În loc de tehnologii, editarea manuală
[1] V.Bazon - De la seturi de date și limbajul R, la orare școlare (Google Books)
[2] V. Bazon - Orare școlare echilibrate și limbajul R (Google Books)
Orarul unei anumite școli este publicat pe site-ul școlii prin două fișiere PDF, de pe care aici reproducem câte un fragment:
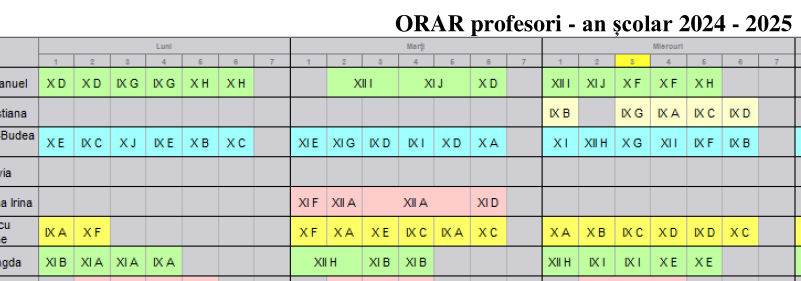
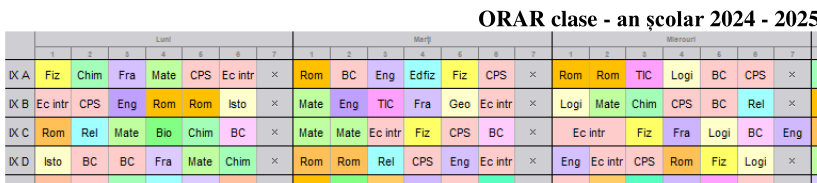
Inspectând "Properties" pentru aceste fișiere, găsim:
Producer: Microsoft® Word LTSC
Format: PDF-1.7
Optimized: Yes
Paper Size: A3, Landscape (420 × 297 mm)
Ne interesează datele orarului respectiv (exceptând numele de profesori, omise în prima dintre cele două imagini); dar de data aceasta (spre deosebire de cazuri similare prezentate anterior pe aici), nu reușim să extragem textul nici folosind Ghostscript, nici intermediind prin vreun serviciu extern "PDF-to-Excel" și nici folosind direct tesseract. "Optimizările" interzic selectarea și copierea de text, iar culorile aplicate pe celule încurcă iremediabil procedeele uzuale de extragere automată a textului; avem aici un caz nefericit, când de dragul vizualizării sau mai degrabă din neștiință (cu suficiența specifică tehnologiei Microsoft Office), datele orarului școlar sunt definitiv obturate.
Ne rămâne să procedăm în cel mai simplu mod, manual, folosind un editor de text (ceea ce ar părea neobișnuit sau hilar, pentru învățământul instituit la noi, bazat pe tehnologia point-and-click — pe dresare și pe licențele comerciale Microsoft).
Am înființat fișierul Lu.csv, l-am deschis în editorul de text Gedit și pe prima linie am înscris ca antet CSV, prof,1,2,3,4,5,6,7; am poziționat Atril Document Viewer într-o fereastră paralelă celeia în care avem Gedit și am deschis "Orar profesori-A3-....pdf". După aceste pregătiri, am citit rând pe rând numele profesorilor, din prima coloană a tabelului PDF deschis în fereastra din dreapta și le-am tastat pe câte o linie din Lu.csv, deschis în fereastra din stânga.
După ce am terminat de scris cele 72 de nume, am adăugat pe fiecare linie (folosind meniul "Find and Replace.../Replace all" din Gedit) o secvență de 7 virgule ",,,,,,,"; apoi am salvat fișierul constituit astfel "Lu.csv" și am creat câte o copie a sa pentru celelalte zile, "Ma.csv", "Mi.csv", etc.
Am început apoi să scriem clasele alocate fiecărui profesor în orele 1:7, în fiecare zi (pe rând, începând cu "Lu.csv"), citind din coloana PDF a zilei respective și scriind în fișierul CSV rămas deschis în stânga (am preferat să lucrăm pe coloane, adică pe fiecare zi în parte, fiindcă astfel am avut de citit linii scurte, de maximum 7 clase; este mai ușor de evitat greșelile "inerente" de tastare a unei linii scurte, decât a unei linii lungi):
prof,1,2,3,4,5,6,7 Andone Emanuel,10D,10D,9G,9G,10H,10H, Arghire Cristiana,,,,,,, Asandulesei-Budeanu Maria,10E,9C,10J,9E,10B,10C, Baciu Livia,,,,,,, Balasanu Ana Irina,,,,,,, Baltatescu Gheorghe,9A,10F,,,,, ETC.
