Exerciţiu de investigare, structurare şi sintetizare a datelor
Examenul de bacalaureat din 2021
Am descărcat de pe //data.gov.ro/ rezultatele primei sesiuni a examenului de bacalaureat din 2021 – un fişier .xlsx (Excel 2007 spreadsheet) de aproape 30MiB.
Angajăm o funcţie prin care (cu tidyverse şi readxl) să extragem datele conţinute în foile Excel, în câte un „set de date” (obiect R de tip data.frame):
library(tidyverse) lDF_from_xls <- function(file_xls) { require(readxl) file_xls %>% excel_sheets() %>% set_names() %>% map(read_excel, path = file_xls) # iterează read_excel() pe foile depistate } lBac <- lDF_from_xls("2021.08.10_bac_date-deschise_2021.xlsx")
lBac este o listă cu două componente:
> names(lBac) [1] "Export Worksheet" "SQL"
lBac$SQL conţine textul unei foarte lungi comenzi SELECT, prin care se vor fi extras în prima foaie, datele dintr-o anumită bază de date; uitându-ne la "proprietăţile" fişierului .xlsx ("Document Properties": meta:initial-creator=Apache POI), constatăm că acesta a fost creat folosind Apache POI – despre care aflăm că este o interfaţă la anumite biblioteci Java prin care se pot accesa (citi/scrie) fişiere în formatele specifice pentru Microsoft Office.
Obs. Dacă ţi-ai orientat "strategia de informatizare" pe microsoftizare funcţionărească (acoperită şi închisă de licenţe comerciale, bazată pe meniurile oferite şi pe point-and-click), cum s-au petrecut lucrurile la noi – n-ai ce să mai faci, eşti obligat să cauţi intermedieri pentru a decontorsiona şi a decripta formatele Microsoft-Office şi eşti obligat să complici toate lucrurile (mărind, convenabil probabil, toate costurile: în loc de 1MiB de date, lucrezi cu măcar 30MiB de date; în loc de 2 pagini simple de hârtie, aranjezi „profesionist” 10 coli; iar pentru aceasta, în loc de 10000€ plăteşti 500000€; că doar… nu-s banii tăi).
Comanda SELECT (din lBac$SQL) indică deja câmpurile de date cu care vom avea de-a face şi probabil ne va folosi pentru a ne lămuri asupra semnificaţiei unora dintre acestea – încât o decupăm şi o păstrăm într-un fişier-text separat:
> write_csv(lBac$SQL, file = "bac21.sql") # comanda SELECT...FROM...JOIN...WHERE
Datele propriu-zise sunt conţinute în lBac$"Export Worksheet" şi le salvăm, pentru orice eventualitate – dar le şi decupăm din lista lBac, într-un obiect independent BAC, pe care vrem să vizăm numai câmpurile care ar interesa într-o analiză statistică:
> saveRDS(lBac[[1]], file = "bac21_orig.RDS") > BAC <- lBac[[1]]
Să vedem cum sunt structurate iniţial, datele respective:
> str(BAC) tibble [133,664 × 52] (S3: tbl_df/tbl/data.frame) $ Cod unic candidat : num [1:133664] 10019 11067 11106 11818 11785 ... $ Sex : chr [1:133664] "F" "F" "F" "M" ... $ Specializare : chr [1:133664] "Matematica-Informatica" "Științe Sociale" ... $ Profil : chr [1:133664] "Real" "Uman" "Tehnic" "Tehnic" ... $ Fileira : chr [1:133664] "Teoretică" "Teoretică" "Tehnologică" ... $ Forma de învățământ: chr [1:133664] "Zi" "Frecvență redusă" "Zi" "Zi" ... $ Mediu candidat : chr [1:133664] "RURAL" "URBAN" "RURAL" "RURAL" ... $ Unitate (SIIIR) : chr [1:133664] "3261101602" "3661100016" "3261101724" ... $ Unitate (SIRUES) : chr [1:133664] "320675697" "718401" "320675702" "1181411" ... $ Clasa : chr [1:133664] "a XII-a XII MI" "a XIII-a A" "a XII-a B" ... $ Subiect ea : chr [1:133664] "Limba română (REAL)" "Limba română (UMAN)" ... $ Subiect eb : chr [1:133664] NA NA NA NA ... $ Limba modernă : chr [1:133664] "Limba engleză" "Limba engleză" ... $ Subiect ec : chr [1:133664] "Matematică MATE-INFO" "Istorie" ... $ Subiect ed : chr [1:133664] "Biologie vegetală și animală" "Geografie" ... $ Promoție : chr [1:133664] "2013-2014" "2013-2014" "2013-2014" ... $ NOTE_RECUN_A : chr [1:133664] "Da" "Da" "Da" "Da" ... $ NOTE_RECUN_B : chr [1:133664] "Nu" "Nu" "Nu" "Nu" ... $ NOTE_RECUN_C : chr [1:133664] "Da" "Da" "Da" "Da" ... $ NOTE_RECUN_D : chr [1:133664] "Da" "Da" "Da" "Da" ... $ NOTE_RECUN_EA : chr [1:133664] "Da" "Da" "Da" "Da" ... $ NOTE_RECUN_EB : chr [1:133664] "Nu" "Nu" "Nu" "Nu" ... $ NOTE_RECUN_EC : chr [1:133664] "Da" "Nu" "Da" "Da" ... $ NOTE_RECUN_ED : chr [1:133664] "Nu" "Da" "Nu" "Nu" ... $ STATUS_A : chr [1:133664] "Avansat" "Avansat" "Mediu" "Avansat" ... $ STATUS_B : chr [1:133664] "Neevaluat" "Neevaluat" "Neevaluat" ... $ STATUS_C : chr [1:133664] "Calificativ" "Calificativ" "Calificativ" ... $ STATUS_D : chr [1:133664] "Avansat" "Mediu" "Mediu" "Avansat" ... $ STATUS_EA : chr [1:133664] "Promovat" "Promovat" "Promovat" ... $ STATUS_EB : chr [1:133664] "Neevaluat" "Neevaluat" "Neevaluat" ... $ STATUS_EC : chr [1:133664] "Promovat" "Promovat" "Promovat" ... $ STATUS_ED : chr [1:133664] "Promovat" "Promovat" "Promovat" ... $ ITA : chr [1:133664] "A2" "B2" "A2" "A1" ... $ SCRIS_ITC : chr [1:133664] "A2" "B1" "A2" "A2" ... $ SCRIS_PMS : chr [1:133664] "A1" "B1" "A1" "-" ... $ ORAL_PMO : chr [1:133664] "A2" "B2" "A2" "A1" ... $ ORAL_IO : chr [1:133664] "A2" "B2" "A2" "A1" ... $ NOTA_EA : num [1:133664] 5.05 5.9 6.3 5.1 6.45 5.85 2.6 5.2 -2 5 ... $ NOTA_EB : num [1:133664] NA NA NA NA NA NA NA NA NA NA ... $ NOTA_EC : num [1:133664] 6.1 5.1 5.8 5.55 5 5.4 3.35 5.15 7.45 5 ... $ NOTA_ED : num [1:133664] 7.55 5 6.2 8.1 7.8 -2 1.2 4.3 -2 7.5 ... $ CONTESTATIE_EA : chr [1:133664] "Nu" "Nu" "Nu" "Nu" ... $ NOTA_CONTESTATIE_EA: num [1:133664] NA NA NA NA NA NA 2.6 NA NA NA ... $ CONTESTATIE_EB : chr [1:133664] "Nu" "Nu" "Nu" "Nu" ... $ NOTA_CONTESTATIE_EB: logi [1:133664] NA NA NA NA NA NA ... $ CONTESTATIE_EC : chr [1:133664] "Nu" "Nu" "Nu" "Nu" ... $ NOTA_CONTESTATIE_EC: num [1:133664] NA NA NA NA NA NA 3.2 NA NA NA ... $ CONTESTATIE_ED : chr [1:133664] "Nu" "Nu" "Nu" "Nu" ... $ NOTA_CONTESTATIE_ED: num [1:133664] NA NA NA NA NA NA 1.2 NA NA NA ... $ PUNCTAJ DIGITALE : num [1:133664] 63 44 39 63 42 41 29 19 45 62 ... $ STATUS : chr [1:133664] "Promovat" "Nepromovat" "Promovat"... $ Medie : num [1:133664] 6.23 5.33 6.1 6.25 6.41 NA NA NA NA 5.83 ...
Avem 133664 de linii (candidaţi) pe 52 de coloane, conţinând date de tip caracter (chr), numeric (num) sau logic (logi).
Multe câmpuri sunt de fapt, de tip enumerativ (de exemplu, $Sex are ca valori "M" sau "F", iar $"Mediu candidat" enumeră "URBAN" sau "RURAL") şi le vom transforma în factori.
Unele câmpuri (de fapt, vreo 25) sunt inutile, valorile lor putând fi deduse din valorile altor câmpuri; de exemplu, $NOTA_CONTESTATIE_EA induce "Da" sau "Nu" pe câmpul $CONTESTATIE_EA (după cum înregistrează o notă, sau nota lipseşte, adică valoarea înregistrată este NA) . Cele 4 câmpuri CONTESTATIE_E* pot fi eliminate, fără nicio pierdere.
Dilema câmpului "Clasa"
Câmpul $Clasa ne-ar putea da o idee – care se dovedeşte a fi vagă şi falsă – asupra numărului de clase de care ar ţine cei 133664 candidaţi:
> length(unique(BAC$Clasa)) [1] 2887
O „clasă” ar avea în medie cam 46 de elevi, ceea ce nu poate fi adevărat.
Nu înţelegem de ce s-a păstrat acest câmp (important poate doar în faza preliminară, de culegere a datelor), care are şi valori prea „explicite” (permiţând identificarea în final a unuia sau altuia dintre candidaţi – în pofida „anonimizării” clamate):
> BAC %>% filter(Clasa == "a XIII-a XIII B TAKACS PETRU") # A tibble: 1 x 52 `Cod unic candi… Sex Specializare Profil Fileira `Forma de învăț… <dbl> <chr> <chr> <chr> <chr> <chr> 1 1093766 M Tehnician m… Tehnic Tehnol… Seral # … with 46 more variables: `Mediu candidat` <chr>, `Unitate (SIIIR)` ...
Ne-am putea lămuri poate, văzând cum referă Clasa comanda SELECT din bac21.sql:
SELECT s.id_student as "Cod unic candidat", CASE WHEN s.gender = '1' THEN 'M' ELSE 'F' END AS "Sex", /* ... */ sch.siiir_code AS "Unitate (SIIIR)", sch.code "Unitate(SIRUES)", (CASE WHEN assc.study_year = '0' THEN 'a XII-a ' WHEN assc.study_year = '1' THEN 'a XIII-a ' ELSE 'a XIV-a ' END) || assc.class_name AS "Clasa>", /* concatenează */ /* ... */ FROM candidate c INNER JOIN STUDENT s ON c.id_student = s.id_student /* ... */ INNER JOIN SCHOOL sch ON s.id_school = sch.id_school INNER JOIN DD_LOCALITY dl ON dl.id_locality = sch.id_locality INNER JOIN ASOC_SCHOOL_STUDY_CLASS assc ON assc.id_asoc_school_study_class = s.id_asoc_school_study_class INNER JOIN DD_SCHOOL_YEAR syr on syr.id_school_year=assc.id_school_year /* ... */ WHERE ce.id_session = 22
Deducem că există o bază de date cu tabele relaţionate între ele – denumite generic (probabil, trăgând dintr-un şablon general) STUDENT, SCHOOL, ASOC_SCHOOL_STUDY_CLASS etc. – de pe care s-au compilat datele furnizate în foaia Excel "Export Worksheet".
Vedem că valorile câmpului $Clasa provin din coloana class_name a tabelului assc (alias pentru ASOC_SCHOOL_STUDY_CLASS), prin prefixare cu unul dintre şirurile "a XII-a ", "a XIII-a ", sau "a XIV-a " (având în vedere că în SQL – de exemplu, în MySQL, PostgreSQL, probabil şi în Oracle – "||" reprezintă concatenarea de şiruri).
