Recunoașterea textului și extragerea datelor unui orar școlar prezentat în format PDF (IV)
[1] v. partea a III-a …
… ce facem noi aici ?!
Am plecat (v. [1]) de la un fișier PDF cu imaginile scanate ale unor pagini de hârtie pe care erau orarele claselor dintr-o școală — scrise și neobișnuit: „de mână”, altfel de nivel funcționăresc, obișnuit la noi: conținut non-diacritic, cu formatare vizuală naivă de conținut ("antreprenorială"—dată indivizibilă—apare, centrat în celulă, pe două rânduri: "antreprenori" și "ala"). Aveam de „extras” datele orarului (în primul rând, textul care fusese scanat).
Nu zicem că n-ar fi fost mai simplu să procedăm și noi, „funcționărește”: scriem (manual) într-un editor de text ceea ce vedem pe imagini, respectând (și îndreptând când este cazul) formatul pe linii și coloane; poate că așa era mai simplu, de extras datele — dar… ce am învăța astfel? Nimic. Cam la fel, dacă am fi investit (pentru mai mult de două pagini) în pen2txt.com (v. [1]), sau în cloud.google.com/vision, sau și mai simplu, în ChatGPT.
Chiar din start, avem de-a face cu relațiile delicate privitoare la "pixeli", "puncte tipografice" și "rezoluție"… Inițial, numele de profesori apar prea mici: dacă am socotit bine, au înălțimea cam de $5$-$6pt$ (s-ar cere să fie de $10$-$12pt$); „între timp”… ne-am convins că pentru a crește rata de recunoaștere corectă a textului respectiv, rezoluția standard ($300dpi$) la care am urcat în [1] trebuie mărită pe la $400$-$450dpi$ (…dacă am socotit bine).
Bineînțeles… în loc de a modifica (firesc) din punctul în care am ajuns în [1], preferăm s-o luăm de la capăt (având mereu și speranța de a începe să lămurim lucrurile).
Înființăm deci un nou subdirector de lucru 24sep/ (marcând că acuși intrăm în "septembrie"; probabil… vom ajunge și la "24oct/") și întâi, copiem aici sub numele CN.pdf, fișierul PDF care conține imaginile scanate ale orarelor claselor. Scăpăm de antetele și subsolurile paginilor, precum și de coloana pe care fuseseră etichetate zilele (v. [1]) și obținem imaginile CN-*.png ale orarelor propriu-zise:
pdftocairo -png -mono -r 400 -x 571 -y 662 -W 3965 -H 2398 CN.pdf
La rezoluția $400dpi$, colțul stânga-sus al zonei dreptunghiulare care ne interesează are (cu mici diferențe de la o pagină la alta) coordonatele $(571px, 662px)$ (cum putem vedea prin comanda display din ImageMagick); lățimea zonei de interes este $3965px$ (am exclus și marginile albe laterale), iar înălțimea este $2398px$.
Mai încolo, vom exclude și coloana a 8-a, exceptând două clase care într-adevăr, ajung la 8 ore / zi (două și nu una, cum văzusem eronat în [1]).
Reluăm din [1], programul care denumește fișierele CN-*.png prin numele claselor:
#!/bin/bash clase=( 9{A,B,D,E,F} {10..12}{A..F} {5..8}A ) # cele 27 de clase i=0 for file in `ls CN-*` ; do # numele inițiale: CN-01.png .. CN-27.png mv $file ${clase[i]}.png let i=i+1 done # noile nume: 5A.png, 6A.png, ..., 10A.png, 10B.png, ..., 12E.png, 12F.png
Înființăm subdirectorul CN/ și mutăm aici (prin comanda mv) fișierele "9B.png" și "9E.png" (clasele care ajung și la 8 ore/zi); pentru fișierele rămase, eliminăm în prealabil mutării lor, a 8-a coloană (inutilă, de vreme ce nu conține date):
mogrify -crop 3480x2398+0+0 +repage -path ./CN *.png
Subliniem că fără "+repage", imaginea decupată ar fi moștenit informații din pagina-părinte; imprimanta ar lua în seamă nu dimensiunile imaginii decupate, ci pe cele ale paginii (de exemplu, dacă decuparea are geometria $50px$ x $32px$, ea va fi tipărită prin scalare la dimensiunile întregii pagini, dacă și acestea sunt înregistrate în fișierul respectiv).
Am ajuns astfel, dar cu rezoluție care pare mai bună, în același stagiu în care dusesem [1]. Mai departe urmăm rețeta de lucru indicată în documentația de la Tesseract (poate știm noi ce știm, totuși nu la nivelul necesar explorării și expunerii științifice a mecanismului neuronal pe care se bazează tesseract și… ne rămâne doar să aplicăm "rețeta").
