Recunoașterea textului și extragerea datelor unui orar școlar prezentat în format PDF (VII)
[1] v. partea a VI-a …
Fișierul ~/24Sep/CN.pdf —obținut probabil prin scanare și publicat pe un site, de unde l-am strâns aici— conține 27 imagini de pagini "A4, Landscape", reprezentând orarul câte uneia dintre clasele unei anumite școli, într-o scriere „de mână” (nerecunoscută direct, de mașină):

Reluăm [1] cam „de la capăt” (înființând întâi "24Sep/") — mai ales că între timp, ne-am făcut cu Xubuntu-24.04. (Apropo: acum, tasta "prt sc / sysrq" funcționează corect (așa am desprins imaginea redată mai sus) — încât am exclus "Screenshot" dintre lansatorii constituiți în [1]-V)
Datele de încadrare
Ne interesează datele de încadrare, exprimate de exemplu prin prof | cls — unde variabila cls reprezintă clasele, iar prof are ca valori câte un profesor (sau cuplu de profesori) împreună cu disciplina școlară principală pe care este încadrat. Într-o codificare convenită în prealabil, "Ma3 | 9B" de exemplu, ar reprezenta o lecție care trebuie alocată într-o anumită zi și oră la clasa 9B, celui de-al treilea (într-o ordine convenită) dintre profesorii de "Matematică"; iar "En3Fr1 | 10A" ar reprezenta o lecție de alocat într-o anumită zi și oră la clasa 10A despărțită însă în două grupe de elevi: o grupă face "Engleză" cu profesorul En3, iar cealaltă are "Franceză" cu profesorul Fr1.
[prof | cls] înregistrează toate lecțiile care trebuie desfășurate pe parcursul săptămânii în școala respectivă; de exemplu, "Ma3 | 9B" apare de atâtea ori cât este numărul de ore/săptămână pe care a fost încadrat Ma3 la clasa 9B.
Intenționând să constituim un nou orar, nu ne interesează neapărat, zilele și orele alocate lecțiilor prin orarul inițial CN.pdf; dar pentru a stabili cuplajele (de exemplu, En3Fr1) și pentru a conveni asupra unor codificări, avem totuși nevoie de datele complete din CN.pdf: prof | cls | obj | zi | ora, unde obj reprezintă câte una dintre disciplinele pe care este încadrat prof (una fiind cea „principală”, avută în vedere la codificarea profesorilor).
De exemplu, găsind în orar doi profesori care intră în același timp la aceeași clasă, En3|10A|engleză|Ma|3 și totodată, Fr1|10A|franceză|Ma|3 — deducem existența cuplajului En3Fr1 (pe clasa 10A). Dacă orarul inițial specifică și cuplajele (de exemplu, Frincu/Tablan | 9A | viz/muz | Vi | 3), atunci chiar nu mai avem nevoie de valorile zi și ora (decât în cazul mai rar, când există și cuplaje de clase).
Defectele imaginilor
Pe imaginile din CN.pdf, datele care ne interesează figurează drept cuvinte scrise „de mână”, în celulele unui „tabel” (formatat vizual) cu 5 linii și 8 coloane (ignorăm antetul și coloana care conține denumirile zilelor). S-a scris cu două mărimi, foarte departe una de alta; în general, literele dintr-un cuvânt sunt legate cursiv între ele, iar o aceeași literă are în diverse cuvinte, forme ușor diferite. În plus, liniile care bordează celulele au grosime neuniformă și uneori, apar cu întreruperi; în mai multe celule, apar unele artefacte (amprente de pete întâmplătoare sau dâre, ale colii de hârtie de pe care s-a scanat imaginea).
Pentru noi, aceste defecte ale imaginilor respective sunt nesemnificative: ne este ușor să ignorăm petele și putem recunoaște fără greșeală, cuvintele respective — ba chiar, știind limba română, putem și să le corectăm ad-hoc (dacă ai scris "istorie", atunci trebuie să scrii "engleză" și nu "engleza"; cu siguranță, nu este "Amoraritei", ci "Amorăriței", etc.).