Nu avem alte informaţii, dar pare plauzibilă presupunerea că dacă şirul înscris în $Clasa începe cu "a XII-a", atunci este vorba de un absolvent din ultima promoţie, de la învăţământul de zi (şi nu de unul de la „seral”, sau dintr-o promoţie anterioară).
Să vedem dacă merită să disociem lucrurile după valorile din câmpul $Clasa; înfiinţăm o funcţie care să ne dea numărul de candidaţi pentru care şirul înscris în acest câmp are prefixul indicat ca parametru şi aplicăm funcţia respectivă pe vectorul format din cele trei specificaţii prevăzute mai sus în CASE...WHEN:
nr_cand_by <- function(prefix) B <- BAC %>% filter(str_starts(Clasa, prefix)) %>% nrow(.) vCls <- c("a XII-a ", "a XIII-a ", "a XIV-a ") map(vCls, nr_cand_by)
[[1]] 127469 # "a XII-a ..." - presupuşi a fi din promoţia 2021-zi [[2]] 5861 # "a XIII-a ..." [[3]] 334 # "a XIV-a ..."
Prin urmare, nu prea avem de ce să „puricăm” lucrurile după valorile câmpului $Clasa: cei vreo 6000 de candidaţi dinafara promoţiei 2021-zi ar forma o proporţie neglijabilă din punct de vedere statistic, faţă de volumul total de 133664 candidaţi.
Am putea să păstrăm (pentru orice eventualitate) acest câmp, înscriind însă numai două valori – de exemplu 1 în loc de "a XII-a ..." şi 0 în rest. Dar nu cumva ne păcălim? – există un câmp $Promoție şi putem verifica ipoteza „plauzibilă” făcută mai sus, că prefixul "a XII-a ..." din câmpul $Clasa ar indica promoţia 2021-zi:
> b1 <- BAC %>% filter(Promoție == "2020-2021") > nrow(b1) [1] 114137 # nicidecum 127469, câţi găsisem după prefixul "a XII-a" din $Clasa > slice_sample(b1, n=10) %>% pull(Clasa) [1] "a XIII-a A Seral" [2] "a XII-a CLASA a XII a FILOLOGIE BORLOVAN NICOLAE" [3] "a XII-a E" [4] "a XII-a D BIL" [5] "a XII-a D" [6] "a XII-a C" [7] "a XII-a D" [8] "a XII-a G" [9] "a XII-a A INDUSTRIE ALIMENTARA" [10] "a XII-a F"
Prin urmare, $Clasa nu are nicio legătură cu promoţia şi nici cu forma de învăţământ; în combinaţie cu informaţiile din alte câmpuri (judeţ, localitate, centru de examen, şcoală), $Clasa permite identificarea clasei ("a XII-a D", "a XIII-a A Seral", etc.) din care a făcut parte candidatul – ceea ce o fi fost important când s-au cules datele, dar este absolut irelevant pentru analiza statistică a rezultatelor examenului.
Prin urmare se cuvine să eliminăm $Clasa – chiar fără nicio jenă: nu poate să ne intereseze ceva ca "a XII-a CLASA a XII a FILOLOGIE BORLOVAN NICOLAE".
Judeţul candidatului
Pentru analiza rezultatelor este firesc să avem în vedere judeţul (nu localitatea, sau şcoala, sau clasa) din care provine candidatul. Nu ne interesează „codul fiscal” al unităţii de învăţământ din care provine candidatul şi nici alte informaţii specifice unităţii de învăţământ – aşa că vom elimina câmpul $"Unitate (SIRUES)".
De remarcat un pas înainte: "2021.08.10_evnat_date-deschise_2021-1.xlsx" (datele examenului de "Evaluare Naţională") nu mai conţine câmpul "SIRUES".
Judeţul este indicat de primele două din cele 10 caractere (cifre) înregistrate pe câmpul $"Unitate (SIIIR)". Codul "SIIIR" ("Sistemul Informatic Integrat al Invăţământului din România") identifică fiecare unitate şcolară – deci putem afla imediat din câte şcoli au provenit candidaţii:
> length(unique(BAC$"Unitate (SIIIR)")) [1] 1453 # unităţi şcolare din care au provenit candidaţii > length(unique(substr(BAC$"Unitate (SIIIR)", 1, 2))) [1] 42 # desigur - avem 42 de "judeţe"
Judeţele au o codificare standard (v. ISO 3166-2:RO), folosită de exemplu la înmatricularea în circulaţie a vehiculelor (de exemplu, "RO-CL" sau simplu "CL" corespunde judeţului Călăraşi, iar "RO-B" municipiului Bucureşti); însă codificarea judeţelor prin câte două cifre cam diferă, de la o instituţie la alta (şi probabil, de la o vreme la alta) – aşa că avem de căutat ce asociere are în vedere "SIIIR".
Căutând pe //data.gov.ro termenul "reţea şcolară", găsim un fişier Excel de vreo 3MiB care „include datele tuturor unităților de stat și private subordonate Ministerului Educației și Cercetării care funcționează în anul școlar 2020-2021”:
lRS <- lDF_from_xls("retea_scolara_22_10_2020.xlsx")
Lista lRS obţinută astfel conţine două tabele (obiecte tibble) – pentru învăţământul de stat şi respectiv, pentru cel "privat"; este suficient să vizăm componenta $stat. Primele două linii sunt goale (conţin NA în toate cele 30 de coloane), iar a treia linie joacă rolul de „antet”, conţinând denumirile coloanelor – între care şi cele care ne interesează, "Judet PJ" şi "Cod SIIIR PJ" (între altele, văzând câte linii are fiecare tibble, rezultă că în anul 2021 avem 17287-3=17284 şcoli de stat şi 878 şcoli private).