Setul exemplelor de recunoaștere
Pentru situația concretă în care este provocat, tesseract „judecă” pe baza unor exemple de recunoaștere corectă pe care a fost „antrenat” în prealabil — exemple din care s-au sintetizat anumite caracteristici de limbă și de scriere, organizate în anumite "baze de date" (fișiere "*.traineddata") constituite din timp pentru diverse limbi și scrieri.
Plecăm de la fișierul "eng.traineddata" (este de bănuit că pentru engleză s-a făcut cea mai bună antrenare) și „adăugăm” exemple specifice cazului nostru — constând, cel mai simplu, din câte o imagine de literă / cuvânt / linie de text și însuși textul reprezentat pe această imagine; ulterior, prin anumiți algoritmi, vor rezulta automat și dimensiunile zonelor ocupate de elementele de text respective — încât, oriunde ar figura acestea pe imaginea inițială (sau pe oricare alta, în principiu), ele vor putea fi, cât mai corect, recunoscute.
Exemplele folosite pentru antrenarea recunoașterii vizează (eventual, printr-un dicționar separat) și cât de multe cuvinte frecvent întâlnite în limba respectivă; deci, pe lângă perechile de fișiere "imagine, text", va fi de formulat și o listă de cuvinte specifice cazului nostru (nume de discipline școlare, prenume și nume de profesori — neaflate desigur, în dicționarul limbii engleze), urmând să vedem cum să o angrenăm în procesul de antrenare.
Să înființăm un subdirector "hwr-ground-truth/", în care să generăm fișierele-exemplu proprii ("hwr-" ar veni de la "handwriting", reflectând specificul „de mână” cu care avem de-a face aici).
Pentru "capturi de ecran" obișnuiam să folosim instrumentul standard "Screenshot"; investigând puțin, constatăm că rezoluția imaginii salvate este cea specifică ecranului (cam $96dpi$) și nu cea specificată în imaginea de pe care am decupat… În schimb, prin display (din ImageMagick), imaginea decupată (folosind meniul Transform / Crop) păstrează rezoluția — rezultând cam cum dorim, captură "de imagine" și nu "de ecran".
Subliniem că un click pe imaginea deschisă prin display desfășoară pe ecran meniul specific și putem folosi item-urile acestuia; dar un nou click pe imagine, ascunde meniul respectiv și ne permite să folosim în schimb anumite taste, pentru a declanșa o operație sau alta.
Am ales să procedăm cam așa: deschidem prin display unul sau altul dintre cele 27 de fișiere PNG aflate în directorul CN/; tastăm c, activând astfel meniul "Crop" — prin care putem indica folosind mouse-ul, zona dreptunghiulară pe care vrem să o decupăm. După ce am indicat și validat zona de decupat, tastăm t; operația "Trim" declanșată astfel elimină marginile albe laterale și (mai important) "repaginează" imaginea decupată (analog parametrului "+repage" dintr-o comandă crop; v. [1]). Apoi, prin combinația de taste ctrl+s, salvăm în directorul hwr-ground-truth/, imaginea decupată astfel — numind-o "1.png" pentru prima decupare efectuată, "2.png" pentru a doua, ș.a.m.d.; prin tasta backspace ajungem înapoi, pe imaginea inițială (pentru o altă decupare).
Odată cu salvarea decupării curente, consemnăm textul de recunoscut pentru imaginea respectivă — într-un vector de șiruri la fel indexat ca și imaginile pe care le decupăm (am deschis într-o altă fereastră, un editor de text în care am inițiat un program $\mathbf{R}$ în care deocamdată am specificat vectorul respectiv).
Pentru ilustrare, să zicem că în "1.png" vrem glifa pentru "a". În fereastra deschisă de display pentru una dintre clase, tastăm c și marcăm cu mouse-ul o zonă care conține glifa; redăm aici două glife pentru "a", asemănătoare (totuși, cu mici diferențe de formă):

Punctăm caseta "Crop" (validând decuparea), apoi tastăm t — ceea ce produce o casetă prin care putem opta pentru un procent de margine albă (preferăm "0%", ca pentru "CropBox"); în final, salvăm (prin ctrl+s) zona decupată astfel (rezultând fișierul 1.png) și în vectorul instanțiat în programul $\mathbf{R}$ redat mai jos, înscriem pe primul loc a (acest program va trebui să constituie fișierul "1.gt.txt" în care să înscrie "a", ca text de recunoscut pentru o zonă de pixeli suficient de „similară” celeia reprezentate în "1.png").
