În jurul unei probleme de echilibru (II)
În partea (I) am numit s-partiţie ("espartiţie") un cuplu ordonat (A, B) de submulţimi complementare ale mulţimii [n] = {1,2,...,n} pentru care diferenţa d(A, B) = s(A) - s(B) este nenegativă şi minimală.
Am stabilit că d(A,B) minim este 0 sau 1 (după cum n%4 este 0 sau 3, respectiv 1 sau 2) şi că in acest caz s(A) = (T(n) + d(A, B))/2, unde T(n) = n*(n+1)/2.
Aici vizăm generarea s-partiţiilor angajând metode generale: căutare "brute force" şi backtracking. Vom formula programe în C++ şi în Prolog (incluzând un mecanism intern de backtracking, Prolog permite "rezumarea" programului la specificarea condiţiilor necesare pentru soluţii).
Urmărirea exemplificărilor presupune instalarea interpretorului SWI-Prolog: în Ubuntu puteţi accesa meniul Applications/Ubuntu Software Center; tastaţi în caseta de căutare termenul swi-prolog
(există versiuni şi pentru Windows; dar instalaţi totuşi Ubuntu prin ubuntu/windows-installer: Windows-ul rămâne exact cum îl ştie fiecare şi nu este decât de câştigat).
Căutarea brute-force a s-partiţiilor (program în Prolog)
De fapt, am avea de enumerat numai părţile "A" din s-partiţii (dat fiind că B este complementara lui A faţă de [n]), astfel că problema se poate explicita şi astfel: se cer submulţimile A din [n] pentru care suma elementelor are valoarea s(A) menţionată mai sus (cu observaţia - vezi finalul părţii (I) - că dacă n%4 este 0 sau 3, atunci vor fi generate şi părţile "B", fiindcă în acest caz avem s(B) = s(A) şi deci odată cu s-partiţia (A, B) avem şi s-partiţia (B, A)).
"Brute-force" ar însemna: generează fiecare submulţime A a lui [n] şi testează s(A) (reţinând A, dacă s(A) are valoarea menţionată). În principiu, metoda este ineficientă ([n] are 2n submulţimi); dar este uşor de implementat, mai ales dacă limbajul respectiv oferă un anumit suport direct.
În Prolog mulţimile ordonate pot fi gestionate ca liste şi dispunem (în unele implementări) de termeni ca sublist, sumlist, reverse. Astfel, următorul program Prolog:
esparts(N) :- halfTrig(N, Suma), % Suma = (N*(N+1) + d(A, B)) / 4 numlist(1, N, L1n), % lista L1n = [1,2,...,N] /* generează fiecare sublistă X şi-i determină suma Y, afişând lista X dacă Y este egal cu Suma */ forall( ( sub_list(L1n, X), sumlist(X, Y) ), (Y =:= Suma, write(X), nl; !) ).
va lista s-partiţiile, presupunând însă că sunt definite predicatele implicate; unele dintre acestea (write şi nl ("new line")) sunt predefinite probabil în toate implementările uzuale de Prolog.
Regula p :- q, r, s. înseamnă: p este adevărat - sau, satisfăcut - dacă predicatele (sau clauzele) q, r, s sunt pe rând, adevărate (, corespunde conjuncţiei logice: p implică q^r^s).
Variabilele încep cu majusculă (sau _) şi sunt interpretate ca "placeholders" (ţin loc pentru valori); interpretorul caută valori potrivite pentru a satisface predicatul în care apar "necunoscutele" respective.
Pentru programul de mai sus: esparts(N) este satisfăcut dacă există o valoare pentru variabila Suma încât halfTrig(N, Suma) să fie satisfăcut şi apoi o valoare pentru variabila L1N încât numlist(1, N, L1N) să fie adevărat şi predicatul forall(...) să fie satisfăcut pentru valorile respective.