În schimb, în prezența unor asemenea „mici” defecte ale imaginii (mai ales dacă este vorba de "tabel"), Tesseract — cu antrenamentul obișnuit — nu poate evita producerea unor greșeli de recunoaștere a textului, rezultând și cuvinte „stâlcite” (cum am constatat deja în [1]); rata de recunoaștere se poate mări prin eliminarea prealabilă a defectelor imaginii, ceea ce nu este deloc ușor de realizat „corect” (de exemplu, ca să elimini „noxele”, fără a altera textul existent, ai de experimentat cu anumite programe specializate, poate pentru fiecare imagine în parte, până ce nimerești valori potrivite anumitor parametri).
Ideea de lucru (cum scăpăm de paraziți)
Observăm această particularitate a imaginilor din CN.pdf: în fiecare celulă a tabelului care conține orarul clasei, cuvântul corespunzător câmpului obj este scris pe linia mijlocie a celulei (uneori, fiind continuat și pe linia dedesubtul acesteia: "antreprenori" pe linia centrală și "ala" dedesubt), iar prof apare la baza celulei (pe ultimul rând, sau uneori pe ultimele două rânduri).
Deci putem elimina cumva, jumătățile superioare ale celulelor — scăpând astfel, de grija prezenței în aceste zone a unor artefacte; apoi, decupăm din jumătățile rămase zona de obj și zona de prof și le înscriem corespunzător în subdirectorul "...-ground-truth/" al exemplelor pe baza cărora vom antrena motorul Tesseract.
Zonele decupate din fiecare celulă conțin și eventualele „noxe” existente în vecinătatea imediată a unor litere; dar fiindcă am indicat în fișierele "*.gr.txt" asociate, ce cuvânt corespunde fiecărei zone — scăpăm și de grija eliminării artefactelor respective.
Obs. Tesseract (ca și alte sisteme OCR, de recunoaștere a textului) procedează totuși "inteligent" (și nu ca în intenția extremală exprimată mai sus): nu este necesar să indicăm recunoașterea pentru fiecare zonă de pixeli asociate pe imagine unui aceluiași cuvânt.
Astfel, "Hostiuc" apare în orarele claselor de 27 de ori (fiindcă fiecare clasă are câte o oră de "religie"); zonele de imagine respective diferă mai mult sau mai puțin între ele, incluzând artefacte aleatorii; dar nu este necesar să pozăm toate cele 27 de zone și să indicăm recunoașterea "Hostiuc" pentru fiecare — este suficient să facem aceasta pentru una, două, poate vreo cinci dintre zonele respective: Tesseract va „întregi” aceste câteva exemple de recunoaștere, injectându-le el însuși anumiți „paraziți” — încât apar mari șanse de a recunoaște corect (sau aproape corect) toate cele 27 de zone (în [1] antrenasem Tesseract încât să recunoască imaginile inițiale, furnizând un singur exemplu cu "Hostiuc" și am constatat că sunt recunoscute corect 19 zone, iar celelalte au fost recunoscute până la penultima literă).
Cum facem (automat desigur) toate aceste eliminări și decupări? Mai întâi —în principiu— vom decupa cumva coloanele tabelului curent; apoi, pentru fiecare coloană, vom decupa jumătățile inferioare ale celulelor (excluzând și borderele); apoi… rămâne de văzut (în fond, în "...-ground-truth/" am avea deja toate valorile obj și toate valorile prof — mai trebuie să aplicăm tesseract pe imaginea inițială?).
Desigur, ideea „extremală” de a exemplifica recunoașterea pentru toate cuvintele, trebuie să fie proastă și o luăm în seamă doar pentru moment; probabil vor fi suficiente cele vreo sută de exemplificări de recunoaștere a literelor și a unora dintre cuvinte, prezentate deja în [1] (dacă nu, atunci rămâne să antrenăm din nou Tesseract, ținând seama că acum nu mai avem „tabel”, ci doar câte o coloană simplă).
