Mofturile repartizării lecţiilor (V)
[1] De capul meu prin problema orarului şcolar (pe Google Play; v. extras)
[2] Mofturile repartizării lecţiilor (IV..I)
În distribuția pe zile rezultată în [2], avem (spre deosebire de [1]) și clase ale căror lecții sunt distribuite neuniform; ar fi de încropit un program prin care să automatizăm cumva (spre deosebire de [2]), derularea operațiilor de omogenizare (pe clase și implicit, pe profesori și zile).
Ideea cea mai simplă ar fi aceasta: pentru fiecare clasă cu distribuție neomogenă, fie z1 și z2 două zile în care clasa are cel mai mare și respectiv, cel mai mic număr de ore; se afișează profesorii cu ore la clasă în ziua z1, dar fără ore la clasă în ziua z2 (împreună cu distribuțiile acestora) și se cere utilizatorului să tasteze indexul aceluia dintre acești profesori, la care să se mute lecția din z1, în z2; se apelează change_zl() pentru a muta lecția indicată și apoi, programul va trece la următoarea clasă:
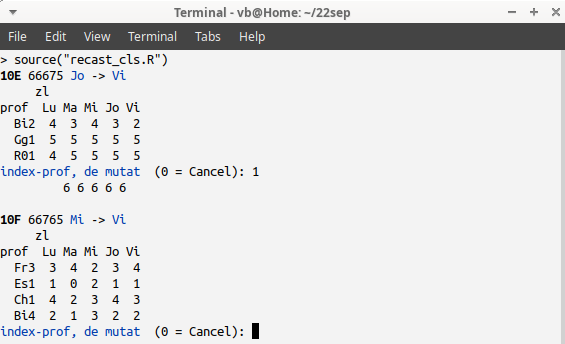
10E are distribuția inițială 66675, deci z1 este Jo și z2 este Vi; în R1 – distribuția pe zile a lecțiilor necuplate – avem 3 profesori cu ore la 10E în ziua Jo, dar nu și în ziua Vi; dintre aceștia, Gg1 și R01 au în momentul curent, distribuții individuale uniforme (și bineînțeles că nu vrem să le „stricăm”) – încât alegem să mutăm lecția lui Bi2, tastând indexul 1.
La 10E rezultă atunci distribuția uniformă 66666; distribuția lui Bi2 devine 43423 și aceasta (nu cea inițială) va trebui văzută când programul va avansa la următoarele clase. Sunt mari șanse să putem omogeniza ulterior, distribuția lui Bi2 – întâlnind o clasă la care să fie convenabil să mutăm pe Jo, ora lui Bi2 din ziua Lu, sau din ziua Mi.
Pentru evidențierea unora dintre datele afișate (prin boldare sau colorare), am invocat direct vreo două funcții din pachetul cli (v. CRAN).
Iată întregul program, în versiunea aparent modestă, când se vizează numai clasele cu cea mai simplă formă de distribuție neuniformă (ca mai sus, la 10E și 10F):
# recast_cls.R library(tidyverse) Zile <- c("Lu", "Ma", "Mi", "Jo", "Vi") load("R1R2.Rda") # importă distribuțiile inițiale R1 <- R1 %>% mutate(prof = as.character(prof)) Cls <- unique(R1$cls) # R1 (lecțiile necuplate) conține toate clasele cls_hours <- function(cls_name) map(list(R1, R2), function(RC) RC %>% filter(cls == cls_name) %>% count(zl, .drop=FALSE) %>% pull(n) ) %>% list2DF() # alocarea pe zile a orelor clasei, în distribuţiile curente R1, R2 change_zl <- function(P, Q, Z, new_zl, RC) { RC[with(RC, prof==P & cls==Q & zl==Z), "zl"] <- new_zl RC } # alocă o lecţie într-o altă zi, returnând distribuţia modificată prof_in_one_day <- function(Cls, z1, z2, RC) { Q <- RC %>% filter(cls == Cls & zl %in% c(z1, z2)) %>% droplevels() %>% split(.