Aici vizăm interpretorul swi-prolog. Predicatul forall(:Condition, :Action) determină rând pe rând variantele descrise de "Condition" şi aplică asupra fiecăreia "Action" (în GNU Prolog se poate folosi asemănător findall/3, cu trei argumente). Predicatele sumlist şi numlist sunt deasemenea predefinite în swi-prolog; însă (în cazul swi-prolog) sub_list trebuie definit "din afară" (dar această definiţie este "clasică", prezentă cam în orice manual de Prolog):
% lista vidă este sublistă a listei vide: sub_list([], []). /* o listă care începe cu First este sublistă a uneia care începe tot cu First dacă Restul primeia este sublistă a restului Sub al celei de-a doua: */ sub_list([First|Rest], [First|Sub]) :- sub_list(Rest, Sub). /* indiferent cu ce începe, o listă este sublistă a listei Sub dacă Restul primeia este sublistă a lui Sub: */ sub_list([_|Rest], Sub) :- sub_list(Rest, Sub).
Mai trebuie specificat calculul sumei s(A) = (T(n) + d(A, B))/2, unde T(n) = n*(n+1)/2 şi d(A, B) este 0 sau 1 în dependenţă de valoarea lui n modulo 4:
halfTrig(N, Suma) :- R is N mod 4, ( R =\= 0, R =\= 3 -> Suma is (N * (N + 1) +2) / 4 ; Suma is N * (N + 1) / 4 ).
Construcţia (p -> q ; r) corespunde cu "IF p THEN q ELSE r".
Constituim fişierul espart.pl, cuprinzând definiţiile redate mai sus şi-l transmitem interpretorului swi-prolog (lansat din directorul care conţine fişierul respectiv):
vb@vb:~/docere/doc/Prolog$ swipl -q -s espart.pl ?-
opţiunea -q ("quiet") a inhibat afişarea mesajului informativ iniţial, specific SWI Prolog
Putem revedea întregul program invocând listing:
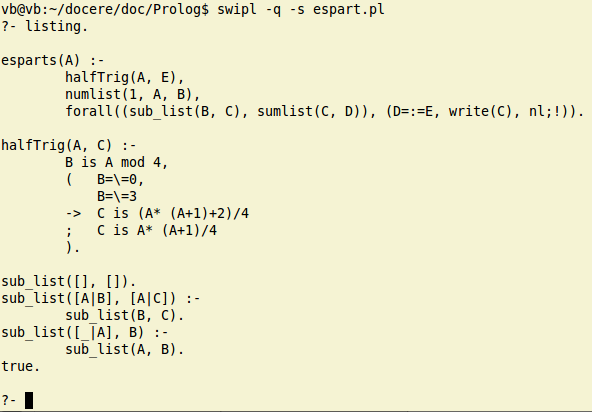
În listingul furnizat astfel, denumirile de variabile corespund reprezentării interne (de exemplu, variabilele First|Rest din fişierul "espart.pl" apar ca A|B). Variabilele sunt localizate predicatului în care apar (variabila A dintr-un predicat nu are nicio legătură cu variabila A dintr-un alt predicat).

Putem testa fiecare predicat în parte; de exemplu, la ?- tastăm sub_list([1,2,3], X). obţinând rând pe rând - tastând intermediar ; - sublistele listei [1,2,3]).
În imaginea alăturată este redat rezultatul invocării espart(8)., adică s-partiţiile pentru n = 8 (mai precis - părţile "A" ale s-partiţiilor), în număr de 14 (ele apar în ordine lexicografică fiindcă lista iniţială este ordonată crescător şi sub_list produce sublistele în ordine lexicografică).
În partea (I) am remarcat în final, că în cazul când n%4 este 0 sau 3, ar fi suficientă enumerarea numai a părţilor "A" care conţin valoarea n (orice parte care nu conţine n este complementara uneia care conţine n, fiind deci partea "B" a acesteia). În plus, am schiţat acolo un algoritm incremental pentru enumerarea s-partiţiilor într-o anumită ordine (implicând liste ordonate descrescător).
Putem modifica în acest sens, predicatul esparts - implicând predicatele predefinite reverse(L1, L2) care produce în L2 inversa listei L1 şi member(Elem, Lista) pentru testarea apartenenţei unui element la o listă:

esparts(N) :- halfTrig(N, S), % S = (N*(N+1) + d(A, B)) / 4 numlist(1, N, L1n), % rezultă lista L1n = [1,2,...,N] reverse(L1n, L), % L = [N,...,2,1] forall( ( sub_list(L, X), % X este sublistă a lui L şi member(N, X), % sublista X conţine N sumlist(X, Y) ), (Y=:=S, write(X), nl; !) ).
