O experiență eșuată, pe "Orarul general clase"
[1] Orar pe o școală fără profesori (I - VI)
[2] V.Bazon - De la seturi de date și limbajul R, la orare școlare (Google Books)
[3] V. Bazon - Orare școlare echilibrate și limbajul R (Google Books)
Repetăm experiența din [1], plecând de la un alt "Orarul general clase", acum adus din PDF-ul original într-un fișier Excel cu formatul fixat ca în acest fragment:
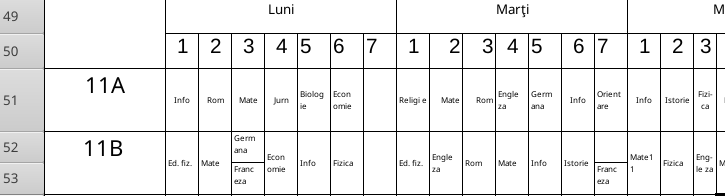
Tabelul are 68 de linii, incluzând în patru locuri linii de antet ca 49-50 mai sus.
Pentru fiecare clasă avem câte unul sau două rânduri de celule, în care sunt înscrise numele disciplinelor școlare alocate în orar fiecărei zile și ore din zi.
Printr-un meniu "Column Width" putem extinde vizual coloanele, încât numele din celule ar încăpea pe un singur rând (ca "Germ ana", în loc de "Germ" plus dedesubt, "ana"; bineînțeles că rămâne să corectăm, "Germană" în loc de "Germ ana", etc.).
Interesul nostru față de acest orar (…dacă nu ni-l pierdem pe parcurs) pleacă de la faptul că numărul de clase (aflate într‑un același schimb, pe orele 1:7 ale zilei) este foarte mare (41 de clase; în [1] aveam numai 34 de clase) și în plus, avem de-a face iarăși, cu simultane complicate; asemenea seturi de date, voluminoase, ne servesc cel mai bine pentru a verifica și a cizela acele proceduri de lucru și funcții pe care le-am elaborat în [3], pentru a constitui orare școlare.
Numai că pentru a construi orarul, avem nevoie de "încadrarea profesorilor", prof|obj|cls|număr_de_ore — ori "prof" lipsește din "Orarul general clase" (…primul motiv pentru care ne-am putea pierde interesul pentru acest "orar"); ca și în [1], întâi vom "inventa" profesorii, în număr minim pentru fiecare disciplină principală, astfel încât ei să-și facă lecțiile conform (aproximativ) orarului pe clase dat.
De la celulele Excel la set de date
Prin meniurile din Excel (noi folosim Gnumeric), exportăm fișierul ".xlsx" inițial, în fișierul "orar_clase.csv", pe care îl deschidem într-un editor de text (noi folosim Gedit) și întâi, ștergem liniile corespunzătoare antetelor de tabel Excel. Apoi ne procurăm un antet CSV decent, prin secvența de comenzi $\mathbf{R}$:
Zile <- c("Lu", "Ma", "Mi", "Jo", "Vi") ant <- lapply(Zile, function(z) paste0(z, 1:7)) antet <- paste(c("cls", unlist(ant)), collapse = ",") print(antet, quote=FALSE) cls, Lu1,Lu2,Lu3,Lu4,Lu5,Lu6,Lu7, Ma1,Ma2,Ma3,Ma4,Ma5,Ma6,Ma7, Mi1,Mi2,Mi3, Mi4,Mi5,Mi6,Mi7, Jo1,Jo2,Jo3,Jo4,Jo5,Jo6,Jo7, Vi1,Vi2,Vi3,Vi4,Vi5,Vi6,Vi7
și-l pastăm (așa cum l-am obținut pe ecran, ca o singură linie, nu cum l-am redat aici) pe prima linie a fișierului CSV.