$zl) P1 <- Q[[z1]]$prof P2 <- Q[[z2]]$prof P1[! P1 %in% P2] } # cei cu ore la Cls în z1, dar nu și în z2 cls_to_recast <- function() { map_dfr(Cls, function(Q) { H <- cls_hours(Q) |> rowSums() if(diff(range(H)) <= 1) return(NULL) dh <- sort(H) |> diff() if(dh[1] == 0 | dh[4] == 0 | any(dh[2:3] > 0)) return(NULL) data.frame(cls = Q, Lu=H[1], Ma=H[2], Mi=H[3], Jo=H[4], Vi=H[5]) }) } # clasele cu distribuții de un anumit tip, în R1+R2 curentă input_id <- function() { cat(cli::col_blue("index-prof, de mutat "), "(0 = Cancel): ") return(readLines("stdin", n=1) |> as.integer()) } # "citește de la tastatură" un index întreg KR <- cls_to_recast() for(Q in KR$cls) { H <- cls_hours(Q) |> rowSums() # apply(cls_hours(Q), 1, sum) z1 <- Zile[which.max(H)] z2 <- Zile[which.min(H)] P <- prof_in_one_day(Q, z1, z2, R1) NH <- table(R1[c('prof', 'zl')])[P, ] cat(cli::style_bold(Q), paste0(H,collapse=""), cli::col_blue(z1), "->", cli::col_blue(z2), "\n") print(NH) id <- input_id() if(id & id <= nrow(NH)) { R1 <- change_zl(row.names(NH)[id], Q, z1, z2, R1) cat('\t', cls_hours(Q) |> rowSums(), '\n\n') } }
Ar fi de făcut multe precizări sau sublinieri… De ce am convertit la character R1$prof (chiar la începutul programului)? În principal, fiindcă dacă rămânea factor – atunci rezultatul întors de table() ar fi păstrat levels(prof), încât subsetul NH introdus mai spre sfârșitul programului devenea „corupt” (și aveam rezultate greșite).
Pe de altă parte, R2$prof este deja de tip character (nu factor).
De ce n-am convertit la character și $zl? În principal, fiindcă s-ar fi schimbat ordinea firească a zilelor (prima zi ar fi Jo și nu Lu).
De ce în cls_hours(), am invocat count(zl, .drop=FALSE) (și nu simplu, count(zl) – ca în [2])? Prin cls_hours() vrem un tabel cu două coloane, reprezentând numărul de ore pe fiecare zi din R1 și respectiv din R2, la clasa indicată; dar pot exista clase care nu au lecții cuplate, într-o zi sau alta:
> cls_hours("6A") zl în R1 în R2 1 5 2 # Lu: 5 lecții necuplate și 2 lecții "pe grupe" 2 5 0 3 5 0 4 5 0 5 5 2
Fără .drop=FALSE, rezultatul ar fi fost greșit: count(zl) ar fi ignorat zilele care lipsesc, producând pentru R2 vectorul "2 2", care pentru a-l alipi apoi primei coloane ar fi fost extins la "2 2 2 2 2" (ducând la compromiterea definitivă a programului). Setând .drop=FALSE, cerem funcției count() să nu ignore valorile care lipsesc (înscriind '0', în aceste cazuri).
De ce în prof_in_one_day(), după filtrare am folosit droplevels() și apoi, split(.$zl)? Fără droplevels(), ar fi rezultat o listă cu 5 componente (după nivelele factorului $zl), în loc de numai cele pentru z1 și z2.
De ce am selectat apoi prin Q[[z1]] și Q[[z2]] și nu mai simplu, prin Q[[1]] și Q[[2]]? Fiindcă $zl este factor ordonat și dacă am apela cu z1="Jo" și z2="Ma" de exemplu, atunci Q[[1]] ar corespunde zilei Ma (nu lui z1) – ordinea zilelor fiind cea fixată în vectorul Zile. Ordinea este aici esențială: vom avea de mutat o oră din ziua z1, în ziua z2.
De subînțeles desigur, că prof_in_one_day() așteaptă în parametrii z1 și z2 valori din Zile (de exemplu "Jo", nu indexul 4).
De ce (prin P1[!P1 %in% P2]) am selectat numai pe cei care la clasa respectivă au ore în z1, dar nu și în z2? Pentru a evita în principiu, ca profesorii să aibă mai mult de o singură oră pe zi, la o aceeași clasă.