Reîncărcând "espart.pl" (invocând la ?- "prescurtarea" [espart].), obţinem acum numai cele 7 s-partiţii care "încep" cu 8 şi anume, în ordinea dată de aplicarea algoritmului incremental menţionat (vezi imaginea alăturată).
Desigur - de regulă, pentru metoda "brute-force" - trebuie folosite valori mici pentru n. Astfel, esparts(20). va furniza în mai puţin de 10 secunde, cele 7636 s-partiţii (din totalul de 15272 calculat în partea (I)), începând cu [20,19,18,17,16,15] şi încheind cu [20,13,12,11,10,9,8,7,5,4,3,2,1]; ceva mai mult durează esparts(24)., când enumerarea este mult mai lungă (187692 / 2 s-partiţii care încep cu 24). Dar incepând de pe la n=32 (când enumerarea ar cuprinde 31592878 / 2 liste) programul îşi pierde practic sensul, din cauza duratei.
Generarea backtracking a s-partiţiilor
Ineficienţa (semnalată concret şi mai sus) este inerentă metodei "brute-force". Dar de fapt, abordarea de mai sus - bazată pe liste de numere - este nenaturală (cel puţin, pentru C++): în fond se dă un număr n (şi nu lista [n]) şi se cer anumite numere (distincte şi mai mici ca n) care însumează o anumită valoare - prin urmare, firesc ar fi să angajăm numere ca atare şi nicidecum submulţimi!
În loc să căutăm submulţimi A pentru care s(A) să aibă valoarea prestabilită (cum am procedat mai sus) poate fi (este?) mai convenabil să completăm secvenţial o s-partiţie.
Un număr (cel mult egal cu n) se va putea plasa pe rangul curent dacă este diferit de cele existente pe rangurile anterioare şi dacă suma rămasă apoi de completat este încă nenegativă; putem simplifica implicit testul de "diferit", prevăzând de la început o anumită ordine a numerelor care trebuie plasate.
Când suma rămasă devine zero - am obţinut o soluţie; dacă suma rămasă este strict pozitivă, atunci putem viza rangul următor din s-partiţie (aplicând şi pe acest loc, operaţia de plasare descrisă).
Dacă "suma rămasă" devine negativă, atunci este clar că numărul pe care tocmai am încercat să-l plasăm pe rangul curent este prea mare; dacă putem alege un număr mai mic, atunci reluăm operaţia de plasare pentru acesta - altfel, trebuie să revenim la rangul precedent celuia pe care operaţia de plasare tocmai a eşuat şi să încercăm o altă valoare în locul celeia existente deja.
Ceea ce am descris mai sus este desigur metoda backtracking - mai precis, backtracking cronologic: după epuizarea variantelor pentru nivelul curent, căutarea continuă cu variantele rămase pentru nivelul precedent celui curent (chiar dacă acestea ar fi de ignorat şi ar fi necesară abordarea directă a unui nivel mai vechi, "tăind" dintr-o dată nivelele intermediare).
- în C++
O realizare în C++ poate fi următorul program:
#include <iostream> using namespace std; int n, *Part = 0; void scrie(int); void solve(int, int); int main() { cout << "n = "; cin >> n; cout << '\n'; int r = n % 4; int sumA = (r == 1 || r == 2) ? (n * (n + 1) + 2) / 4 : n * (n + 1) / 4; Part = new int[n]; Part[0] = n + 1; solve(1, sumA); } void solve(int depth, int suma) { for(int num = n; num; num--) { if(Part[depth - 1] > num) { Part[depth] = num; if(suma == num) scrie(depth); else { if(suma > num) solve(depth + 1, suma - num); } } } } void scrie(int h) { for(int i = 1; i <= h; i++) cout << Part[i] << " "; cout << '\n'; }
Observaţii
1) Pentru s-partiţii am prevăzut prin Part = new int[n]; câte n locaţii. Dar cât de multe elemente poate avea partea "A" dintr-o s-partiţie? Cea mai lungă parte A s-ar obţine însumând primele cele mai mici k numere, iar din k(k+1)/2 ≤ s(A) rezultă k ≤ (sqrt(8*s(A) + 1) - 1)/2, valoare care pentru s(A) = (n(n+1) + 2)/4 revine la (sqrt(2*n2 + 2*n + 5) - 1) / 2. Raportul dintre această ultimă valoare şi n are limita sqrt(2)/2 (şi funcţia reală asociată este crescătoare), încât concluzionăm că s-partiţia maximală (în privinţa lungimii părţii A) are cel mult [0.7*n] + 1 elemente.