Ignorăm primele 3 linii, reţinem numai cele două coloane care ne interesează, le denumim $jud şi $sii, păstrăm numai primele două caractere din $sii şi apoi păstrăm numai liniile distincte între ele:
JS <- lRS[[1]][ -(1:3), c(2, 5)] colnames(JS) <- c("jud", "sii") JS$sii <- substr(JS$sii, 1, 2) JS <- JS %>% distinct()
Rezultă această corespondenţă între codurile ISO ale judeţelor şi cele de câte două cifre din sistemul "SIIIR" (precizăm că la alte instituţii de stat, codurile sunt 01..42, în ordinea alfabetică a codurilor ISO):
jud sii jud sii jud sii 1 AB 01 15 CT 13 29 MS 26 2 AG 03 16 CV 14 30 NT 27 3 AR 02 17 DB 15 31 OT 28 4 B 40 18 DJ 16 32 PH 29 5 BC 04 19 GJ 18 33 SB 32 6 BH 05 20 GL 17 34 SJ 31 7 BN 06 21 GR 52 35 SM 30 8 BR 09 22 HD 20 36 SV 33 9 BT 07 23 HR 19 37 TL 36 10 BV 08 24 IF 23 38 TM 35 11 BZ 10 25 IL 21 39 TR 34 12 CJ 12 26 IS 22 40 VL 38 13 CL 51 27 MH 25 41 VN 39 14 CS 11 28 MM 24 42 VS 37
Putem găsi în diverse locuri, numele obişnuite ale judeţelor reprezentate prin codurile ISO – şi putem formula un „dicţionar” ISO_jud având drept chei codurile ISO şi drept valori, numele judeţelor; de exemplu, ISO_jud["CL"] va fi "Călăraşi", iar ISO_jud[ c("B","GR")] va fi vectorul ("Bucureşti", "Giurgiu"). Apoi, putem înlocui câmpul $"Unitate (SIIIR)" prin factorul $jud, având drept conţinut chiar numele judeţelor:
> BAC <- BAC %>% rename(jud = "Unitate (SIIIR)") %>% mutate(jud = substr(jud, 1, 2)) %>% mutate(jud = factor(jud)) > levels(BAC$jud) <- ISO_jud[JS %>% arrange(sii) %>% pull(jud)]
Investigarea şi restructurarea datelor
Fişierul Excel original conţine toate datele cumulate pe parcursul desfăşurării examenului, încât în final fiecare se poate încredinţa după caz, că s-a ţinut seama de cererile de contestare făcute, de notele rămase din sesiuni anterioare şi de exemplu, că nu s-a greşit cumva la înregistrarea prezenţei la o probă sau alta.
Examenul de bacalaureat, desfăşurat pe parcursul a vreo 3 săptămâni, are şi sensul de a infuza tinerei generaţii o primă doză de birocraţie, necesară bineînţeles pentru formarea statutului de cetăţean (cu drepturi şi obligaţii) al statului.
Dar pentru analiza statistică a rezultatelor avem de selectat (şi de reorganizat) numai datele necesare acesteia, în funcţie de scopurile avute în vedere.
O să analizăm pe rând mai fiecare câmp, văzând dacă merită sau nu să-l păstrăm, simplificând numele, schimbând eventual tipul de date în "factor" şi eventual, deducând (ca un detectiv) diverse proprietăţi ale sistemului.
Schimbăm numele "Cod unic candidat" al primului câmp:
> names(BAC)[1] <- "Candidat" # cheie principală
Pentru câmpul "Sex", verificăm valorile şi transformăm în factor:
> unique(BAC$Sex) [1] "F" "M" > BAC$Sex <- factor(BAC$Sex, levels = c("F", "M"))
BAC$Specializare are 95 de valori distincte, cu această distribuţie (în ordinea descrescătoare a numărului de candidaţi):
> BAC %>% count(., Specializare, sort = TRUE) # A tibble: 95 x 2 Specializare n 1 Matematica-Informatica 24275 2 Filologie 20810 3 Științe ale Naturii 19358 4 Științe Sociale 11410 5 Tehnician în activități economice 9488 6 Liceu cu program sportiv 4539 7 Tehnician în turism 3682 8 Tehnician ecolog și protecția calității mediului 2356 9 Învăţător - educatoare 2131 10 Tehnician în gastronomie 2101 # … with 85 more rows
Specializările cu proporţie prea mică – mai puţin de 2000 candidaţi, între cei 133664 – nu prea au relevanţă statistică (pe lângă cele redate mai sus, avem 10 specializări cu câte 2000-1000 de candidaţi şi 75 cu câte sub 1000, iar 34 au câte sub 100 candidaţi).
Păstrăm totuşi coloana, dar simplificăm numele şi transformăm în factor:
> BAC <- BAC %>% rename(Specia = Specializare) %>% mutate(Specia = factor(Specia))
Procedăm analog pentru câmpurile "Profil", "Fileira" (schimbăm cu Filiera) şi "Forma de învăţământ" (schimbăm numele, Forma_înv):
> BAC %>% count(., Profil, sort = TRUE) # A tibble: 10 x 2 Profil n 1 Real 43633 2 Uman 32220 3 Servicii 21368 4 Tehnic 16570 5 Resurse naturale și protecția mediului 6847 6 Educație fizică și sport 4539 7 Artistic 3617 8 Pedagogic 2314 9 Teologic 2080 10 Militar 476 > BAC %>% count(., Fileira, sort = TRUE) # Filiera # A tibble: 3 x 2 Fileira n 1 Teoretică 75853 # aici avem şi specializarea "Matematica-Informatica" (n=24275) 2 Tehnologică 44785 3 Vocațională 13026 # aici avem şi specializarea "Matematica-informatica" (n=476) > BAC %>% count(., `Forma de învățământ`, sort = TRUE) # Forma_înv # A tibble: 3 x 2 `Forma de învățământ` n 1 Zi 129616 2 Seral 2203 3 Frecvență redusă 1845
Bineînţeles că înlocuim numele "Mediu candidat" cu Mediu şi transformăm iarăşi, în factor (cu nivelele "URBAN" şi "RURAL", având n=89959 şi respectiv, n=43705).
