Centralitatea nodurilor și colorarea "greedy"
Cel mai simplu algoritm care ne dă o colorare a vârfurilor unui graf (vârfurile adiacente trebuind să aibă culori diferite) este unul secvențial: colorăm unul după altul fiecare vârf, cu prima culoare disponibilă în momentul respectiv. Inițial, culorile ar fi în număr egal cu numărul de vârfuri; în final, numărul de culori aplicate vârfurilor este cel mult Δ+1, unde Δ este gradul maxim al vârfurilor.
Obținerea unei colorări optime (cu număr minim posibil de culori) depinde de ordinea în care abordăm vârfurile; în principiu – dar fără a garanta că se va ajunge la o colorare optimă – avem două posibilități: fie ne bazăm pe o ordine prestabilită (de exemplu, după grade), fie adoptăm un criteriu de alegere dinamică a următorului nod de colorat, în funcție de caracteristicile colorării parțiale curente. De exemplu, în funcția (din pachetul igraph)
igraph::greedy_vertex_coloring(graph, heuristic = c("colored_neighbors"))
se alege la fiecare pas vârful cu cel mai mare număr de adiacenți deja colorați; pot fi mai multe vârfuri în această situație și atunci se alege la întâmplare, unul dintre acestea – ceea ce explică într-o anumită măsură, faptul că, în general, nu se ajunge la o colorare optimă.
greedy_vertex_coloring() nu presupune vreo ordonare prealabilă a vârfurilor; dar este de subliniat că și în cazul alegerii dinamice a următorului vârf, tot este importantă ordonarea prealabilă „cât mai bună” a nodurilor.
Grafuri versus rețele
În „teoria grafurilor” (cu istorie de peste 300 de ani), termenii standard sunt graf, vârf, muchie, arc; cam pentru aceleași lucruri, în „știința rețelelor” avem ca termeni comuni pentru studiul sistemelor complexe subiacente unor diverse realități, rețea, nod și link.
Când graful cu care avem de-a face vine dintr-o anumită realitate (de exemplu, în [1] și [2] am considerat grafuri asociate încadrării profesorilor pe obiecte și clase), se preferă termenii rețelelor (beneficiind implicit de anumiți coeficienți structurali consfințiți de știința rețelelor).
Network science a plecat acum vreo 70 de ani de la cercetări sociologice, a fost pregătită de studiile matematice (ale lui Erdős și Rényi) asupra grafurilor aleatorii, a fost impulsionată prin anii '80–90 (în urma creșterii puterii de calcul și a constituirii unor instrumente software adecvate) de investigații statistice efectuate în diverse domenii (fizica statistică, microbiologie, medicină, infrastructuri de comunicație, etc.) și s-a consolidat cam prin 2000 ca știință interdisciplinară de sine stătătoare (iar în ultimii vreo 10 ani multe universități au înființat la diverse specializări existente (chiar și la "jurnalism"), cursuri de "Network science").
Între altele, a apărut în mod firesc necesitatea de a măsura cumva „importanța” indivizilor dintr-o rețea; de exemplu betweenness() apreciază mai mult nodurile care apar ca „punți” între cât mai multe alte noduri (altfel spus – după numărul de geodezice ale grafului care trec prin nodul respectiv); eigen_centrality() măsoară importanța nodului cumva recursiv – după importanța nodurilor cu care este legat (fiind cu atât mai important cu cât are legături cu mai multe noduri importante). Pentru un alt exemplu, PageRank măsoară importanța nodurilor din rețeaua World Wide Web, constituită din pagini HTML (în număr de ordinul trilioanelor) legate prin URL-uri (care permit „navigarea” prin click de la un document la altul); bineînțeles că analiza unei rețele așa de vaste impune (dar este obișnuit în știința rețelelor) utilizarea conceptelor și metodelor din statistica matematică.
În [1] am arătat deja că alocând pe orele zilei lecțiile prof|cls (din ziua curentă), în ordinea dată de coeficienții "betweenness" dintr-un anumit graf asociat acestor lecții – putem obține mult mai sigur și mai rapid un orar al zilei, decât dacă am fi respectat ordinea obișnuită (dată de numărul de ore, crescător sau descrescător).