Am decupat astfel (alegând un orar sau altul), un anumit număr de zone — pentru glifele unor litere și pentru cuvinte sau porțiuni de cuvânt; redăm câteva mostre, așa cum sunt listate în fereastra "file-browser"-ului pe care-l folosim ("Thunar File Manager"):
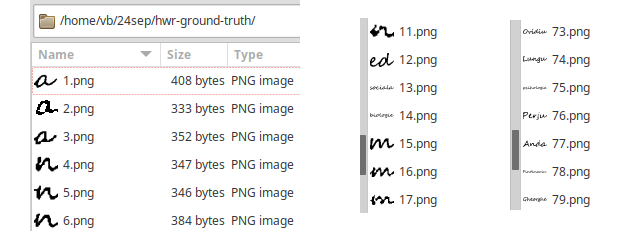
Puteam ignora unele litere, gândindu-ne că ar fi suficient să indicăm unul dintre cuvintele în care apar (de exemplu, cuvintele "sociala", "istorie", "psihologie", "Giosan" exemplifică "s" și "i"): probabil, cuvântul respectiv va fi corelat treptat cu alte cuvinte și va fi secționat intern pe litere (poate și corect, după o serie de încercări)…
Pe de altă parte, unele glife (de exemplu, pentru "A" sau "R") seamănă suficient de bine cu formele standard, încât ar putea fi corect recunoscute și direct (fără alt antrenament).
La sfârșit, invocând tesseract -l hwr pe unul dintre orarele din CN/ — vom putea să ne dăm seama dacă am ales bine, exemplele din hwr-ground-truth/ (și eventual, vom putea reveni asupra acestora). Dar acum, putem verifica ușor că exemplele respective sunt necesare:
#!/bin/bash cd hwr-ground-truth for png in `ls *.png`; do echo $png tesseract $png stdout -l eng --psm 8 done
Am trecut prin tesseract fiecare fișier din hwr-ground-truth/, implicând fișierul de antrenare obișnuit "eng.traineddata" (precizăm că "--psm" indică "Page segmentation modes" — aici, "8: Treat the image as a single word").
Rămâne să confruntăm ce s-a afișat, cu ce era corect să se afișeze drept text recunoscut pe imaginile respective; redăm aici câteva mostre, care atestă că inițial (fără antrenare suplimentară), textul de pe imaginile respective nu este recunoscut corect:
1.png “iy # corect era: a 2.png i. # corect era: a 3.png (i- # corect era: a 4.png LU # corect era: n 13.png wotrrahea # corect era: sociala 76.png Per ju # corect era: Perju
Subliniem că tesseract nu avea cum să recunoască scrisul "de mână"…
"-l eng" implică "eng.traineddata", iar tesseract trebuie să știe și unde se află acest fișier; nefiind specificată în comandă, calea acestui fișier va fi preluată din variabila de mediu (creată în prealabil, în fișierul .bashrc) TESSDATA_PREFIX:
cat ~/.bashrc | grep TESS
export TESSDATA_PREFIX=/usr/share/tesseract-ocr/5/tessdata
ls -h -s $TESSDATA_PREFIX/
Inspectând directorul respectiv (de exemplu prin comanda ls de mai sus), constatăm că eng.traineddata măsoară $4M$ și consultând documentația, ne dăm seama că e vorba de varianta (preferată chipurile, de către utilizatorul obișnuit) tessdata_fast (pentru care este importantă nu acuratețea, ci viteza de lucru — încât scrisul „de mână” este aproape exclus).