1. Imaginile de bază
Cele 27 imagini din CN.pdf au cam aceeași poziție în pagină, deci putem să ne bazăm (fără a greși prea mult) pe caracteristicile de poziție ale uneia oarecare dintre ele. Extragem într-un fișier PNG (pe care l-am vrea "monocrom"), imaginea din prima pagină, fixând însă o rezoluție suficient de mare ($400ppi$, ca și în [1]):
pdftocairo -singlefile -png -mono -r 400 CN.pdf
Folosind display (cum am arătat în [1]) pentru fișierul CN.png rezultat, găsim coordonatele colțurilor zonei de 5 linii × 8 coloane vizate mai sus și pe baza acestora, putem extrage zonele 5×8 respective din toate imaginile:
pdftocairo -png -mono -r 400 -x 574 -y 653 -W 3964 -H 2410 CN.pdf mkdir CN; mv CN-*.png CN/
Am și mutat, imaginile decupate "CN-{1..27}.png", în subdirectorul nou CN/. Fișierele PNG rezultate sunt indexate (cu 1..27) în ordinea paginilor din CN.pdf și le putem redenumi după clase, prin programul (preluat din [1]):
#!/bin/bash clase=(9{A,B,D,E,F} {10..12}{A..F} {5..8}A) # în ordinea din CN.pdf i=0; cd CN for file in `ls` ; do # numele inițiale: CN-01.png .. CN-27.png mv $file ${clase[i]}.png let i=i+1 done # noile nume: 5A.png, 6A.png, ..., 12E.png, 12F.png cd ..
Redăm una dintre cele 27 imagini PNG „de bază” (5×8) care ne-au rezultat astfel:
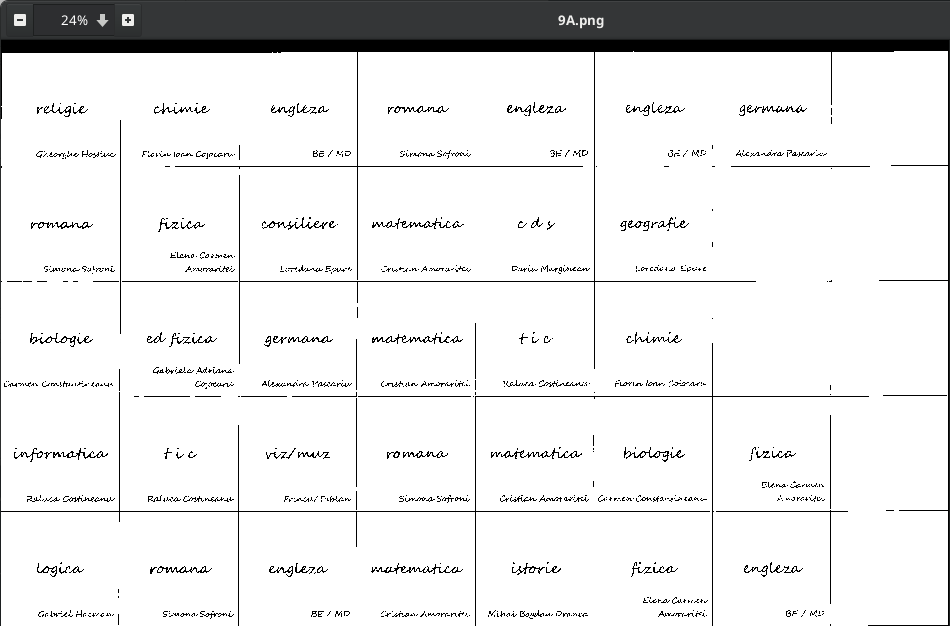
Numele fișierului PNG (9A.png) indică valoarea câmpului cls; zilele și orele corespund în mod implicit, ordinii celor 5 rânduri de celule, respectiv ordinii coloanelor.
Bordurile celulelor apar cu întreruperi, dar se subînțelege că rândurile au aceeași înălțime, iar coloanele au aceeași lățime (cel mai probabil, șablonul paginilor din CN.pdf provine din Microsoft-Word, sau din Excel); deci fiecare celulă are înălțimea $\frac{1}{5}$H și lățimea $\frac{1}{8}$W unde H și W sunt înălțimea și lățimea întregii imagini (sau procentual, 20% și respectiv, 12.5%).
2. Imaginile aferente celulelor
Mai întâi, prin următoarea secvență de comenzi Bash, într-un subdirector nou CLS/, asociem fiecărei clase câte un subdirector numit după clasa respectivă și conținând respectiv (prin cp), fișierul PNG corespunzător în cadrul subdirectorului CN/, acelei clase:
clase=(9{A,B,D,E,F} {10..12}{A..F} {5..8}A) # cele 27 de clase cls="${clase[@]}" mkdir CLS (cd CLS; mkdir -p $cls) # subdirectoarele CLS/5A/, CLS/6A/, ..., CLS/12F/ for K in $cls; do cp CN/$K.png CLS/$K/; done
Acum, prin mogrify și crop, transformăm fiecare fișier CLS/*/*.png într-un set de 5×8=40 fișiere PNG, reprezentând fiecare câte una dintre celulele orarului clasei respective:
#!/bin/bash cd CLS for cls in `ls` do cd $cls mogrify +repage -crop 12.5%x20% +repage $cls.png cd .. done cd ..
