Încă un experiment, pe orarul unei școli (I)
[1] Problema orarului școlar echilibrat și limbajul R
[2] V. Bazon - Orare școlare echilibrate și limbajul R https://books.google.ro/books?id=aWrDEAAAQBAJ
Ca și în [1], preluăm critic orarul unei școli; extragem datele de încadrare, le analizăm și le structurăm după [2], apoi aplicăm iarăși programele respective până ce ajungem la un nou orar, echilibrat și cu număr redus de ferestre; deosebirea… constă măcar în faptul că acum apar și cuplaje de trei profesori, la anumite clase și discipline (pe de altă parte, detaliem mai bine probabil, unele aspecte de lucru).
Asupra unor defecte de prezentare și rele practici (tipice)
Orarul este prezentat pe site-ul colegiului respectiv, în două fișiere PDF: "ORAR-CLASE-GIMNAZIU-..." și "ORAR-CLASE-LICEU-...". În ambele fișiere, fiecare pagină reprezintă în format "A4, landscape", orarul câte uneia dintre clase, după un același șablon grafic:
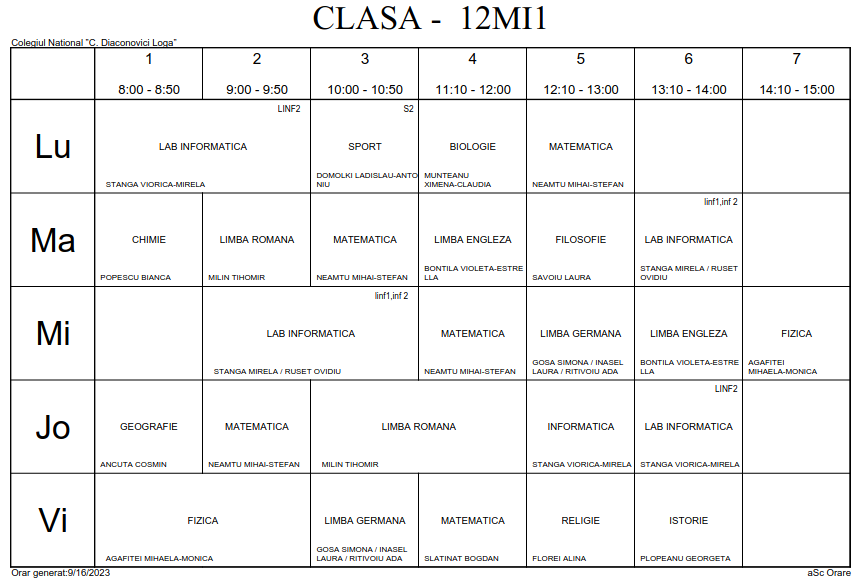
Inspectând "Document Properties", găsim "PDF Producer: Microsoft: Print To PDF"; deducem că orarele claselor au fost editate cumva în Microsoft-Word (și s-a folosit în final meniul acestuia "Print To PDF"). Dar editând pe un șablon fixat în Microsoft-Word, apar diverse defecte tipografice, între care și cel mai nedorit: numele care nu încape în celulă trebuie despărțit cumva pe două rânduri (Un exemplu tipic: pe un rând BONTILA VIOLETA-ESTRE și pe rândul următor, LLA. Un exemplu hilar: singur pe un rând, EDUCATIE, dedesubt – un rând cu mai multe discipline, iar pe al treilea rând, singur, completarea "educației" TEHNOLOGICA). Recuperarea informației de nume, ca dată indivizibilă, devine atunci dificilă.
Neplăcerile (specifice Windows-ului) legate de folosirea diacriticelor, se ocolesc de obicei prin „rele practici”: pentru nume (de discipline și de profesori) se folosesc numai literele standard majuscule. Ne vor interesa, numele disciplinelor (și le vom simplifica decent) – dar vom ignora alte nume: declarăm că numele personale care apar pe aici au fost generate aleatoriu, fără legătură cu datele reale (în fond… chiar sunt false, fiind scrise (funcționărește) cu majuscule și fără litere românești).