Pentru unele clase, avem câte două linii de date; de exemplu pentru clasa 11B, pe liniile 52 și 53 din fragmentul Excel redat mai sus, avem (în format CSV):
[52] 11B, "Ed. fiz.", Mate, "Germ ana", "Econ omie", Info, Fizica, , "Ed. fiz.", "Engle za", Rom, Mate, Info, Istorie, , "Mate1 1", Fizica, "Engle za", Mate, Info, "Germ ana", , Fizica, Geo, Rom, "Chimi e", Istorie, , , Mate, Info, "Biolog ie", "Ch-op t", Rom, "Religi e" [53] ,,,"Franc eza",,,,,,,,,,,"Franc eza",,,,,,,,,,,,,,,,,,,,,
Linia a doua începe cu "," (omițând numele clasei) și conține fie câmpuri vide (cu valori "" sau " "), fie disciplina pentru "a doua grupă" când în ora respectivă, clasa este despărțită în grupe. De exemplu, în ora a 3-a din ziua Lu, clasa este despărțită în două grupe; prima face "Germ ana", iar a doua face "Franc eza".
De observat, pe fragmentul Excel redat mai sus, că avem și situații nedorite: în ziua "Marți", ora a 7-a (ultima din zi), prima grupă este liberă, iar a doua face "Franc eza" (iar cea mai nedorită situație este aceea în care este prezentă numai prima grupă; fiindcă pe linia a doua câmpul respectiv este vid, va fi mai greu să depistăm pe baza formatului CSV că este vorba de lecție "pe grupe" și nu pe "întreaga clasă").
Normal ar fi ca ambele grupe să fie prezente simultan, cum vizăm în [3]; acceptând ca numai una dintre grupe să fie prezentă, lecția respectivă trebuie alocată obligatoriu, în ultima oră.
Deocamdată, reformulăm fișierul CSV, comasând cele două linii când este cazul de lecții "pe grupe"; dacă în ora respectivă prima grupă face "obj1" și a doua face "obj2", atunci înlocuim "obj1" de pe prima linie cu "obj1/obj2" (separatorul '/' va indica faptul că avem o lecție "pe grupe" și astfel, nu vom mai avea nevoie de a doua linie); dacă "obj2" lipsește, dar "obj1" este "Franc eza" sau este "Germ ana", atunci înlocuim "obj1" cu "obj1/" (adică numai prima grupă este prezentă):
library(tidyverse) CN <- readLines("orar_clase.csv") wh <- which(grepl('^,+', CN)) # indecșii de "a doua linie" # [1] 23 25 27 29 31 33 35 37 39 41 44 46 48 50 52 55 57 59 for(i in wh) { L1 <- strsplit(CN[i-1], ",")[[1]] L2 <- strsplit(CN[i], ",")[[1]] for(j in 1:length(L2)) if(L2[j] != "") L1[j] <- paste0(L1[j], '/', L2[j]) else { if(grepl("Fr|Ger", L1[j])) L1[j] <- paste0(L1[j], '/') } CN[i-1] <- paste(L1, collapse=", ") } CN <- CN[! grepl('^,+', CN)] write(CN, file="orar_clase.CSV")
În fișierul Excel inițial avem și celule colapsate vizual pe orizontală (însemnând lecții consecutive pe o aceeași disciplină):

Celulele K și L au fost "grupate", apărând ca fiind o singură celulă; dar de fapt, conținutul "Rom" ocupă numai celula K, iar în formatul CSV, grupul respectiv apare ca "Rom,," și nu ca "Rom,Rom," cum ar trebui (însă "gruparea" de celule Excel ține numai de formatare vizuală). Dar avem noroc: sunt numai patru asemenea situații, încât am corectat direct în fișierul CSV, pe liniile claselor respective.