Colorarea "greedy" în ordinea dată de centralitățile nodurilor
Măsurile de centralitate apărute reflectă mai bine structura internă a rețelei, decât o poate face clasificarea (obișnuită) după gradele nodurilor. Este de așteptat (exceptând cazul când nodurile au centralități egale) ca rezultatul colorării să fie mai bun dacă abordăm nodurile în ordinea descrescătoare a centralităților, decât dacă le-am aborda în ordinea descrescătoare a gradelor, sau dacă le-am aborda dinamic dar fără a presupune vreo ordine inițială.
Considerăm un graf (sau mai bine, o rețea) G – obiect IGRAPH. Atașăm nodurilor proprietatea $centr, indicând centralitatea fiecăruia (preferăm eigen_centrality(), dar putem înlocui de exemplu cu betweenness()); le atașăm deasemenea, proprietatea $color cu valoarea inițială 0. Apoi, în ordinea dată de $centr, aplicăm nodurilor o colorare "greedy": dintre culorile posibile Col=1:gorder(G), selectăm pentru nodul curent pe cea mai mică dintre cele neaplicate încă adiacenților acestuia. În final returnăm G, astfel colorat:
library(tidyverse) library(igraph) "%Nin%" <- Negate("%in%") greedy_color_by_centrality <- function(G) { V(G)$centr <- eigen_centrality(G)$vector V(G)$color <- 0 Col <- 1:gorder(G) Nodes <- sort(V(G)$centr, decreasing=TRUE, index.return=TRUE)[["ix"]] lapply(Nodes, function(i) V(G)$color[i] <<- Col[Col %Nin% sapply(neighbors(G, i), function(j) V(G)$color[j])] %>% min() ) G }
Subliniem că a trebuit să folosim "<<-" (operatorul de „atribuire globală”) în loc de atribuirea obișnuită "<-", fiindcă V(G) este în exteriorul funcției anonime implicate mai sus în lapply().
Precizăm că într-un obiect IGRAPH vârfurile sunt fixate intern prin indecșii 1:gorder(G) și nu poate fi vorba de „reordonarea” acestora (decât în sensul că putem constitui un nou graf, în care noile vârfuri 1:gorder(G) să constituie de fapt o permutare a celor inițiale – distingând pe cele vechi față de cele noi prin setarea corespunzătoare a proprietății V(G)$name).
De aceea, pentru a parcurge nodurile în ordinea descrescătoare a centralităților, am introdus mai sus vectorul Nodes; folosind sort() cu opțiunea importantă (dar în general, ignorată) index.return, am rezolvat direct o chestiune care în multe locuri este tratată elegant, dar întortochiat: se constituie un data.frame cu o coloană pentru valorile 1:gorder(G) și una pentru centralitățile corespunzătoare; se ordonează tabelul după valorile din coloana a doua și se furnizează vectorul rezultat în prima coloană (problema generală fiind aceasta: cum ordonezi un vector dat, după valorile descrescătoare existente într-o ordine oarecare într-un alt vector, de o aceeași lungime).
Mai trebuie luat seama la acest aspect: dacă mai multe noduri au aceeași centralitate, atunci sort() le va aranja (în mod implicit) într-o ordine aleatorie; deci (ca și pentru greedy_vertex_coloring()) se poate ca rezultatul colorării să difere de la o execuție la alta. Totuși, vom avea mai puține cazuri de „egalitate” a centralităților, decât de egalitate a gradelor – dat fiind modul de reprezentare internă a unora și altora (două valori de centralitate cu aceeași parte întreagă și în care primele 7 zecimale sunt identice nu sunt neapărat, egale).
Testare
Să confruntăm igraph::greedy_vertex_coloring() și greedy_color_by_centrality() de mai sus – deocamdată pentru setul de 1252 de grafuri cu cel mult 7 vârfuri, furnizat de igraph::graph_from_atlas() (dar fiind așa puține vârfuri, nu ne așteptăm la ceva „spectaculos”):
DF <- map_dfr(1:1252, function(n) { G <- graph_from_atlas(n) l1 <- greedy_vertex_coloring(G) %>% unique() %>% length() G1 <- greedy_color_by_centrality(G) l2 <- V(G1)$color %>% unique() %>% length() if(l1 != l2) data.frame(n = n, igraph = l1, centr = l2) }) print(DF) # lungimea colorării, când diferă prin prima și a doua funcție n igraph centr 1 105 2 3 2 860 4 3 3 862 3 4 4 863 4 3 5 868 4 3 6 875 3 4 7 960 4 3 8 980 4 3 9 997 3 4 10 1003 4 3
În marea majoritate a cazurilor, colorările furnizate de cele două funcții au același număr de culori; dacă repetăm execuția secvenței de testare de mai sus, putem obține de exemplu 16 excepții (în loc de cele 10 redate mai sus), în care sau prima sau a doua colorare este mai bună decât cealaltă.