În [2] chiar am generat un set de nume aleatorii, cu care am înlocuit numele reale; de această dată am ales să ne scutim de acest efort inutil…
Vedem în antetul fiecărei pagini că orarul a fost generat prin aplicația "aSc Orare" – clonă SIVECO a aplicației de la ascTimetables; este de înțeles că aplicația comercială originală, fiind destinată școlilor din oricare parte a lumii, a lăsat în seama utilizatorilor sarcina de a edita după caz, rezultatele finale (propunându-le niște șabloane minimale) – dar nici SIVECO (chit că pe banii Ministerului) nu și-a bătut capul pentru a asigura totuși (utilizatorilor "point-and-click") o formulare decentă (fără defecte tipografice) a orarului produs…
Pe de altă parte, ar trebui să fie clar că a te ocupa de orarul școlii nu este o sarcină funcționărească; nu ajunge să apeși pe butoane și să tastezi cum-necum, fără gândire, ce-ți cere un meniu sau altul – se cere în primul rând să înțelegi ce-s acelea date de introdus în program și măcar, să stăpânești normele lingvistice și tipografice uzuale. În principiu… cine nu simte că dacă ai tastat deja "CLASA - 12MI1" atunci va trebui să tastezi "CLASA - 12MI2" și nu "CLASA - 12 MI2", trebuie scutit imediat, fără explicații inutile, de sarcina de a se ocupa de orarul școlii.
Am descărcat fișierele respective – numite după șablonul "ORAR*" – în subdirectorul nou ~/23oct/CDL și folosind Ghostscript, le-am reunit într-un nou fișier, CDL.pdf:
vb@Home:~/23oct/CDL$ gs -sDEVICE=pdfwrite -o CDL.pdf `ls ORAR*`
(desigur, în CDL.pdf s-a înregistrat acum "PDF Producer: GPL Ghostscript 9.55")
Ne interesează nu liniatura și grosimea de linie, nici fontul și mărimea de caracter, sau eventualele culori aplicate ici și colo – ci datele conținute în CDL.pdf.
Datele respective sunt valori textuale indivizibile care reprezintă fie zilele de lucru (Lu, Ma, ..., Vi), fie orele unei zile de lucru (1..7), fie clasele și profesorii școlii, fie disciplinele școlare (fie eventual, anumite săli speciale sau spații anexe ale clădirii școlare).
Dar vom avea de descoperit încă o categorie de date, greu de dedus doar vizualizând fișierul PDF; vedem într-adevăr, că există anumite cuplaje de profesori – de exemplu, la clasa 12MI1 redată mai sus, orele de "LIMBA GERMANA" sunt partajate „pe grupe” între trei profesori; însă este cam greu să depistezi doar filând documentul PDF, cum stau lucrurile de fapt: lucrează fiecare dintre cei trei doar cu câte o grupă a acelei clase, sau cumva aceste grupe sunt cuplate în orele respective cu grupe ale unor alte clase?
Putem lămuri lucrurile, analizând datele primare pentru zi, oră, clasă, profesor și obiect.
Extragerea datelor din fișierul PDF (I)
"Portable Document Format" vizează numai formatul documentului final, asigurând că acesta va fi redat „la fel” pe orice dispozitiv sau sistem de redare; nu există „structuri de date” (precum "table" din HTML, de exemplu), redarea fiind bazată pe fluxuri de instrucțiuni care cer pentru fiecare caracter, text arbitrar, sau imagine, precizarea poziției (x,y) în pagină (plus parametri de font și de transformare – rotire, scalare, etc.), coordonate care la redarea documentului vor fi corelate cumva cu rezoluția dispozitivului respectiv.
De aceea, extragerea datelor dintr-un fișier PDF este dificilă și impune angajarea unor programe sau pachete specializate (complexe) și adesea într-o a doua etapă, o muncă mai mult sau mai puțin laborioasă de ajustare a rezultatelor.