Putem omite câmpurile "Subiect {ea,eb,ec,ed}": disciplinele menţionate pe aceste câmpuri depind în fond de Profil şi Filiera. Ne-ar putea interesa "Limba maternă" (şi este suficient câmpul existent "NOTA_EB") şi nu vreo situaţie pe fiecare limbă maternă. Totuşi, merită păstrat câmpul "Subiect ed" (pe care îl numim Sub_D şi-l transformăm în factor): va fi interesant de confruntat rezultatele, pentru unele dintre cele 18 opţiuni existente (de exemplu, "Biologie" versus "Informatică" – v. [2]).
Pentru orice eventualitate, păstrăm ca factor, câmpul Promoţie (adaptând numele, fiindcă folosim "Romanian cedilla": combinaţia de taste AltGr+t produce 'ţ' şi nu 'ț').
Omitem cele 8 câmpuri "NOTE_RECUN_*", care consemnează prin "Da" sau "Nu" dacă a fost cazul de a recunoaşte candidatului nota la o probă sau alta, obţinută într-o sesiune anterioară.
Îndepărtăm câmpurile care consemnează pentru fiecare probă "Promovat", "Nepromovat", Absent", sau "Eliminat", sau consemnează pentru unele probe diverse calificative ("Avansat", "Mediu", "Incepator", sau "A1", "B1", "-", etc); dacă va fi să facem vreo statistică putem folosi mai simplu, câmpurile pe care sunt înscrise notele şi câmpul "PUNCTAJ DIGITALE".
Eliminăm deasemenea, câmpurile care consemnează depunerea unei contestaţii la o probă sau alta şi pe cele pe care s-au înscris notele acordate în urma soluţionării contestaţiilor (am văzut în [1] sau [2] că acestea nu influenţează statistica rezultatelor).
După toate modificările descrise mai sus, rămânem cu această structură de date:
> str(BAC) tibble [133,664 × 16] (S3: tbl_df/tbl/data.frame) $ Candidat: int [1:133664] 10019 11067 11106 11818 11785 12215 12861 ... $ Sex : Factor w/ 2 levels "F","M": 1 1 1 2 2 2 1 1 1 2 ... $ Specia : Factor w/ 95 levels "Arhitectură, arte ambientale și design",..: 14 20 ... $ Profil : Factor w/ 10 levels "Artistic","Educație fizică și sport",..: 5 10 8 ... $ Filiera : Factor w/ 3 levels "Tehnologică",..: 2 2 1 1 3 1 2 2 1 1 ... $ Forma_înv: Factor w/ 3 levels "Frecvență redusă",..: 3 1 3 3 3 3 1 3 3 3 ... $ Mediu : Factor w/ 2 levels "RURAL","URBAN": 1 2 1 1 2 2 1 2 1 2 ... $ jud : Factor w/ 42 levels "Alba","Arad",..: 32 36 32 15 36 22 27 9 6 31 ... $ Sub_D : Factor w/ 18 levels "Anatomie și fiziologie umană, genetică...",..: 2 11 ... $ Promoţie: Factor w/ 22 levels "19XY","2000-2001",..: 15 15 15 15 15 15 ... $ notaA : num [1:133664] 5.05 5.9 6.3 5.1 6.45 5.85 2.6 5.2 -2 5 ... $ notaB : num [1:133664] NA NA NA NA NA NA NA NA NA NA ... $ notaC : num [1:133664] 6.1 5.1 5.8 5.55 5 5.4 3.35 5.15 7.45 5 ... $ notaD : num [1:133664] 7.55 5 6.2 8.1 7.8 -2 1.2 4.3 -2 7.5 ... $ punctaj : num [1:133664] 63 44 39 63 42 41 29 19 45 62 ... $ Status : Factor w/ 4 levels "Absent","Eliminat",..: 4 3 4 4 4 1 3 3 1 3 ... $ Medie : num [1:133664] 6.23 5.33 6.1 6.25 6.41 NA NA NA NA 5.83 ...
De observat că unele valori ale celor 4 câmpuri de "note" sunt -1 sau -2; ne putem lămuri uşor că acestea înregistrează situaţiile "absent" sau "eliminat" care sunt de fapt evidenţiate în final pe câmpul Status; vom înlocui valorile menţionate prin NA (cum avem deja pe câmpul Medie):
> BAC <- BAC %>% na_if(-1) %>% na_if(-2)
Subliniem că dplyr::na_if() înlocuieşte cu NA valoarea indicată, în toate coloanele – dar în cazul nostru n-a trebuit să evităm vreo coloană, fiindcă aveam -1 sau -2 numai în cele 4 coloane de note.
Aşteptări plauzibile…
Avem an de an, aceleaşi 52 de câmpuri în fişierul Excel în care s-au strâns rezultatele şi aceeaşi metodologie de desfăşurare a examenului de bacalaureat; fiindcă nu prea s-a schimbat ceva între timp, cel mai firesc este să avem cam aceleaşi concluzii ca şi în anii anteriori (v. şi [1] şi [2], unde am vizat anii 2015 şi 2016):
— valorile $Sex="F" şi $Mediu="URBAN" au proporţii sensibil mai mari decât "M" şi respectiv "RURAL";
— promovabilitatea este mult mai mare pentru $Filiera="Teoretică", decât pentru celelalte două filiere; cam jumătate dintre nepromovaţi sunt din filiera "Tehnologică";
— proporţia cea mai mare de "Absent" sau "Eliminat" o avem la filiera "Tehnologică"; cel mai mic număr de "Absent", "Eliminat" sau "Nepromovat" avem la $Profil="Militar";
— procentul de promovare este cam de 65% şi este sensibil mai mare la "F" decât la "M" şi deasemenea, la "URBAN" decât la "RURAL";
— cei de la "matematică-informatică" au optat majoritar pentru "Anatomie" sau "Biologie" (faţă de "Informatică") la proba D (şi cu rezultate mai slabe);
— pe judeţe, rezultatele sunt cam la fel (ca şi în anii anteriori); cam aceleaşi judeţe sunt în frunte şi cam aceleaşi au rezultatele cel mai slabe.