Pentru a testa pe grafuri mai complexe ca număr de noduri și de muchii putem angaja grafuri generate aleatoriu (de exemplu, prin sample_gnm() etc. din igraph), sau putem folosi de exemplu bazele de date de la houseofgraphs:
A <- read.table("graph_1257.mat", sep=" ") %>% # v. https://houseofgraphs.org as.matrix() G <- graph_from_adjacency_matrix(A, mode="undirected") %>% greedy_color_by_centrality() print(V(G)$color %>% unique()) # [1] 1 2 3 print(greedy_vertex_coloring(G) %>% unique()) # [1] 1 3 2 4 coords <- layout_with_dh(G) plot(G, layout = coords, vertex.size = 5, vertex.label="", vertex.frame.color="#ffffff")
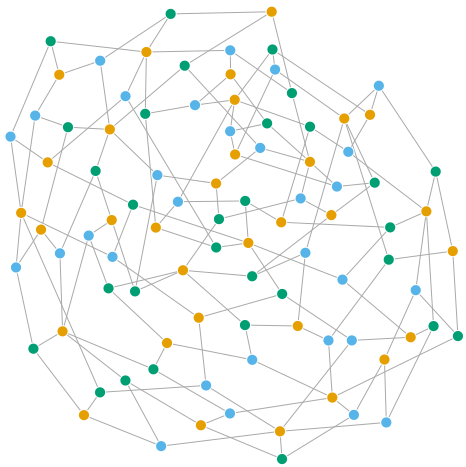
G are 92 de vârfuri (cu gradul între 3 și 5) și 150 de muchii; greedy_color_by_centrality() ne-a dat o colorare optimă (cu 3 culori, cât și este numărul cromatic al grafului 1257), în schimb greedy_vertex_coloring() ne-a dat 4 culori – și această situație s-a păstrat în mai multe repetări ale secvenței de mai sus (am încercat mai multe funcții layout_(); bineînțeles că n-am găsit și una care să țină seama de faptul că graful 1257 este un graf planar, deci ar putea fi reprezentat grafic încât să nu apară intersecții de muchii).
Am redat aici și poza – deși nu are nicio semnificație – pentru a vizualiza faptul că vârfurile adiacente au culori distincte (fiind 32, 30, 30 pe câte o aceeași culoare).
Aplicație: constituirea orarului pe ziua curentă
Într-o anumită școală sunt prevăzute 1260 de lecții săptămânale prof|cls; sunt 83 de profesori, codificați după disciplinele principale (abreviate prin una sau două litere), plus 26 de cuplaje (de exemplu, "Ge1Ge2" acoperă lecțiile de „Germană” desfășurate împreună – pe grupe ale claselor respective – de către "Ge1" și "Ge2") și sunt 42 de clase.
Prin programul by_days.R din [1] am obținut o repartizare pe zile a celor 1260 de lecții, care este echilibrată: în fiecare zi sunt 252 de lecții, lecțiile fiecărui profesor și ale fiecărei clase sunt distribuite uniform pe zile și – cu unele excepții firești – niciun obiect nu apare într-o aceeași zi, de două ori la o aceeași clasă.