Acum, prin următorul program $\mathbf{R}$, constituim (în directorul hwr-ground-truth/) fișierele "i.gt.txt" care înregistrează textul din imaginea "i.png" (cu i=1..86):
txt <- c("a", "a", "a", "n", "n", "n", "l", "l", "o", "o", "n", "ed", "sociala", "biologie", "m", "m", "m", "t", "i", "c", "c", "x", "e", "e", "b", "fiz", "Camelia", "C", "D", "R", "Maftei", # ... # "Popovici", "Carmen", "Constantineanu", "Gabriel", "s", "d", "Ionela-Andreea") wd <- setwd("hwr-ground-truth") for(i in 1:length(txt)) writeLines(text = txt[i], con = paste0(i, ".gt.txt")) setwd(wd)
În hwr-ground-truth/ am instruit mai ales acele cuvinte (și sunt multe) care apar cu diverse deteriorări, în unele dintre fișierele-orar — de exemplu:
Pentru un mic experiment de comparație, descărcăm în directorul curent fișierul din varianta tessdata_best (măsoară aproape $15M$):
wget https://github.com/tesseract-ocr/tessdata_best/raw/main/eng.traineddata
și modificăm programul Bash redat mai sus astfel:
for j in $(shuf -i 1-86 -n 10); do cat -b $j.gt.txt # cuvântul de recunoscut tesseract $j.png stdout -l eng --psm 8 # cu _fast (prin $TESSDATA_PREFIX) tesseract $j.png stdout -l eng --tessdata-dir ~/24sep --psm 8 # cu _best done # Atașăm un eșantion semnificativ de rezultate: 1 Brindusa Dl ae grAnneece Rrindiisa 1 Epure Frssyre Epiuire 1 psihologie P4ApoLo"ge psihologLe
Prin shuf am selectat aleatoriu 10 dintre indecșii corespunzători fișierelor-pereche din hwr-ground-truth/; am afișat cuvântul conținut în fișierul ".gt.txt" și am invocat tesseract cu eng.traineddata din versiunea _fast (de pe calea indicată de TESSDATA_PREFIX) și apoi (indicând prin --tessdata-dir, directorul curent) din versiunea _best. Se vede și pe eșantionul redat, că prin "_best" recunoașterea are mai mare acuratețe, decât prin "_fast".
Adoptăm de-acum încolo versiunea "_best", mutând fișierul eng.traineddata din directorul curent, în locul indicat de variabila TESSDATA_PREFIX (înlocuind versiunea inițială "_fast", pe care dacă vrem neapărat să nu o pierdem, o salvăm în prealabil într-un alt loc); bineînțeles că mutăm sub sudo, destinația fiind în afara spațiului fixat de $HOME:
sudo mv eng.traineddata $TESSDATA_PREFIX
Pentru orice eventualitate, gândindu-ne că denumirile care apar în orare nu figurează în vreun dicționar englez, am constituit și un fișier new_words.txt în care am înscris pe câte o linie, majoritatea numelor de discipline școlare și de prenume și nume ale profesorilor (da!… "funcționarește": am citit de pe fiecare orar și am scris 131 de cuvinte distincte).
Antrenarea mecanismului de recunoaștere
Avem instalat Tesseract (versiunea 5.4.1), încât ne putem documenta și direct (fără a mai accesa tessdoc), prin man tesseract. Procurăm acum, în directorul curent, pachetul prin care vom putea constitui un fișier .traineddata adecvat necesităților proprii:
git clone https://github.com/tesseract-ocr/tesstrain.git
Vom lucra după „rețeta” etalată în fișierul tesstrain/README.md. În principiu, pentru a produce fișierul hwr.traineddata este suficient să mutăm în tesstrain/data/ subdirectorul hwr-ground-truth/ pe care l-am constituit mai sus și apoi, să invocăm make training.
Vrem să păstrăm totuși, pentru orice eventualitate, subdirectorul inițial hwr-ground-truth/ — așa că nu-l mutăm, ci doar îi copiem fișierele conținute (după ce constituim subdirectoarele necesare în tesstrain/):
mkdir -p tesstrain/data/hwr-ground-truth cp hwr-ground-truth/* tesstrain/data/hwr-ground-truth/
Putem vedea cam ce va face make training, răsfoind fișierul tesstrain/Makefile. Chiar la începutul acestuia, avem o mică „surpriză”: fișierul eng.traineddata (din varianta "_best") trebuie plasat într-un anumit loc, anume în tesstrain/usr/share/tessdata (în loc de a-l referi cum avansasem noi, prin $TESSDATA_PREFIX); este prudent să nu modificăm fișierul Makefile, așa că procedăm cum se cere (creem subdirectoarele indicate și copiem fișierul respectiv):
mkdir -p tesstrain/usr/share/tessdata cp $TESSDATA_PREFIX/eng.traineddata tesstrain/usr/share/tessdata/
N.B. Vom vedea, probabil în "24oct", că nu este necesar să procedăm așa…
Vedem apoi, în Makefile, cam ce parametri vom putea folosi; de exemplu, lista noastră de cuvinte "new_words.txt" va putea fi indicată în variabila WORDLIST_FILE — caz în care (cum aflăm din documentația aferentă) este necesar să folosim și variabila PUNC_FILE pentru a specifica un fișier care să conțină semnele de punctuație care vor trebui recunoscute. Creem deci, în directorul curent, un fișier căruia îi zicem "new.punc" și înscriem în el un singur semn, "–"; acesta apare uneori pe imaginile orarelor, între două prenume, de exemplu "Alina–Andreea" (iar alte semne "de punctuație" nu avem).