În cazul nostru, putem folosi iarăși Ghostscript:
vb@Home:~/23oct/CDL$ gs -sDEVICE=txtwrite -o CDL.txt CDL.pdf
În CDL.txt s-au extras elementele de text existente în CDL.pdf (de exemplu, în PDF "Lu" apare mărit, iar în .txt avem doar textul obișnuit "Lu"), păstrând totuși alinierea orizontală din PDF a acestora (pe verticală, alinierea este „aproximată” față de PDF, fiind mai greu de păstrat):

Ca editor de text, noi ne-am obișnuit cu gedit, fixat pe "the system fixed width font (Monospace 10)" și pe o anumită lățime a ferestrei de editare (…cu riscul de a fi acuzat de „rele practici”); însă liniile din CDL.txt sunt prea lungi și nevrând să modificăm pentru acest caz, proprietățile stabilite pentru gedit – am deschis CDL.txt în Mousepad ("a simple text editor for the Xfce desktop environment"), pentru care am setat ca font "DejaVu Sans Mono Book 8" și maximizând fereastra de editare, am putut vedea în întregimea lor, toate liniile (fiindu-ne astfel mai ușor să le edităm). Am redat aici ca imagine PNG, secvența de linii 744..771, corespunzătoare orarului clasei 12MI1 (a compara cu pagina PDF a clasei, redată mai sus).
Nu ne interesează liniile de „antet” 745 ("Colegiul ...") și 771 ("Orar generat...") și nici intervalele orare din linia 747 ("8.00 - 8.50 ..."); o să eliminăm liniile respective, din orarele tuturor claselor din CDL.txt.
Putem constata în diverse moduri, că liniile din CDL.txt se termină cu "\r\n"; lucrând pe un sistem Linux – preferăm să înlocuim cu "\n" (ștergând "\r").
S-a folosit – cum este normal – un singur spațiu, pentru a separa pe un același rând, elementele unui nume de profesor (nume și prenume), sau de disciplină. În CDL.txt (în urma acțiunii lui txtwrite) separarea între coloane vecine este indicată printr-o secvență de cel puțin două spații, dar… nu totdeauna: de exemplu, în linia 766 "STANGA-VIORICA-MIRELA" din ora a 5-a este separat de numele din ora a 6-a printr-un singur spațiu; deci va trebui să căutăm aceste excepții de separare a coloanelor vecine, lărgind separarea – pentru a putea ulterior să împărțim corect datele de pe fiecare linie, pe orele zilei.
Cu sed, awk sau perl este ușor să corectăm cele trei aspecte evidențiate mai sus, cam așa:
sed 's/\r$//' CDL.txt > cdl.txt # terminatorul de linie devine "\n" awk '{if($0 ~ /Colegiul|8:00/) {next} else {if($0 ~ /Orar generat/) print "\n"; else print}}' \ cdl.txt > CDL.txt # s-au eliminat antetele perl -pi -e 's/(-\w+) (\w+)/$1 $2/g' CDL.txt # lărgește separarea
Subliniem că, prin efectul comenzii awk de mai sus, orarele de clasă consecutive în CDL.txt sunt separate acum printr-un rând liber (facilitând editarea manuală – altfel, un rând inutil).
Mai departe însă, cel mai simplu este să operăm „manual”, folosind facilitățile "Find and Replace..." ale editorului de text; de exemplu, înlocuim astfel toate aparițiile "BONTILA VIOLETA-ESTRE" cu "BONTILA VIOLETA-ESTRELLA" (și apoi ștergem "LLA" pe rândul dedesubt).