Ar fi important de comparat notele obţinute la probele de bacalaureat, cu mediile obţinute la obiectele respective în cursul anilor de liceu. Desigur, un asemenea studiu ar fi posibil numai dacă ar fi iniţiat de către Minister (altfel, cum să obţii situaţiile anuale din toate şcolile de care aparţin candidaţii?). Dar bineînţeles că Ministerul nu agreează un asemenea studiu, sub pretextul că notarea elevilor nu este "unitară": un 9 într-o şcoală oarecare este abia 6 în vreo altă şcoală, astfel că ne trebuie un "examen naţional" în final, pentru a decide admiterea fără examen în facultăţi.
N-ar fi deloc surprinzător, să constatăm totuşi că rezultatele la bacalaureat sunt direct proporţionale (cu unele excepţii, desigur) cu cele consemnate deja în cataloagele şcolare anuale; altfel spus, am ajunge la concluzia simplă că singurul merit al acestui examen este dat de exerciţiul de birocraţie pe care îl implică.
Pe cerinţele curente, bacalaureatul mai degrabă încurcă şi degradează sistemul de învăţământ: profesorii au renunţat să se mai ţină de "metodica predării disciplinei" şi au căpătat obiceiul de a face "pregătire pentru BAC", practicând materiile respective la nivelul strictului necesar pentru rezolvarea subiectelor tipice de "BAC" (urmarea fiind deja binecunoscută: cei care pe baza rezolvării subiectelor de "BAC" au ajuns studenţi, au în general o pregătire mediocră şi trebuie s-o ia de la capăt).
Mai departe (neavând alte aşteptări statistice decât cele deja consemnate mai sus, şi nici curiozităţi) doar prezentăm (sau constituim) şi exemplificăm câteva funcţii prin care putem obţine diverse statistici, într-o formă sau alta.
Tabele de contingenţă a factorilor
Funcţia table() contorizează fiecare combinaţie de nivele ale factorilor indicaţi; proportions() exprimă proporţia fiecăreia dintre aceste combinaţii faţă de totalul pe rânduri, pe coloane, sau pe întregul tabel furnizat de table().
De exemplu, putem constitui o situaţie după factorii $Mediu şi $Sex a valorilor factorului $Status, astfel:
tb <- table(BAC[c('Status', 'Mediu', 'Sex')]) > str(tb) 'table' int [1:4, 1:2, 1:2] 1229 17 7994 14913 1614 15 9555 35389 1575 44 ... - attr(*, "dimnames")=List of 3 ..$ Status: chr [1:4] "Absent" "Eliminat" "Nepromovat" "Promovat" ..$ Mediu : chr [1:2] "RURAL" "URBAN" ..$ Sex : chr [1:2] "F" "M"
Ne-a rezultat un array 3-dimensional; de exemplu, tb[4,2,1] ne dă numărul de promovaţi din mediul urban, de sex "F"; iar tb[4,,] tabelează numărul de promovaţi – vizând al 4-lea nivel din factorul $Promovat – după mediu şi sex:
> tb[4,,] Sex Mediu F M RURAL 14913 9567 URBAN 35389 28721
Iar dacă vrem să exprimăm ca proporţie faţă de totalul candidaţilor pe fiecare mediu, respectiv pe fiecare sex:
> proportions(tb[4,,], 1) # faţă de total-linie (dimensiunea 1) Sex Mediu F M RURAL 0.6091912 0.3908088 URBAN 0.5520044 0.4479956 > proportions(tb[4,,], 2) # faţă de total-coloană (dimensiunea 2) Sex Mediu F M RURAL 0.2964693 0.2498694 URBAN 0.7035307 0.7501306
Putem sintetiza grafic în multe moduri – de exemplu, prin lattice::barchart():
tb <- table(BAC[c('Status', 'Mediu', 'Sex')]) tb.prop <- 100*round(proportions(tb), 4) # procente din totalul candidaţilor print(lattice::barchart(tb.prop, # vizualizează contingenţa factorilor aspect = 1, # lăţime/înălţime stack = FALSE, # cu bare alăturate xlab = "Procente", auto.key = list(space="right") # cu legendă, la dreapta ))
De data aceasta am invocat proportions() fără a preciza dimensiunea (1 sau 2) – încât obţinem proporţiile (exprimate acum procentual) faţă de totalul candidaţilor:
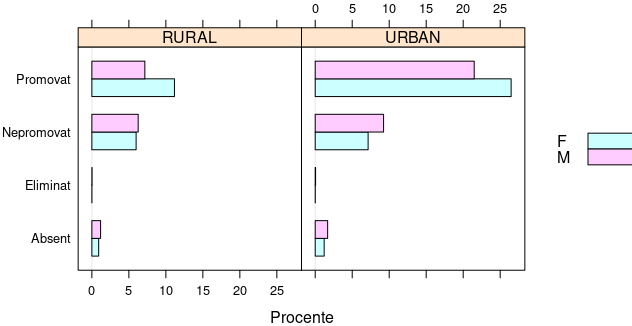
Imaginea ne spune că promovaţi sunt cam 11% "Rural/F" şi 7% "Rural/M" (deci 18% "Rural") şi 26% "Urban/F", 21% "Urban/M" (deci 47% "Urban") – în total fiind cam 65% promovaţi; ş.a.m.d.
Analog putem confrunta rezultatele după alte criterii; de exemplu, înlocuind în secvenţa de mai sus "Sex" cu "Filiera", obţinem tabelul de contingenţă pentru factorii Status, Mediu şi Filiera (legenda va avea acum 3 culori). Dar să observăm că procedând ca mai sus, am avea proporţiile (sau procentele) numai după una dintre cele trei „dimensiuni” posibile (şi ar trebui să repetăm de 3 ori, dacă vrem să avem procentele şi faţă de totalul pe linie, şi faţă de totalul pe coloană şi faţă de totalul candidaţilor).