Ulterior… am adăugat și "/", folosit pe unele orare pentru a indica o pereche de termeni, de exemplu: "BE / CA", sau "viz/ muz" (și ulterior, am decupat pentru "ground-truth" și zonele corespunzătoare acestora).
Makefile angajează și combină anumite programe Python, existente în directorul tesstrain/; de exemplu "generate_line_box.py" creează fișiere care conțin coordonatele boxelor pentru imaginile și textele din subdirectorul hwr-ground-truth/.
Revenind cuminte la "rețetă", putem lansa (din directorul tesstrain/):
cd tesstrain make training MODEL_NAME = hwr START_MODEL = eng PUNC_FILE = ~/24sep/new.punc WORDLIST_FILE = ~/24sep/new_words.txt PSM = 8
Execuția scurtă (sub 2 min.) nu este neapărat, un semn bun…
Copiem rezultatul în locul cuvenit:
sudo cp data/hwr.traineddata $TESSDATA_PREFIX
Probăm recunoașterea prin "hwr", pe fișiere PNG din subdirectorul CN/:
cd .. tesseract CN/5A.png stdout -l hwr get.images Delia Dascalu Camelia Alexandriuc Raluca Crisantha Alexa Daria Marginean Mihai Bogdan Dranca romana religie c ds matematica informatica c ds Mihaela Cristina Ionela-Andreea Sandru Florin Hostiuc Adrian Frincu Raluca Crisantha Alexa Hatmanu Nicoleta Bumbu ed vizuala romana ed muzicala istorie consiliere geografie Adrian Frincu Ionela-Andreea Sandru Lucian Tablan Mihai Bogdan Dranca Nicoleta Bumbu Nicoleta Bumbu c d s ed fizica germana romana matematica Raluca Crisantha Alexa Adrian Cojocaru Camelia Maftei Ionela-Andreea Sandru Raluca Crisantha Alexa germana romana tic matematica engleza ed fizica Camelia Mafrei Ionela-Andreea Sandru Hatmanu Raluca Crisantha Alexa Daria Marginean Adrian Cojocaru
Confruntând cu orarul clasei 5A (redat undeva în [1]), vedem două sau trei greșeli minore (anume, "c ds" în loc de "c d s" sau "cds" și "Mafrei" în loc de "Maftei") și o greșală importantă, surprinzătoare: s-a omis linia disciplinelor din prima zi…
Pentru încă două sau trei orare, textul corespunzător primei linii (sau altor linii aferente disciplinelor, în unele cazuri) nu este recunoscut; altfel… am putea fi mulțumiți: numărul cuvintelor care ar trebui corectate pe textele rezultate este mic.
Am avut inspirația să folosim parametrul de configurare "get.images"; pe fișierul produs astfel, "stdout.processed.tif", vedem că prima linie apare și ea, dar… vedem că sunt trasate și liniile orizontale și verticale care încadrează celulele (de regulă, aceste linii nu mai apar pe fișierul ".tiff" creat de tesseract pe baza fișierului PNG inițial). Liniile respective au fost din start (în urma scanării), prost trasate: cu grosime neuniformă și chiar, cu întreruperi și devieri — atrăgând diverse greșeli de recunoaștere, mergând până la ignorarea textului aflat dedesubt, ca și când acesta doar ar întregi graficul liniei (în loc de a fi text de recunoscut).
Pare absurd, dar nu este: nu numai textul propriu-zis a fost „mărit” (fixasem rezoluția $400dpi$), dar și liniile grafice — încât unele fragmente de linie pot fi interpretate ca text (scris mai mic), care fie este recunoscut greșit (și în loc de discipline apar fel de fel de litere disparate), fie este ignorat (nu pare a fi "text", în baza exemplelor existente)…
Păstrarea liniilor care marchează celulele s-ar explica prin faptul că la constituirea fișierului "hwr.traineddata" am folosit "PSM=8" (adică "Treat the image as a single word"), plecând de la faptul că în hwr-ground-truth/ am înscris numai câte o literă, sau câte un cuvânt (nu și vreo linie de text, compusă din mai multe cuvinte).
Între timp (consultând diverse liste de discuții) am aflat între altele ("defecte", sau aspecte care rămân de pus la punct), că tesseract operează mai bine la nivel de linie, nu de cuvânt… Este mai ușor (sau sigur) de recunoscut literele și cuvintele, plecând de la contexte în care apar acestea — deci plecând de la linii de text, supuse apoi unor diverse încercări de separare în cuvinte și litere (consultând mereu și dicționarul limbii).
Suficiente învățături și dileme, ca să reluăm acuși de la capăt…
vezi Cărţile mele (de programare)