Desigur, unele înlocuiri (nu neapărat necesare) le putem face folosind iarăși sed, awk sau perl. De exemplu, eliminăm peste tot "CLASA - ", lăsând numai numele de clasă; eliminăm liniile care conțin numai numele zilei ("Lu", "Ma", etc.); eliminăm spațiile de la început, pe fiecare linie; fixăm separarea datelor din coloane vecine la câte 4 spații, sau chiar numai două; eliminăm liniile care indică doar săli de clasă (având credința că programele din [2] nu vor plasa într-o aceeași oră a zilei mai multe lecții de "LAB INFORMATICA" sau de "SPORT" decât numărul care pare suficient, al sălilor în care s-ar desfășura acestea).
Precizăm că eliminarea spațiilor inițiale și fixarea la două spații (în loc de „cel puțin două”) a separării între „coloane”, nu este deloc necesară pentru cele ce urmează; am procedat astfel doar pentru a prezenta decent, mai jos, orarul desprins din CDL.txt al clasei 12MI1.
Orarul fiecărei clase se reduce astfel la exact 12 linii, cum pozăm aici:

Pe prima linie avem numele clasei. Pe a doua line avem orele zilei (probabil că unele clase au mai puțin de 7 ore pe zi). Pe liniile 3 și 4 avem orarul pentru ziua "Lu": pentru fiecare oră a zilei, pe linia 3 avem disciplinele, iar pe linia 4 avem profesorii corespunzători.
Pe liniile 5 și 6 – orarul zilei "Ma", ș.a.m.d.
Subliniem că am introdus simbolul "=" pentru cazul când clasa este liberă în ora respectivă; astfel, în ziua Mi clasa 12MI1 își începe programul zilnic de la a doua oră a zilei – deci pe liniile 7 și 8 dintre cele 12 redate mai sus, avem pentru prima oră "=" (în loc de disciplină, și respectiv în loc de profesor).
În cazul cuplajelor de profesori la clasă, am înlocuit separatorul " / " cu "/".
Fiindcă orarul fiecărei clase cuprinde exact 12 linii, linia albă care separă un orar de cel următor devine inutilă; eliminăm liniile albe din CDL.txt (ținând seama că '^' și '$' desemnează începutul și sfârșitul unei linii; 'd' vine de la "delete"):
sed -i '/^$/d' CDL.txt
Acum, CDL.txt este suficient pregătit pentru a permite extragerea și structurarea datelor pe clase, zile, ore, discipline și profesori (și cuplaje, de profesori).
Extragerea datelor din fișierul PDF (II)
Orarul este în fond un set de date, încât este firesc să folosim limbajul R pentru a-l structura, explora și analiza (ba chiar, cum vom vedea mai încolo și pentru a-l genera, plecând de la datele de încadrare).
În următorul program R, constituim întâi vectorul Lines având ca elemente (de tip char) cele 384 de linii din fișierul CDL.txt (fiind 12 linii de fiecare clasă, rezultă că avem 32 de clase).
Cu grupurile consecutive de câte 12 linii din Lines, constituim Lines.cl (de tip list); în Lines.cl[[i]] avem cele 12 linii din Lines, corespunzătoare clasei a i-a (i=1:32):
# extract.R library(tidyverse) Lines <- readLines("CDL.txt") # 384 linii de text (32 clase × 12 linii) Lines.cl <- map(1:32, function(i) Lines[(12*i-11):(12*i)]) Zile <- c("Lu", "Ma", "Mi", "Jo", "Vi")
Formulăm funcția txt2DF(), care primește setul de 12 linii ale orarului uneia dintre clase și returnează un „tabel” (obiect de tip data.frame) în care sunt extrase datele din liniile respective, pe 5 coloane (profesor, obiect, zi, ora, clasa):
txt2DF <- function(L_cl) { Q <- L_cl %>% str_trim(., side="both") %>% str_split(., "\\s{2,}") no <- length(Q[[2]]) # numărul maxim de ore pe zi, ale clasei for(i in 3:12) { Li <- Q[[i]] if(length(Li) == no) next while(length(Li) < no) Li <- c(Li, NA) # completează când este cazul, cu valori NA Q[[i]] <- Li } map_dfr(seq(3, 11, by=2), function(i) list2DF(list( prof = Q[[i+1]], obj = Q[[i]], zi = rep(Zile[i %/% 2], no), ora = 1:no)) ) %>% mutate(cls = str_remove_all(Q[[1]], " ")) }
Am eliminat din fiecare linie, spațiile inițiale și finale și apoi am ținut seama de faptul că datele din coloane vecine sunt separate între ele printr-o secvență de cel puțin două spații; prin str_split() am transformat șirurile de caractere în vectori, asigurându-ne apoi (prin completare cu valori NA, când este cazul) că aceștia au același număr de componente – altfel n-am putea aplica list2DF() – egal cu numărul maxim de ore pe zi ale clasei.