LSS <- readRDS("../22oct/R12_ldz.RDS") # listă Zi ==> lecțiile prof|cls ale zilei Zile <- names(LSS) # Lu, Ma, Mi, Jo, Vi
Următoarea funcție furnizează (ca obiect IGRAPH) graful lecțiilor unei zile, două lecții fiind legate dacă aparțin unui aceluiași profesor, sau unei aceleiași clase (deci nu vor putea fi alocate (exceptând anumite cuplaje) într-o aceeași oră 1..7 a zilei):
graph_ore <- function(zi) { LS <- LSS[[zi]] # lecțiile prof|cls ale zilei curente n <- nrow(LS) A <- matrix(rep(0L, n*n), nrow = n, byrow = TRUE) for(i in 1:(n-1)) for(j in (i+1):n) if(LS$prof[i] == LS$prof[j] || LS$cls[i] == LS$cls[j]) A[i,j] <- A[j,i] <- 1L graph_from_adjacency_matrix(A, mode="undirected") }
Să aplicăm graph_ore() fiecărei zile și pe lista de grafuri obținută astfel, să aplicăm greedy_color_by_centrality() și să verificăm apoi, rezultatele colorării:
l5G <- map(Zile, graph_ore) %>% map(., greedy_color_by_centrality) %>% setNames(Zile) print(lapply(l5G, function(G) V(G)$color %>% unique())) $Lu [1] 6 5 3 1 4 2 7 $Ma [1] 6 4 1 2 3 5 7 $Mi [1] 7 3 1 4 2 6 5 $Jo [1] 6 4 1 2 5 3 7 $Vi [1] 6 7 1 4 3 5 2
Lecțiile fiecărei zile în parte, au fost colorate cu 1..7 – altfel spus, au fost alocate pe orele 1:7 ale zilei, evitând suprapunerile (fiindcă lecțiile aceluiași profesor sau ale aceleiași clase sunt adiacente în graf, deci au primit culori distincte).
În treacăt fie spus, dacă înlocuim cu greedy_vertex_coloring():
l5G <- map(Zile, graph_ore) %>% map(., greedy_vertex_coloring) print(lapply(l5G, unique) %>% setNames(Zile))
atunci rezultă și zile în care lecțiile sunt etichetate cu 1..8, în loc de 1..7.
Să transferăm acum „culorile” rezultate mai sus, în câte un câmp $ora, corespunzător lecțiilor fiecărei zile din LSS:
for(zi in Zile) LSS[[zi]] <- LSS[[zi]] %>% mutate(ora = V(l5G[[zi]])$color)
În lista LSS avem acum câte un orar prof|cls|ora, pentru fiecare zi. Următoarea funcție ne dă orarul clasei care îi este indicată:
orar_cls <- function(Cls) map_dfc(Zile, function(zi) { orr <- LSS[[zi]] %>% filter(cls == Cls) %>% select(ora, prof) %>% arrange(ora) while(nrow(orr) < 7) orr <- orr %>% add_row(prof = "") orr %>% select(prof) }) %>% setNames(Zile)
Apelând de exemplu pentru "9A" și "10A" (și aranjând rezultatele într-un data.frame), avem:
9A 10A
Lu Ma Mi Jo Vi Lu Ma Mi Jo Vi
1 Em1Ev1 Fi6 R02 M06 R02 R05 M05 Fi5 Ec1 En1
2 Bi1 N14 Ef1 Gg2 M06 M05 Is2 Bi1 N08 Bi1
3 R02 R02 M06 Fs1 En5 Gg1 Fi5 M05 R05 Ch1
4 Ch2 Is1 Fi6 Fi6 Bi1 Em1Ev1 Ge1Ge3 N08 M05 Fi5
5 M06 Ch2 Re2 N14 N14 Ef3 En1 R05 Re2 Ps1
6 Ge1Ge2 Ge1Ge2 Ge1Ge2 Ge1Ge2 Ge1Ge2 Ge1Ge3 Ef3 Ch1 Ge1Ge3 Ge1Ge3
7 En5 Ge2 Ge1Ge3 Ge3
Este adevărat că producerea orarelor folosind ca mai sus greedy_color_by_centrality() este mult mai simplă, decât folosind mount_hours() din [1]. Numai că rezultatul este deocamdată – câtă vreme nu cizelăm mai departe lucrurile – greșit: fiindcă nu am ținut seama de cuplaje, există suprapuneri de ore; de exemplu, Lu ora a 6-a 9A are "Germană" „pe grupe” cu profesorii Ge1 și Ge2 și tot atunci, 10A are "Germană" pe grupe cu Ge1 și Ge3 - prin urmare, Ge1 ar trebui să se afle simultan în două clase diferite.
Putem corecta, adăugând în prealabil noi legături în graful G al lecțiilor: de exemplu, conectăm lecțiile lui Ge1Ge2 cu cele ale lui Ge1 și cu cele ale lui Ge2 (și analog pentru celelalte cuplaje). Totuși mount_hours() din [1] face și un lucru pe care colorarea de mai sus nu prea are cum să-l facă: se îngrijește ca fiecare profesor să nu aibă mai mult de două ferestre, în ziua respectivă.
vezi Cărţile mele (de programare)