2) solve(1, sumaA) completează tabloul Part[] începând de la rangul 1, fiind apelată după fixarea pe rangul 0 a unei valori mai mari ca n (prin Part[0] = n + 1;). Procedând aşa, ne asigurăm că Part[0] > Part[1] şi putem parcurge valorile descrescător (de la n spre 1) folosind un test unitar de evitare a repetării: if(Part[depth - 1] > num) acoperă inclusiv cazul depth=1 (dacă alegeam să completăm începând de la rangul 0, am fi fost obligaţi să testăm separat valoarea de pe rangul 0).
Compilăm programul de mai sus "espart.cpp", folosind opţiunea de optimizare a codului -O3 (optimizările posibile se pot afişa prin g++ --help=optimizers):
vb@vb:~/docere/doc/Prolog$ g++ -O3 -o espart espart.cpp
Testând funcţionarea programului pentru diverse valori n (lansăm prin ./espart şi indicăm n), vedem că afişarea s-partiţiilor începe instantaneu, chiar şi de exemplu pentru n = 100; dar trebuie să ne dăm seama că derularea soluţiilor poate continua "la nesfârşit": în partea (I) am văzut că deja pentru n = 72, numărul de s-partiţii este uriaş.
Dacă ne mulţumim cu s-partiţiile afişate până la un moment dat, atunci putem întrerupe execuţia programului (folosind combinaţia de două taste CTRL şi C). Dacă vrem să obţinem un fişier conţinând toate s-partiţiile pentru un anumit n, putem "redirecţiona" ieşirea; pentru un exemplu didactic ("didactic", fiindcă altfel considerăm absurd să avem nevoie vreodată de toate soluţiile, aproape indiferent de problema pusă) - să considerăm n = 32:
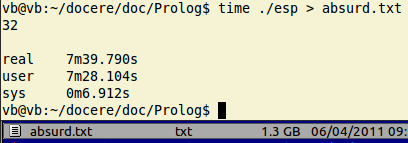
Am rulat programul sub time, obţinând un sumar al resurselor utilizate; vedem că execuţia a durat peste 7 minute (precizăm că iniţial, am compilat fără optimizările -O3 şi durata a fost de peste 10 minute - ceea ce atestă importanţa folosirii opţiunilor de optimizare a codului).
La baza imaginii de mai sus am redat o porţiune din fereastra Gnome Commander, pe care am urmărit pe parcursul execuţiei programului cum creşte fişierul "absurd.txt": în câteva secunde după ce am tastat 32 deja fişierul depăşise 100MB, iar în circa un minut ajunsese la 400MB.
În final, vedem că "absurd.txt" măsoară 1.3GB… Parcă nu ne vine să credem, dar putem calcula, servindu-ne desigur şi de unele programe utilitare generale: wc ("word count" - numără rândurile, cuvintele, octeţii dintr-un fişier), less (încarcă porţiuni din fişier şi afişează câte o pagină de conţinut), tail (afişează ultimele rânduri din fişier).
Pentru n=32 există 31,592,878 s-partiţii (vezi programul din partea (I)); putem verifica:
vb@vb:~/docere/doc/Prolog$ wc -l absurd.txt 31592879 absurd.txt
(cu 1 mai mult, din cauza cout << "n = ") din prima linie a lui main())
Cea mai scurtă dintre acestea este [32 31 30 29 28 27 26 25 24 12] (putem vedea prima pagină din fişier folosind less absurd.txt; după listarea ei, tastăm q pentru a nu mai lista şi paginile următoare); cea mai lungă este ultima înscrisă în fişier (având în vedere că în mod implicit, s-partiţiile au fost generate în ordine lexicografică descrescătoare) şi o putem vedea folosind tail absurd.txt: ea conţine toate numerele de la 23 spre 1 cu excepţia numărului 12.