Am lucrat intermitent (cu pauze lungi), definitivând cele 5 fișiere CSV în vreo trei zile. Apoi, plecând de la aceste fișiere CSV, am constituit setul tuturor lecțiilor prof|ora|cls|zl, refolosind secvențe de comenzi $\mathbf{R}$ pe care le-am mai redat și anterior:
library(tidyverse) Zile <- c("Lu", "Ma", "Mi", "Jo", "Vi") mOR <- map(Zile, function(zi) read.csv(paste0(zi, ".csv")) %>% pivot_longer(cols = 2:8, names_to = "ora", values_to = "cls") %>% filter(cls != "" & !is.na(cls)) %>% mutate(ora = gsub("X", "", ora), zl = zi) ) %>% setNames(Zile) LSS <- mOR[["Lu"]] for(zi in Zile[-1]) LSS <- rbind(LSS, mOR[[zi]]) LSS <- LSS %>% mutate(zl = factor(zl, levels = Zile, ordered=TRUE), ora = as.integer(ora)) saveRDS(LSS, "lss.RDS")
Pentru extragerea manuală a datelor din "Orar-clase-A3....pdf" am procedat mai simplu: întâi am printat cele două pagini PDF și am așezat-o pe prima pe un mic șevalet, în dreapta laptopului pe care lucrez; apoi am instituit într-un nou program $\textbf{R}$ următoarea funcție:
add_obj <- function(Q) LSS %>% filter(cls == Q) %>% arrange(zl, ora) %>% mutate(obj="") %>% as.data.frame()
pe care am exploatat-o din consola $\textbf{R}$, pentru fiecare clasă, pe rând (după ce întâi, am aflat în vectorul Cls care sunt clasele), astfel:
Cls <- LSS %>% pull(cls) %>% unique() %>% sort() # vectorul claselor DF <- add_obj("9A") %>% edit() saveRDS(DF, "9A.RDS")
add_obj() listează cele 30 (sau 31, sau 29) de lecții prof|ora|cls|zl ale clasei indicate, în ordinea zilelor și orelor și adăugă coloana obj; iar edit() ne creează o fereastră de editare a datelor respective și n-am avut decât să citesc din pagina așezată pe șevalet disciplinele înscrise pe linia clasei respective, tastându-le rând pe rând în coloana obj.
Terminând (după încă vreo două zile) de constituit cele 39 de fișiere .RDS, le-am comasat prin:
df <- readRDS("10A.RDS") for(Q in Cls[-1]) df <- rbind(df, readRDS(paste0(Q, ".RDS"))) saveRDS(df, "lessons.RDS")
lessons.RDS conține astfel, 1172 linii prof|ora|cls|zl|obj și acum putem folosi câmpul obj pentru a codifica profesorii după disciplina principală a fiecăruia, definitivând setul de date corespunzător celor două fișiere PDF (de care nu mai avem nevoie).