Următoarea funcţie foloseşte table() şi proportions() pentru a constitui în final un tibble care conţine pentru fiecare nivel al factorului indicat, atât numărul de candidaţi din fiecare categorie de $Status, cât şi procentele corespunzătoare faţă de fiecare dintre cele 3 „dimensiuni” (linie, coloană şi tabel):
paste_csv <- function(vct) paste(vct, collapse=",") # formatează CSV vectorul dat status_by <- function(Factor) { fld <- BAC[[Factor]] sts <- BAC$Status ctg <- table(fld, sts) PR <- round(100*proportions(ctg, 1), 2) # faţă de totalurile pe linie PC <- round(100*proportions(ctg, 2), 2) # faţă de totalurile pe coloană PT <- round(100*proportions(ctg), 2) # faţă de totalul candidaţilor GT <- sum(ctg) # totalul candidaţilor RS <- rowSums(ctg) # totalurile pe linii CS <- colSums(ctg) # totalurile pe coloane sink("temp.csv", append=TRUE) # formulăm întâi într-un fişier CSV... cat(Factor, ",", paste_csv(levels(sts)), ",row_tot", "\n") for(i in 1:nrow(ctg)) { cat(levels(fld)[i], ",", paste_csv(c(ctg[i, ], RS[i])), "\n") cat(",", paste_csv(c(PR[i, ], round(100*RS[i] / GT, 2))), "\n") cat(",", paste_csv(PC[i, ]), ",\n") cat(",", paste_csv(PT[i, ]), ",\n") } cat("col_tot,", paste_csv(c(CS, GT)), "\n") cat(",", paste_csv(round(100*CS/GT, 2)), ",\n") sink() CTG <- read_csv("temp.csv", col_types="cnnnnn") file.remove("temp.csv") CTG[[Factor]][is.na(CTG[[Factor]])] <- "" CTG }
Întâi am înscris într-un fişier intermediar, în format CSV (separând valorile prin virgulă) câte o linie din cele 4 tabele, am adăugat (tot în format CSV) linia corespunzătoare totalurilor pe coloane şi în final, prin read_csv() obţinem din fişierul respectiv, obiectul tibble pe care ni-l propusesem. De exemplu:
> CTG <- status_by("Filiera") > print(CTG) # A tibble: 14 x 6 Filiera Absent Eliminat Nepromovat Promovat row_tot 1 "Tehnologică" 4670 95 21504 18516 44785 2 "" 10.4 0.21 48.0 41.3 33.5 3 "" 70.1 64.6 56.2 20.9 NA 4 "" 3.49 0.07 16.1 13.8 NA 5 "Teoretică" 1595 35 13024 61199 75853 6 "" 2.1 0.05 17.2 80.7 56.8 7 "" 23.9 23.8 34.0 69.1 NA 8 "" 1.19 0.03 9.74 45.8 NA 9 "Vocațională" 398 17 3736 8875 13026 10 "" 3.06 0.13 28.7 68.1 9.75 11 "" 5.97 11.6 9.76 10.0 NA 12 "" 0.3 0.01 2.8 6.64 NA 13 "col_tot" 6663 147 38264 88590 133664 14 "" 4.98 0.11 28.6 66.3 NA
Pe ultima coloană, "$row_tot", citim aşa: din cei 133664 candidaţi, 33.5% adică 44785 ţin de filiera "Tehnologică", 56.8% adică 75853 ţin de filiera "Teoretică" şi 9.75% adică 13026 ţin de filiera "Vocaţională".
De pe ultimele două linii, citim aşa: din cei 133664 candidaţi, 66.3% adică 88590 sunt promovaţi, 28.6% adică 38264 sunt nepromovaţi, 0.11% adică 147 au fost eliminaţi şi 4.98% adică 6663 au absentat.
Pentru încă un exemplu de „citire” – pentru filiera "Tehnologică" (liniile 1-4), valorile din coloana $Promovat 18516, 41.3, 20.9 şi 13.8 reprezintă respectiv, numărul de promovaţi ai acestei filiere, procentul lor faţă de totalul candidaţilor filierei (44785), procentul lor faţă de totalul tuturor promovaţilor (88590) şi procentul lor faţă de volumul tuturor candidaţilor (133664).
Desigur… este mai greu de citit cifrele dintr-un tabel de date, decât de „citit” o imagine. Putem imagina „spectaculos” (dar nu avem noi, niciun merit pentru aceasta) tabelul de mai sus – dar numai pe una dintre cele 3 dimensiuni, de exemplu după totalul pe coloane:
tb <- table(BAC$Filiera, BAC$Status) tb.prop <- round(100*proportions(tb, 2), 2) # faţă de totalul coloanei tb.df <- as.data.frame(tb.prop) names(tb.df) <- c("Filiera", "Status", "Procent") G <- ggplot(tb.df, aes(x=Filiera, y=Procent, fill=Status)) + geom_col(position="dodge") print(G)
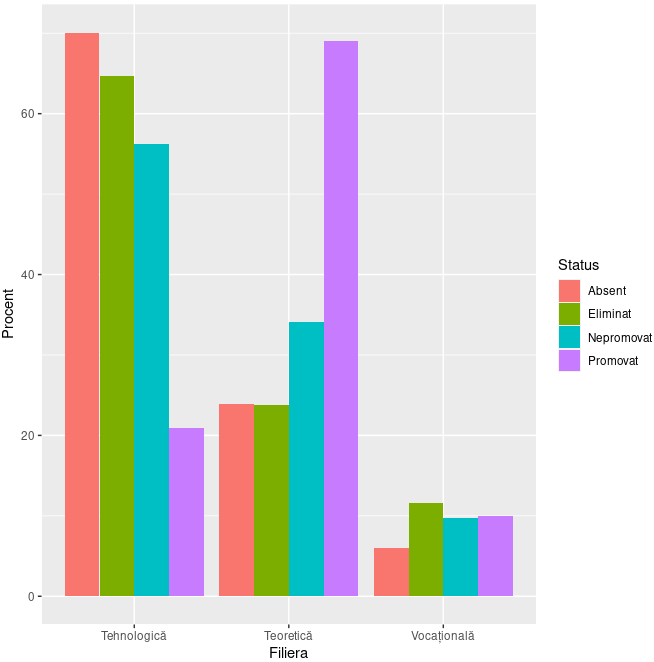
Citim imaginea cam aşa: pe filiere (de la stânga spre dreapta), absenţii sunt repartizaţi astfel: 70%, 25%, 5%; eliminaţi: 65%, 25%, 10%; nepromovaţi: 55%, 35%, 10%; promovaţi: 20%, 70%, 10% (bineînţeles că procentele indicate sunt aproximate „din ochi”, după grila aşezată pe imagine).