Acum, din fișierul CSV rezultat obținem setul de date CN (un obiect de tip tibble, extensie a tipului obișnuit data.frame), conținând toate lecțiile cls|zl|ora|obj:
Zile <- c("Lu", "Ma", "Mi", "Jo", "Vi") CN <- read.csv("orar_clase.CSV") %>% pivot_longer(2:36, names_to="ziOra", values_to="obj") %>% separate(ziOra, c("zl", "ora"), sep=2) %>% filter(!(is.na(obj) | obj %in% c("", " "))) %>% # ignoră celulele vide mutate(ora = as.integer(ora), zl = factor(zl, levels=Zile, ordered=TRUE)) > str(CN) # 1,191 lecții $ cls: chr [1:1191] "5A" "5A" "5A" "5A" ... $ zl : Ord.factor w/ 5 levels "Lu"<"Ma"<"Mi"<..: 1 1 1 1 1 1 1 2 2 2 ... $ ora: int [1:1191] 1 2 3 4 5 6 7 1 2 3 ... $ obj: chr [1:1191] "Rom" "Istorie" "info-T IC" "Geo" ...
Să ne lămurim pe cât se poate, asupra unor "situații nedorite", de exemplu aceea în care pe ultima oră din zi apare numai una dintre grupele implicate într-o lecție "pe grupe" — ca în acest exemplu:
> c11 <- CN %>% filter(cls == "11C", zl %in% c("Lu","Mi","Jo")) %>% select(-cls) %>% mutate(sp="") > cbind(c11[1:6,], c11[7:12,], c11[13:18,]) zl ora obj sp zl ora obj sp zl ora obj sp 1 Lu 1 Info Mi 1 Info Jo 1 Mate 2 Lu 2 Rom Mi 2 Eng-o pt Jo 2 Chimi e 3 Lu 3 Germ ana/Franc eza Mi 3 Mate1 1 Jo 3 Rom 4 Lu 4 Fizica Mi 4 Mate Jo 4 Eng-o pt 5 Lu 5 Mate Mi 5 Engle za Jo 5 Engle za 6 Lu 6 Ed. fiz. Mi 6 Germ ana/ Jo 6 /Franc eza
Clasa pe care am vizat-o aici, "11C", are Lu|3|"Germ ana/Franc eza" (deci o lecție "pe grupe"), iar Mi și Jo, pe ultima oră, "Germ ana/" și respectiv "/Franc eza"; deci Jo este vorba de a doua grupă a cuplajului respectiv (fiindcă în față apare separatorul de "lecție pe grupe", "/"), iar Mi este vorba de prima grupă.
Dar ca de obicei, lucrurile sunt mai complicate decât par: pe Mi|6 apare "Germ ana/" și la o altă clasă, iar la o a treia clasă, tot Mi|6, găsim "Germ ana/Franc eza"… Cu alte cuvinte, avem de-a face (ca și în [1]) cu anumite tuplaje sau poate simultane — de lămurit mai târziu, după ce vom face anumite simplificări.
Disciplinele școlare (ca date de lucru)
Al doilea motiv de abandonare a interesului pentru vreun orar găsit pe undeva, ține de specificarea disciplinelor școlare; putem admite că în loc de "Germană" apare (oribil) "Germ ana" sau " Germ ana", dar nu putem tolera denumiri multiple pentru câte un același obiect (încât în loc de vreo 25 discipline, vedem 70). Este chiar frapantă, neștiința noțiunii fundamentale de "date" și absența vreunui efort intelectual propriu: orarul s-a produs și prezentat vulgar, manevrând la nivel funcționăresc meniurile aplicației semnate la sfârșit "aSc Orare".