Apoi, prin map_dfr() și list2DF() transformăm listele de vectori într-un data.frame, conținând toate datele orarului clasei (pe 7×5=35 de linii) – cum exemplificăm aici:
vb@Home:~/23oct/CDL$ R -q > source("extract.R") > txt2DF(Lines.cl[[27]]) prof obj zi ora cls 1 STANGA VIORICA-MIRELA LAB INFORMATICA Lu 1 12MI1 2 STANGA VIORICA-MIRELA LAB INFORMATICA Lu 2 12MI1 3 DOMOLKI LADISLAU-ANTONIU SPORT Lu 3 12MI1 4 MUNTEANU XIMENA-CLAUDIA BIOLOGIE Lu 4 12MI1 5 NEAMTU MIHAI-STEFAN MATEMATICA Lu 5 12MI1 6 <NA> <NA> Lu 6 12MI1 7 <NA> <NA> Lu 7 12MI1 8 POPESCU BIANCA CHIMIE Ma 1 12MI1 9 MILIN TIHOMIR LIMBA ROMANA Ma 2 12MI1 10 NEAMTU MIHAI-STEFAN MATEMATICA Ma 3 12MI1 11 BONTILA VIOLETA-ESTRELLA LIMBA ENGLEZA Ma 4 12MI1 12 SAVOIU LAURA FILOSOFIE Ma 5 12MI1 13 STANGA MIRELA/RUSET OVIDIU LAB INFORMATICA Ma 6 12MI1 14 <NA> <NA> Ma 7 12MI1 15 = = Mi 1 12MI1 16 STANGA MIRELA/RUSET OVIDIU LAB INFORMATICA Mi 2 12MI1 17 STANGA MIRELA/RUSET OVIDIU LAB INFORMATICA Mi 3 12MI1 18 NEAMTU MIHAI-STEFAN MATEMATICA Mi 4 12MI1 19 GOSA SIMONA/INASEL LAURA/RITIVOIU ADA LIMBA GERMANA Mi 5 12MI1 20 BONTILA VIOLETA-ESTRELLA LIMBA ENGLEZA Mi 6 12MI1 21 AGAFITEI MIHAELA-MONICA FIZICA Mi 7 12MI1 #### ETC. (35 linii de date)
Subliniem că sunt de eliminat linii ca 6, 7, 14 (care conțin NA), introduse numai pentru a avea pe toate zilele un același număr de ore (putând astfel să folosim list2DF(), mai sus); deasemenea, sunt de eliminat liniile ca 15, care conțin "=" (prin care marcasem derogarea de la prima oră, a programului clasei pe ziua respectivă).