Putem accepta atunci că în medie, rândurile înscrise în "absurd.txt" conţin 15 sau 16 numere. Înmulţind cu numărul s-partiţiilor obţinem că avem înscrise în jur de 500,000,000 numere; altfel:
vb@vb:~/docere/doc/Prolog$ wc -w absurd.txt 505486050 absurd.txt
(va dura vreun minut, dar rezultatul este exact totalul de numere din fişier)
Doar aproape jumătate, din dimensiunea de 1.3GB; dar, mai întâi să observăm că valoarea afişată mai sus prin wc -w mai spune şi că există cam tot atâtea spaţii înscrise în fişier (pentru că orice "word" este separat cu spaţiu de următorul "word") - ceea ce conduce deja foarte aproape de 1 GB.
Pentru a completa justificarea dimensiunii de 1.3 GB a fişierului rezultat, mai trebuie doar să ţinem seama de faptul că în "absurd.txt" numerele respective sunt reprezentate prin codurile ASCII ale cifrelor zecimale respective - deci fiecare valoare 10..32 este înscrisă pe câte două caractere.
- în Prolog
Abordând chestiunea - sau programul, sau un subprogram - şi într-un alt limbaj, putem eventual să evidenţiem mai uşor unele aspecte, sau chiar să vedem nuanţe neobservate iniţial.
Deocamdată, imităm programul C++ de mai sus prin următoarea formulare Prolog :
espart1(N) :- % prima versiune (pentru predicatul parts) halfTrig(N, Suma_initiala), % Suma_initiala = (N*(N+1) + d(A, B)) / 4 parts(N, [0], Suma_initiala). % , !. (pentru stop după prima soluţie) parts(N, Part, Suma_curenta) :- between(1, N, Numar_de_inclus), Part = [Ultim_inclus | _], Ultim_inclus < Numar_de_inclus, ( Suma_curenta =:= Numar_de_inclus -> scrie([Numar_de_inclus | Part]) ; Suma_curenta > Numar_de_inclus, Suma_ramasa is Suma_curenta - Numar_de_inclus, parts(N, [Numar_de_inclus | Part], Suma_ramasa) ). scrie(Result) :- delete(Result, 0, Part), writeln(Part).
between(1, N, Numar) corespunde pe parcursul execuţiei cu for(Numar=1; Numar ≤ N; Numar ++) din programul C++; diferenţa este că acum numerele vor fi parcurse crescător - şi ca urmare, pe "rangul 0" am plasat 0 - nu "n+1" ca în programul C++ - şi am inversat comparaţia dintre Numărul_de_inclus şi Ultimul_inclus în s-partiţie.
Definiţiile de mai sus (pentru predicatele espart1 şi parts) pot fi adăugate în fişierul "espart.pl" creat anterior (unde am definit şi "halfTrig"). Lansăm swi-prolog încărcând "espart.pl" şi exemplificăm:
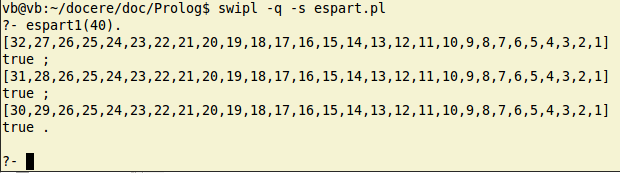
Mesajul "true" după fiecare soluţie afişată, spune că "există şi alte soluţii"; dacă se tastează ; atunci interpretorul va continua execuţia programului din ultimul punct în care există alternative (producând astfel o nouă soluţie); dacă se tastează ENTER (sau .), atunci execuţia va fi încheiată.
Probând pentru unele valori n, constatăm că prima soluţie rezultă instantaneu chiar şi pentru valori n ca 100, 200, sau 400; pentru n = 600 execuţia durează sub două secunde. Pentru n = 1000, rezultatul nu este furnizat nici după 3 minute.
Este "ciudat" însă, că pentru n = 300 (caz în care ne aşteptam ca timpul să fie inferior celui pentru n = 600) timpul este de aproape 15 secunde… Aceasta înseamnă că lucrurile depind nu doar de mărimea lui n, dar şi de anumite proprietăţi ale numărului n.
Predicatul predefinit profile furnizează statistici asupra execuţiei (numărul de apeluri, timp, etc.). Să vizăm numai prima soluţie; pentru aceasta este suficient să adăugăm ! (predicatul "cut") în linia a doua din definiţia predicatului "espart1": parts(N, [0], Suma_initiala), !. ("taie" punctele de revenire anterioare, încât execuţia se încheie odată cu găsirea primei soluţii).