Înițial, avem 78 de "discipline școlare":
> CN$obj %>% unique() %>% length() [1] 78
Eliminând spațiile (avem și " Biolog ie" și "Biolog ie") rămân 55 denumiri:
CN <- CN %>% mutate(obj = str_remove_all(obj, "[ ]")) > CN$obj %>% unique() %>% sort() [1] "/Franceza" "/Muzica" "Bio-opt" [4] "Biologie" "Ch-opt" "Chimie" [7] "Drg" "Economie" "Ed.antr." [10] "Ed.fiz." "Ed.plastica" "Ed.plastica-opt" [13] "Ed.plastica/Muzica" "Ed.soc." "Ed.tehn." [16] "EdS" "Eng-opt" "Engleza" [19] "Filosofie" "Fizica" "Franceza" [22] "Geo" "Geo-opt." "Germana" [25] "Germana/" "Germana/Franceza" "Info" [28] "info-TIC" "Istorie" "Jurn" [31] "Lat-opt" "Latina" "Lct-cr" [34] "Lct-t" "Lct-v" "Logica" [37] "Lu" "Mate" "Mate10" [40] "Mate11" "Mate12" "Mate6" [43] "Mate7" "Mate8" "Muzica" [46] "Muzica-opt." "Muzica/Ed.plastica" "Orientare" [49] "Psihologie" "Rbz" "Religie" [52] "Rom" "Stiinte" "TIC" [55] "Txt-l"
Pentru "Matematică" (denumită cu jargonul "Mate") avem 7 denumiri, dintre care cele sufixate cu cifre sunt fără importanță, acoperind doar 17 ore, dintre cele 166:
> CN %>% filter(grepl("Mate\\d+", obj)) %>% nrow(.) [1] 17 # ore "speciale" (câte una, după nivelul 6:12 al claselor) > CN %>% filter(grepl("Mate", obj)) %>% nrow(.) [1] 166 # total ore de "Matematică"
Unificăm cele 7 denumiri:
> CN$obj[grepl("Mate", CN$obj)] <- "Mat"
La fel, unificăm "Geo" și "Geo-opt." etc. și chiar, reducem "info-TIC" la "Info".
Sunt câteva "discipline" obscure, cu câte una sau două ore și despre care probabil că știu numai elevii claselor respective:
> CN %>% filter(obj %in% c("Jurn", "Lu", "Rbz")) %>% arrange(obj) cls zl ora obj 1 11A Lu 4 Jurn # Jurnalism? 2 11D Mi 2 Lu # Literatură universală? 3 12D Ma 3 Lu 4 6A Ma 1 Rbz # Reserve Bank of Zimbabwe?! 5 9C Ma 2 Rbz
Cărui profesor, de la clasele respective, să le atribuim? Vom verifica dacă unul de "Rom" este disponibil Lu|4 și îi vom atribui (odată cu clasa 11A) și ora de Jurn; analog, pentru "Lu" (presupunând că e vorba de ceva "Literatură universală"). Pentru "Rbz"… hai să zicem că ar fi vorba de ceva "Roboticză" și probabil o vom delega celui de "Info".
La fel, cele 8 ore la clase diferite de "Lct{-cr|-t|-v}" țin poate, de ceva "Limbă Corectă" (??) și le vom atribui celor pe care îi vom inventa pentru "Rom"… Probabil și cele 2 ore de "txt-l" (o fi ceva "texte literare"? …că elevii de-a 8-a au de făcut analiză sintactică și morfologică a textului, la examen), le vom pasa tot pe "Rom".
Mai departe, am înființat un dicționar de abrevieri pentru discipline și ne-am apucat să folosim "enframe.R" din [1]; pentru Ro ("Româna") sunt necesari 8 profesori (cu câte 18-23 de ore, fiecare) dar am constatat apoi că dacă le adăugăm și orele de "Lct" atunci ar fi necesari 10 profesori (dintre care doi cu 10 și 12 ore) — însemnând că orele criptate prin "Lct" ar trebui alocate altei discipline "principale", dacă ținem la compatibilitatea cu orarul existent.
Ne-am tot temut, de la bun început, că interesul pentru acest "Orarul general clase" va eșua… Ne-a reușit în [1], dar în cazul de față lucrul prestat ca "detectiv" tinde să devină plicticos, încât abandonăm aici, fără jenă.
vezi Cărţile mele (de programare)