Coloana cls pare a ține de „rele practici”: avem o aceeași valoare "12MI1", pe toate cele 35 de linii. Dar intenția era aceea de a aplica funcția txt2DF() pe toate clasele (ale căror orare de câte 12 linii le înregistrasem mai sus în lista Lines.cl) și a sintetiza rezultatele într-un singur „tabel” (din care eliminăm liniile cu valori "NA" sau "="):
CDL <- map_dfr(Lines.cl, txt2DF) # 1120 linii (32 clase × 5 zile × 7 ore/zi) CDL <- CDL %>% filter(!is.na(prof) & prof != "=") # 928 linii (pe 5 variabile) saveRDS(CDL, file="CDL_orig.RDS")
Fișierul rezultat CDL_orig.RDS are 928 de linii, reprezentând toate lecțiile pe care profesorii sau cuplajele de profesori le au de făcut în cursul săptămânii, împreună cu informații de localizare pe zile și ore din zi, ale acestora. Dacă excludem „localizarea” pe zile și ore – rămânem cu datele de încadrare: care profesor sau cuplaj de profesori trebuie să intre la o clasă sau alta (eventual, de mai multe ori) în cursul săptămânii.
Orice investigație dorim, va decurge folosind operații de filtrare (pentru linii de valori) și de selectare (de variabile, sau coloane) – iar pentru facilitare, putem transforma o coloană sau alta în factor (ceea ce asigură și operații de grupare și „splitare”). De exemplu,
CDL %>% filter(obj == "FIZICA") %>% select(prof, cls, zi) %>% arrange(prof, zi)
produce repartiția pe zile a lecțiilor de FIZICA (ordonate după prof și zi).
Având astfel datele, putem începe să ne ocupăm de programe pentru investigarea și analizarea acestora, sau pentru a genera pe seama lor diverse alte seturi de date.
Simplificări…
Trecând la programe, lucrurile încep să depindă de gusturi (și de experiență)…
Poate că nu este necesar să „simplificăm” datele – dar este mai ușor (și mai eficient) de lucrat cu nume scurte (și cu dicționare corespunzătoare), decât cu nume lungi.
Inițiem un „program de simplificări” – în care vom folosi în diverse scopuri și comenzi interactive, prin consola R (indicate prin prompt-ul '>' și o mărime de caracter ceva mai mică, decât cea folosită pentru redarea programului propriu-zis):
# adjust.R rm(list = ls()) # elimină obiectele din sesiunea precedentă library(tidyverse) CDL <- readRDS("CDL_orig.RDS")
Nu mai avem nevoie de vectorul Lines, sau de funcția txt2DF(), din sesiunea de lucru anterioară – așa că le-am eliminat din memorie.
Se cuvine poate, să ne împrospătăm starea curentă a lucrurilor:
> slice_sample(CDL, n=3) # un eșantion de date, aleatoriu prof obj zi ora cls 1 SAMFIRESCU ISABELA SPORT Lu 6 8B 2 COSTEA CORINA-LUCIA LIMBA ROMANA Mi 4 11SS 3 SPINEANU CLAUDIA-ILEANA LIMBA ROMANA Ma 1 10M2
În loc de "LIMBA ROMANA" ne alege Română; în loc de "10M2" am alege 10B; în loc de "SPINEANU CLAUDIA-ILEANA" am alege probabil R02, unde "R" indică disciplina ("Română"), iar "02" ține de ierarhia după numărul de ore pe care sunt încadrați profesorii la acea disciplină.
Dicționarul claselor
Notația "12MI1" este foarte bună: indică nu numai nivelul (12, sau „clasa a XII-a”), dar și profilul clasei (de „Matematică-Informatică”). Totuși, preferăm o notație unitară a claselor.
Următoarea funcție produce dicționarul dorit pentru clase:
dict_cls <- function() { Cls <- CDL$cls %>% unique() Niv <- str_extract(Cls, "^\\d+") spc <- split(Cls, Niv) dct <- vector() for(i in 1:length(spc)) { niv <- names(spc)[i] ncl <- length(spc[[i]]) d <- paste0(niv, LETTERS[1:ncl]) # d <- spc[[i]] names(d) <- spc[[i]] # names(d) < paste0(niv, LETTERS[1:ncl]) dct <- c(dct, d) } dct }
Dacă am fi tastat în consolă comenzile din corpul funcției, rând pe rând – atunci puteam să vizualizăm rezultatele (servind înțelegerii mecanismului); de exemplu, puteam constata că în 'spc' rezultă o listă care asociază fiecărui nivel vectorul claselor de pe acel nivel:
> str(spc) List of 8 $ 10: chr [1:6] "10M1" "10M2" "10SN1" "10SN2" ... # vectorul claselor a zecea $ 11: chr [1:6] "11M1" "11M2" "11SN1" "11SN2" ... $ 12: chr [1:6] "12MI1" "12MI2" "12SN1" "12SN2" ... $ 5 : chr [1:2] "5A" "5B" $ 6 : chr [1:2] "6A" "6B" $ 7 : chr [1:2] "7A" "7B" $ 8 : chr [1:2] "8A" "8B" $ 9 : chr [1:6] "9MI1" "9MI2" "9SN1" "9SN2" ...