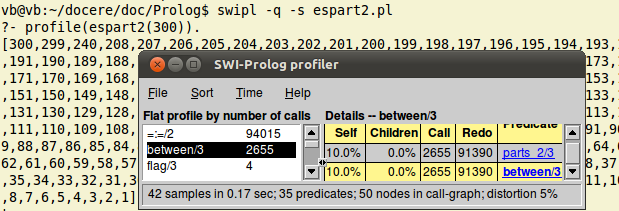
Reîncărcând programul modificat astfel şi invocând profile(espart1(300)) obţinem:
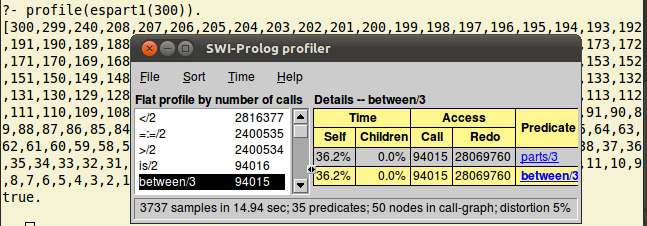
şi vedem că parts este accesat de un număr impresionant de ori (în cadrul a circa 15 secunde).
Ce proprietăţi ale numărului n fac ca durata execuţiei pentru n = 300 să fie de 9 ori mai mare, decât pentru n = 600? Unde am avea de modificat predicatul parts, pentru a ţine seama de aceste proprietăţi şi a diminua durata?
Putem urmări execuţia programului, de exemplu folosind spy(parts) ("pândeşte" accesarea predicatului "parts" şi implicit, activează trasarea execuţiei):
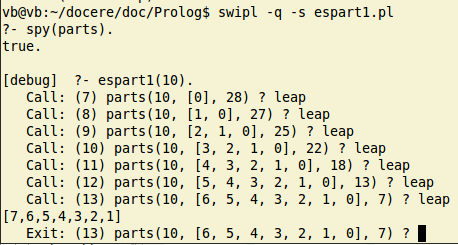
Am tastat mereu l ("leap": continuă tacit execuţia, stopând la următoarea accesare a predicatului "pândit"), pentru a evidenţia întâi cum este completată lista Part. Cum se mai poate vedea şi pe textul programului, Part este iniţial lista [0] (cu Suma_curenta 28), apoi este [1,0] (şi Suma_curenta devine 27), etc. Part este completată "în faţă", adăugând după valoarea iniţială 0 valoarea 1, apoi adăugând 2, 3, etc. şi în acelaşi timp diminuând corespunzător "suma_curentă"; când Suma_curenta ajunge 7 (egală acum, cu Numar_de_inclus), se afişează soluţia găsită (desigur, fără 0 iniţial).
Să privim acum şi rezultatul redat mai sus pentru espart1(40) (prima soluţie) şi să ne imaginăm execuţia din momentul când s-a găsit Part = [1,2,3,...,26,27] (citind invers lista respectivă). "Suma_curentă" rezultată în acest moment este 32, iar următorul "număr_de_inclus" va fi 28; rezultă 32-28=4 pentru Suma_ramasa şi se lansează parts(40, [28 | 27,26,...,2,1,0], 4) - between() va genera pe rând 1,2,...,28 (respinse fiecare de testul Ultim_inclus < Numar_de_inclus), apoi pentru 29 va urma reapelul parts(40, [29 | 27,...,2,1,0], 3), ş.a.m.d.
Analog, pentru n = 300 (vezi mai sus rezultatul pentru espart1(300)): după ce se completează Part = [1,2,..., 207,208] se vor respinge (dar reapelând de fiecare dată "parts") valorile 209,...,239 şi apoi, după ce se adaugă 240 se vor respinge la fel valorile 241,...,298, etc.
Ne dăm seama acum, că dacă "suma_rămasă" este mai mică decât "numărul_de_inclus", atunci doar ar trebui să revenim la between() pentru a obţine următorul "număr_de_inclus" (diminuând dintr-o dată "suma_rămasă", fără a repeta pentru aceasta tot parcursul parts()).
Pe de altă parte - în imaginea redată mai sus pentru profile(espart1(300)) vedem că numărul Redo (de generări alternative) pentru predicatul between este unul uriaş… În parts avem between(1, N, Numar_de_inclus) - dar este clar că "număr_de_inclus" trebuie să fie mereu unul mai mare decât precedentul inclus în Part (şi este inutilă generarea şi a numerelor inferioare ultimului inclus).