De observat că am folosit în câteva ocazii, noul operator '|>' forward pipe (pe lângă cel frecvent folosit pe aici, '%>%'); deci versiunea de R pe care ar putea fi executat programul de mai sus, trebuie să fie cel puțin 4.1.
În cls_to_recast() am preferat să instrumentăm cazul cel mai simplu de distribuție neuniformă a lecțiilor clasei: există o singură valoare maximă și o singură valoare minimă, iar celelalte valori sunt egale. De observat însă că pentru cazul general, al unei distribuții oarecare – n-am avea nimic „de instrumentat” (și cls_to_recast() se banaliza).
cls_to_recast() furnizează tabelul distribuțiilor claselor respective – dar acesta are doar rol informativ (mai departe în program se folosește doar coloana $cls): putem vedea pe parcurs, după diverse modificări de alocare a zilelor (efectuate pe R1 sau pe R2), la care clase (și profesori) mai avem de uniformizat distribuțiile respective.
Uniformizarea acelor distribuții neuniforme care sunt de cel mai simplu tip este relativ ușor de făcut (cum am arătat mai sus pentru clasa 10E) și este de așteptat ca, după ce vom încheia cu clasele de acest tip – să putem uniformiza relativ ușor și celelalte clase, cu distribuții neuniforme mai complicate.
De ce să devină mai ușor, pentru celelalte clase? Pentru că, prin uniformizarea distribuțiilor claselor precedente, în mod implicit am uniformizat și o parte dintre distribuțiile individuale corespunzătoare profesorilor implicați în mutările de zile efectuate (astfel că devine mai ușor de ales ulterior, pe cel căruia să-i schimbăm ziua).
Urmărim mereu să nu „stricăm” distribuțiile deja echilibrate, iar noua clasă curentă să capete o distribuție mai echilibrată decât era inițial – vizând o uniformizare „din aproape în aproape”, prin reluarea programului (după extinderea categoriei de distribuții neuniforme, vizate în cls_to_recast()).
Iar dacă înlocuim în program R1 cu R2, reluarea lui ne permite să mutăm lecții cuplate; doar că în acest caz, ar trebui să afișăm niște informații suplimentare – pentru a preveni o mutare prin care profesorul angajat în mai multe cuplaje ar căpăta prea multe ore într-o zi.
O ultimă precizare probabil, ar viza „citirea de la tastatură” într-un program R aflat în execuție: stdin din R are alte principii, decât stdin din C… În principiu, R țintește lucrul interactiv – prin tastarea sau pastarea de comenzi, în consola specifică; iar unele funcții (de exemplu, readline()) trebuie folosite numai în modul interactiv.
Aici am înființat funcția input_id() pentru a prelua prin readLines(), indexul tastat de utilizator (furnizat apoi ca integer); pare simplu și firesc, iar programul funcționează corect (nu se oprește execuția lui, imediat după tastarea indexului cerut la prima clasă) – dar în anumite circumstanțe (pomenite în diverse locuri, în legătură cu funcția readline()), pentru a citi de la tastatură și a continua apoi execuția programului sunt necesare anumite trucuri (de exemplu, se ambalează între acolade secvența de citire de la tastatură – încât R să o vadă ca fiind un singur bloc de cod; altfel, readline() ar vedea ceea ce urmează în program – sau se pastează în consolă – ca făcând parte din "input"-ul cerut).
Programul de mai sus – simplu și flexibil – reduce în bună măsură, necesitatea folosirii aplicației interactive "Recast.html" prin care anterior, omogenizam distribuțiile prin click-uri în tabelul HTML al tuturor lecțiilor și click-uri pe butoanele oferite în fereastra browser-ului.
Desigur, „flexibil” înseamnă că programul poate fi adaptat ușor, vizând R2 în loc de R1, sau vizând un alt tip de distribuție; altfel spus… înseamnă că el ar trebui rescris, parametrizând aceste variante de lucru (dar n-am mai spus? Pentru progres: scrie și rescrie).
vezi Cărţile mele (de programare)