(Iar folosind la promptul consolei '?' sau help(), putem obține informații despre orice element al limbajului; de exemplu ? LETTERS, sau help(split), sau ? str_extract, etc.)
Desigur, ambalând comenzile respective într-un obiect "function", evităm poluarea spațiului de lucru cu variabilele implicate (Cls, Niv etc.).
Rezultă acest dicționar (un "named vector", sau "„vector cu nume”):
> source("adjust.R") > D <- dict_cls(); print(D) 10M1 10M2 10SN1 10SN2 10SS 10F 11M1 11M2 11SN1 11SN2 11SS 11F 12MI1 "10A" "10B" "10C" "10D" "10E" "10F" "11A" "11B" "11C" "11D" "11E" "11F" "12A" 12MI2 12SN1 12SN2 12SS 12F 5A 5B 6A 6B 7A 7B 8A 8B "12B" "12C" "12D" "12E" "12F" "5A" "5B" "6A" "6B" "7A" "7B" "8A" "8B" 9MI1 9MI2 9SN1 9SN2 9SS 9F "9A" "9B" "9C" "9D" "9E" "9F"
Să modificăm (direct, din consolă) conform dicționarului D, numele de clasă de pe cele 928 de linii din CDL; pentru aceasta, transformăm coloana CDL$cls în "factor" (v. [3], pentru „clase de echivalență” și factori) și modificăm vectorul asociat acestuia de funcția levels():
> CDL <- CDL %>% mutate(cls = factor(cls)) > lv <- levels(CDL$cls) > levels(CDL$cls) <- D[lv] %>% as.vector()
Subliniem că a fost necesar să accesăm D după vectorul lv, fiindcă factor() enumerase clasele în ordine alfabetică (10F, 10M1, 10M2, 10SN1, etc.) – diferită de cea din D.
Iată și o mică verificare:
> sample(CDL$cls, size=10) # 10 valori arbitrare, dintre cele 928 [1] 10B 11B 9C 7A 5B 9E 5B 12E 9E 9A 32 Levels: 10F 10A 10B 10C 10D 10E 11F 11A 11B 11C 11D 11E 12F 12A 12B ... 9E
Desigur, când va fi să afișăm orarul va trebui probabil să trecem înapoi, de la "10A", "10B" etc., la denumirile inițiale "10M1", "10M2" etc. În acest scop, inversăm între ele numele și valorile din D și salvăm pe disc noul dicționar rezultat astfel:
> dcl <- names(D) |> setNames(as.vector(D)) > saveRDS(dcl, "dict_clase.RDS") > sample(dcl, size=8) # pentru o mică verificare 9E 9F 10C 6B 11F 10A 11D 12F "9SS" "9F" "10SN1" "6B" "11F" "10M1" "11SN2" "12F"
De observat că puteam obține acest dicționar „invers” direct din funcția dict_cls(), setând variabila d conform celor două linii comentate mai sus în corpul funcției.
Precizăm că '%>%' și '|>' sunt operatori "pipe": comanda din dreapta acționează pe rezultatele returnate de comanda din stânga operatorului.
Dicționarul disciplinelor
—v. partea a II-a—
vezi Cărţile mele (de programare)