Ţinând cont de aceste două aspecte, obţinem următoarea versiune:
espart2(N) :- % a doua versiune (parts_2) halfTrig(N, Suma_initiala), parts_2(N, [0], Suma_initiala), !. % "cut" după prima soluţie parts_2(N, Part, Suma_curenta) :- Part = [Ultim_inclus | _], Minim is Ultim_inclus + 1, between(Minim, N, Numar_de_inclus), Ultim_inclus < Numar_de_inclus, ( Suma_curenta =:= Numar_de_inclus -> scrie([Numar_de_inclus | Part]) ; Suma_curenta > Numar_de_inclus, Suma_ramasa is Suma_curenta - Numar_de_inclus, ( Suma_ramasa > Numar_de_inclus -> parts_2(N, [Numar_de_inclus | Part], Suma_ramasa) ) ).
În această variantă, "parts" (acum parts_2) va fi reapelată numai dacă "suma_rămasă" este mai mare decât "numărul_de_inclus" (altfel, se va relua between(), obţinând direct următorul "număr de inclus"); iar between furnizează numerele posibil de adăugat începând cu succesorul ultimului număr inclus în Part (şi nu începând tocmai de la 1).
Acum, cazul n = 300 durează sub o secundă (faţă de 15 secunde în prima variantă; iar "Redo" este acum de peste 300 de ori mai mic):
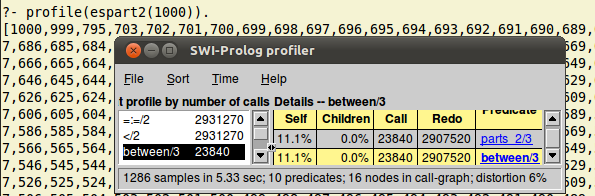
Cazul n = 1000 dura pare-mi-se, mai mult de 3 minute în prima versiune; acum şi acesta poate fi rezolvat, chiar sub 6 secunde:
Să nu neglijăm totuşi, o umbră de îndoială: programul voia să genereze toate s-partiţiile, iar mai sus poate să pară că am vizat prima soluţie; nu cumva, argumentele pe care am bazat modificările făcute în "espart2" ţin totuşi (în ascuns) numai de generarea primei soluţii?
Dacă vrem, putem vedea şi toate soluţiile generate. Ar fi suficient să eliminăm "cut"-ul prevăzut iniţial în linia a doua din "espart2", înlocuind , !. cu .; dar astfel, interpretorul va afişa o soluţie şi apoi va aştepta să tastăm ;, pentru a relansa căutarea următoarei soluţii.
O metodă mai potrivită aici, constă în a invoca în final fail:
parts_2(N, [0], Suma_initiala), fail.
fail obligă interpretorul să accepte că răspunsul găsit nu satisface; interpretorul va relansa automat "parts_2" (până ce epuizează alternativele) şi astfel, vor fi afişate consecutiv toate soluţiile.
Dar în loc să generăm toate soluţiile pentru a vedea dacă într-adevăr sunt toate, ar fi normal să le contorizăm (fără a le mai afişa); dacă numărul rezultat (pentru diverse valori n) este cel corect (vezi partea (I)), atunci putem fi siguri că programul generează corect toate soluţiile.
În programul C++ redat la început este foarte simplu de contorizat soluţiile, în loc de a le afişa: se elimină funcţia scrie() şi se foloseşte if(suma == num) count++;, unde variabila "count" trebuie declarată global, iniţializată cu zero şi desigur, va fi afişată în final.
În Prolog însă, variabilele sunt tratate ca "placeholders", în interiorul predicatului; interpretorul încearcă să găsească - şi foloseşte backtracking pentru aceasta - valori pentru ele care să satisfacă întregul predicat care le conţine. Nu există "atribuire" şi nici variabile "globale" (decât cu demersuri speciale, variind de la o implementare la alta).
În Introducere practică în Prolog tratăm şi metoda clasică pentru Prolog de contorizare a soluţiilor unei probleme (folosind direct, assert şi retract) şi revenim acolo, asupra "espart2".
vezi Cărţile mele (de programare)