Dacă vrem, putem repeta secvenţa de mai sus, pentru proporţiile faţă de volumul fiecărei filiere şi respectiv, faţă de întreaga populaţie; iar ggplot2 asigură posibilitatea de a concentra cele trei imagini care s-ar obţine, într-un singur panou grafic.
Raportarea pe judeţe, a procentelor de promovare
Pentru judeţe, tabloul de contingenţă rezultat prin status_by() este mult mai lung decât cel redat mai sus pentru "Filiera":
> by_jud <- status_by("jud") # A tibble: 170 x 6 jud Absent Eliminat Nepromovat Promovat row_tot <chr> <dbl> <dbl> <dbl> <dbl> <dbl> 1 "Alba" 115 11 575 1752 2453 2 "" 4.69 0.45 23.4 71.4 1.84 3 "" 1.73 7.48 1.5 1.98 NA 4 "" 0.09 0.01 0.43 1.31 NA 5 "Arad" 225 1 901 1713 2840 6 "" 7.92 0.04 31.7 60.3 2.12 7 "" 3.38 0.68 2.35 1.93 NA 8 "" 0.17 0 0.67 1.28 NA 9 "Argeş" 218 6 1202 3069 4495 10 "" 4.85 0.13 26.7 68.3 3.36 # … with 160 more rows
Ne-ar interesa numai linia a doua de la fiecare judeţ, pe care avem procentele referitoare la judeţul respectiv; deci extragem linia 2 şi apoi tot a 4-a linie de la cea curent extrasă; ignorăm prima coloană (pe care avem mereu "") şi transformăm în matrix (pentru a folosi barchart()) – apoi, etichetăm liniile matricei numerice rezultate prin numele judeţelor şi le ordonăm după procentul de promovare:
JUD <- by_jud %>% select(2:6) %>% slice(., seq(2, 168, by=4)) %>% # linia 2 de la fiecare judeţ as.matrix() row.names(JUD) <- levels(BAC$jud) JUD <- JUD[, c(4, 3, 1, 2, 5)] # reordonăm coloanele (prima: "Promovat") JUD <- JUD[order(JUD[, 1]), ] # ordonăm liniile după procentul de promovare
În coloana a 4-a am adus câmpul "Eliminat"; dar valorile de pe acest câmp sunt foarte mici, aşa că le „cosmetizăm” (prin dublare) – scopul fiind de a mări claritatea imaginii grafice. Din acelaşi motiv, mărim de 1.5 ori valorile din coloana a 5-a (acestea reprezentau procentul candidaţilor din judeţ faţă de volumul candidaţilor din 2021). Bineînţeles că (în scopul formulării legendei graficului) redenumim coloanele 4 şi 5, pentru a evidenţia cumva, „cosmetizarea” întreprinsă:
JUD[, 4] <- 2*JUD[, 4] JUD[, 5] <- 1.5*JUD[, 5] dimnames(JUD)[[2]][4:5] <- c("2Eliminat", "1.5Per2021")
În final, invocăm lattice::barchart() astfel:
colors = c("green", "orange", "grey", "black", "white", "") print(lattice::barchart(JUD, auto.key = list(space="right", cex=0.8, points=FALSE, rectangles=TRUE, size=1.2), par.settings = list(superpose.polygon = list(col=colors)), scales = list(tck = 0.5, # gradaţii şi etichete pe axe x = list(at=seq(0, 100, by=10), labels=c("","","20%","", "40%","","60%","","80%","","100%"))), xlab = "", # "Procent (din candidaţii judeţului)", panel = function(...) { # adaugă marcaje verticale panel.barchart(...) panel.abline(v = seq(20, 90, 20), col = "white", lwd = 1.2) } ))
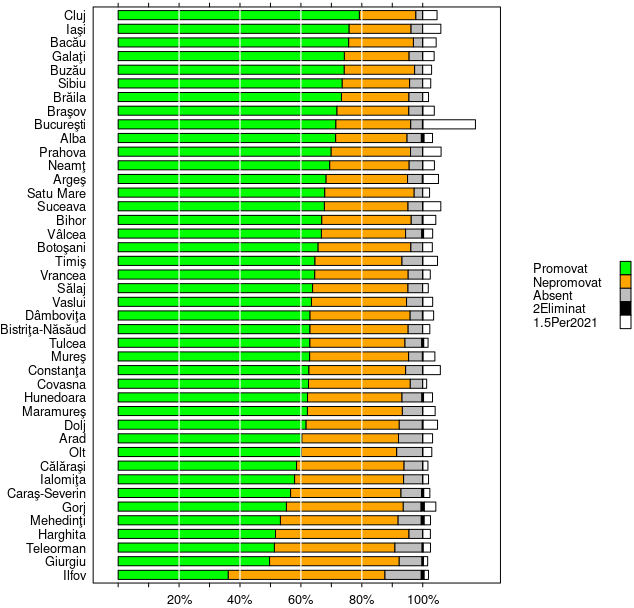
Judeţul Cluj are cel mai mare procent de promovare (au promovat 80% dintre candidaţii din acest judeţ) şi cel mai mic procent de absenţi; la cealaltă extremă, judeţul Ilfov are cel mai mic procent de promovare (sub 40%) şi (se vede clar) are cel mai mare procent de absenţi (şi printre cele mai mari procente de eliminaţi, alături de Gorj, Mehedinţi, Alba).
Se vede clar deasemenea, că din întregul lot 2021, Bucureşti are cel mai mare procent de candidaţi (mult peste judeţe), iar Covasna – cel mai mic (urmat de Giurgiu, Ilfov, Călăraşi, Tulcea, Sălaj, Brăila).
vezi Cărţile mele (de programare)