „se vede” pe figură că abaterile celor două drepte roşii de la dreapta verde se compensează, deci dreapta verde „unifică” într-adevăr, cele două tendinţe.
Desigur, n-am „tras cu mouse-ul” (de capetele dreptelor roşii), ci am folosit funcţia lm(), prin care se constituie un „model liniar” pentru variabilele indicate:
vb@Home:~/20mar$ R -q > source("work.R") # produce scatterplot-ul > LM <- with(jPS2, lm(formula = Scl ~ Pop)) > abline(LM) # adaugă "dreapta verde" (dreapta de regresie LM)
Să vedem cât de acceptabil este acest model liniar:
> summary(LM) Residuals: Min 1Q Median 3Q Max -334.65 -90.48 14.40 104.84 267.91 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 2.031e+02 6.246e+01 3.252 0.00241 ** Pop 1.274e-03 1.237e-04 10.296 1.51e-12 *** --- Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 Residual standard error: 130.7 on 38 degrees of freedom Multiple R-squared: 0.7361, Adjusted R-squared: 0.7292 F-statistic: 106 on 1 and 38 DF, p-value: 1.507e-12
"Residuals" tabelează quartilele abaterilor verticale ale punctelor reale faţă de punctele de pe verticalele repective care sunt rezidente pe drepta de regresie; reziduurile pot fi plotate (toate) prin plot(jPS2$Pop, residuals(LM), ...); abline(0,0). Cea mai bună situaţie ar fi aceea în care "Min" şi "Max" n-ar diferi „prea mult” în valoare absolută şi "Median" ar fi cât mai mică (spre zero); cazul nostru parcă nu prea este în „cea mai bună” situaţie (dar plotând, vedem că totuşi, reziduurile par distribuite aleatoriu şi nu în jurul vreunei anumite curbe).
Tabelul "Coefficients" ne spune mai multe. De pe coloana "Estimate" avem ecuaţia Scl = 203.1 + 0.001274*Pop (dreapta de regresie); aceasta ne permite să estimăm cam câte şcoli s-ar potrivi pentru o anumită valoare "Pop" (care are sens: în mod firesc, "Pop" este de ordinul 105 sau cel puţin, de ordinul 104). De exemplu, pentru Pop=500000 am găsi Scl = 203+127.4*5 = 840 de şcoli (şi dacă ţinem cont de "St. error" – până la cel mult 840+"St. error"=840+62.46=900 şcoli, aproximativ).
Putem obţine direct estimarea de bază, prin funcţia predict(); de exemplu, pentru valorile "Pop" = k*105 (k de la 1 la 9):
> round(predict(LM, data.frame(Pop = (1:9)*100000))) 1 2 3 4 5 6 7 8 9 # *100000 (Pop) 330 458 585 713 840 967 1095 1222 1350 # estimare Scl (prin LM)
Pentru k=5 (adică Pop=500000) regăsim estimarea 840 pe care am calculat-o direct, mai sus.
Celelalte elemente din tabelele furnizate de summary() ("RSError", "R-squared", "p-value", etc.) măsoară acurateţea potrivirii datelor cu modelul "LM"; în principiu, cu cât "R-squared" este mai apropiat de 1 şi "p-value" este foarte mic – cu atât mai bună este estimarea asigurată de "LM" pentru dependenţa unei variabile faţă de cealaltă.
Ceva mai precis, fiindcă "p-value" este sub 0.001, iar "R-squared" este aproximativ 0.74 – putem zice că "Scl" depinde liniar de "Pop", dar numai circa 74% din variaţia variabilei "Scl" se explică liniar prin factorul "Pop"; restul de 26% trebuie „explicat” eventual prin alţi factori (de exemplu, prin forma de relief specifică judeţului).
vezi Cărţile mele (de programare)