Folosind iarăși edit(), abreviem pe câte două litere cele 43 de nume ale disciplinelor, transformăm obj în factor și-i setăm nivelele pe denumirile abreviate:
Obj <- LSS %>% pull(obj) %>% unique() %>% sort() LSS <- LSS %>% mutate(obj = factor(obj)) lev <- levels(LSS$obj) # vechile denumiri, în ordine alfabetică edit(Obj, "obiecte.R") # abreviază pe câte două litere obj2 <- source("obiecte.R")$value Obj <- setNames(obj2, Obj) levels(LSS$obj) <- Obj[lev] # noile denumiri, ordinea alfabetică veche saveRDS(LSS, "orar1.RDS")
Următoarea funcție tabelează lecțiile profesorului indicat, în ordinea descrescătoare a numărului de ore pe fiecare disciplină pe care este încadrat:
prof_objs <- function(P) LSS %>% filter(grepl(P, prof)) %>% count(obj, sort=TRUE)
Codificăm numele din coloana prof concatenând abrevierile din coloana obj cu numerele de ordine rezultate în lista celor de pe o aceeași disciplină principală (listă ordonată după numărul de ore ale fiecăruia pe disciplina respectivă):
Prof <- LSS %>% pull(prof) %>% unique() %>% sort() Lob <- map(Prof, function(P) { OB <- prof_objs(P)[1, ] # reține numai obiectul principal data.frame(prof = P, obj = OB$obj, n = OB$n) }) %>% list_rbind() %>% droplevels() %>% arrange(desc(n)) %>% split(.$obj) Pcd <- map(seq_along(Lob), function(i) { N <- nrow(Lob[[i]]) # câți profesori, pe disciplina curentă (< 10) ob <- Lob[[i]]$obj[1] # obiectul principal obn <- paste0(ob, 1:N) # alipește numerele de ordine data.frame(prof = Lob[[i]]$prof, cod = obn) }) %>% list_rbind() prof_cod <- Pcd$cod names(prof_cod) <- Pcd$prof LSS <- LSS %>% mutate(prof = as.vector(prof_cod[prof])) saveRDS(LSS,"orar2.RDS")
Redăm pentru edificare un eșantion aleatoriu de linii din setul de date LSS:
> slice_sample(LSS, n=5) prof ora cls zl obj 1 Fi2 2 9G Lu Fi 2 CP1 6 10I Vi PC 3 En3 4 11E Vi En 4 Fi1 2 10B Jo Fi 5 Ma3 4 11J Ma Ma
Constatăm întâi că nu există lecții cuplate ("pe grupe"), adică lecții prof|zl|ora care se desfășoară cu diverși profesori în câte o aceeași zi și o aceeași oră:
> LSS %>% group_by(prof, zl, ora) %>% count() %>% filter(n > 1) # A tibble: 0 × 4 (zero linii)
Acum în "orar2.RDS" avem toate datele care fuseseră vizualizate în tabelele PDF inițiale (exceptând numele profesorilor, codificate acum după disciplinele principale), organizate pe variabile independente prof|ora|cls|zl (putem renunța la variabila obj, dat fiind că valorile acesteia se deduc din codurile prof și dintr-un dicționar ușor de construit, pentru disciplinele secundare pe care sunt încadrați unii profesori).
Folosind operațiile uzuale cu seturi de date (filtrare, grupare, etc.) putem afla acum, orice informații dorim despre orarul școlii respective.
Constatăm de exemplu, că distribuția pe zile a lecțiilor este acceptabilă în privința omogenității (cu diferență de cel mult 7 ore, de la o zi la alta):
> addmargins(table(LSS$zl)) Lu Ma Mi Jo Vi Sum 235 238 236 231 232 1172
Împărțind lecțiile pe zile, transformând (prin funcția anterioară hourly_matrix()) orarul fiecărei zile, din formatul lung, în formatul de matrice-orară și folosind funcții din programul anterior "Gaps.R" — putem afla câte ferestre există în orarul respectiv:
ldz <- map(Zile, function(z) LSS %>% filter(zl == z) %>% select(prof,cls,ora) ) %>% setNames(Zile) # lista distribuțiilor pe fiecare zi mORR <- map(ldz, hourly_matrix) > sapply(mORR, count_gaps) Lu Ma Mi Jo Vi 7 13 11 14 16 # în total, 61 de ferestre
Iar prin programul de reducere a ferestrelor din [3] putem realoca pe ore lecțiile respective, astfel încât să avem mai puține ferestre decât erau în orarul inițial:
05:39:45 Lu (7 ferestre) 6 5 4 * 4 05:39:51 (469 mutări) 05:39:51 Ma (13 ferestre) 12 11 10 9 8 7 6 * 6 5 * 5 * 5 * 5 * 5 05:40:28 (984 mutări) 05:40:28 Mi (11 ferestre) 10 9 * 9 * 9 * 9 * 9 * 9 05:41:05 (2066 mutări) 05:41:05 Mi (11 ferestre) 10 9 * 9 8 * 8 * 8 * 8 * 8 05:41:41 (2004 mutări) 05:41:41 Jo (14 ferestre) 13 12 10 9 8 7 * 7 * 7 * 7 * 7 * 7 05:42:16 (1790 mutări) 05:42:16 Vi (16 ferestre) 15 14 13 12 10 9 8 7 6 * 6 * 6 * 6 * 6 * 6 05:42:59 (3573 mutări)
În locul orarului inițial, cu 61 de ferestre, avem acum un nou orar (pentru aceleași lecții prof|cls), care are numai 30 de ferestre (4 5 8 7 6); de observat că execuția programului respectiv a durat în total cam 3 minute.
vezi Cărţile mele (de programare)