Pentru fiecare clasă, fișierele PNG rezultate sunt indexate de la "-0" la "-39", în ordinea celulelor de la stânga spre dreapta și de sus în jos; de exemplu, pentru clasa 9A ilustrată mai sus, celor 8 celule orare din ziua a doua le corespund fișierele CNS/9A/9A-[8-15].png (micșorate și concatenate aici, prin comanda montage din ImageMagick):

Între fișierele PNG din CLS/, cele care corespund unor celule goale (de exemplu 9A/9A-14.png și 9A/9A-15.png, aferente orelor a 7-a și a 8-a) măsoară mai puțin de 1000 octeți (spre deosebire de cele asociate lecțiilor) și le putem elimina:
cd CLS
find . -type f -size -1000c -delete
În CLS/ ne-au rămas 834 de fișiere PNG, adică avem în total 834 de lecții "obj | prof":
vb@Home:~/24Sep/CLS$ find . -type f -printf x | wc -c # 834 lecții
Să observăm că încă putem reconstitui valorile "zi" și "ora", luându-ne după numele de fișier; de exemplu, fișierul 9A-12.png reprezintă lecția clasei 9A din ora a 5-a a zilei a 2-a — fiindcă restul și câtul împărțirii prin 8 a lui 12, majorate cu 1, sunt 5 și respectiv 2.
Vom avea nevoie acum de Tesseract, pentru a „citi” cele 834 de imagini (ajungând apoi la „datele de încadrare”); dar întâi… avem totuși de verificat și de îndreptat câte ceva, pe imaginile respective.
3. Retușări; directorul imaginilor cls | obj | prof
Cele 834 imagini au aceeași dimensiune, $496\times 482\,px$ — incluzând însă borduri distorsionate și câte o zonă „goală” (poate cu artefacte) cuprinsă între marginea de sus și linia mediană. Folosind interactiv diplay, constatăm că ordonata dedesubtul căreia se află scrise datele care ne interesează este (cu vreo 6 excepții) $y=220\,px$ (ceva mai mare, în unele cazuri — dar minimul 220 pare potrivit majorității):

Cele 6 clase a 10-a au câte o lecție de "Educație antreprenorială", înscrisă (cum se vede mai sus pe imaginea din mijloc) prin "antreprenori" și dedesubt "ala" — iar pentru aceste 6 imagini ar trebui să considerăm $y=175\,px$. Poate că dacă am considera ca margine superioară $y=220\,px$, "antreprenori" ar dispărea de la sine; dar pentru siguranță, folosim meniurile lui display ("Image Edit / Draw..." și de aici, Color în care alegem "white" și Element în care alegem "fill rectangle") și ștergem direct "antreprenori", pe fiecare dintre cele 6 imagini. Bineînțeles că în final, ca valoare de obj, vom înlocui "ala" (care nu apare altundeva), de exemplu cu "EdAntrep" (după cum vom înlocui "engleza" cu "Engleză", ș.a.m.d.).
Până la urmă, experimentând puțin, am ales să decupăm zona care are colțul stânga-sus $(18,210)\,px$ (în loc de $y=220$), are lățimea $471\,px$ și înălțimea $268\,px$; am adăugat (fiind important pentru Tesseract) și câte un border alb de lățime $6\,px$:
#!/bin/bash cd CLS for cls in `ls`; do cd $cls mogrify +repage -crop 471x268+18+210 +repage \ -bordercolor white -border 6 *.png cd .. done cd ..
Acum toate cele 834 imagini au formatul $483\times280\,px$ și reprezintă suficient de bine, câte o lecție obj | prof; bineînțeles, cum să nu?… există câteva excepții.
Pe orarul inițial CN/9E.png, pentru prima zi avem:

Celulele corespunzătoare primelor două ore au fost colapsate, indicând vizual că în ambele ore se face "franceza"; numai că atunci când am decupat celulele, n-am luat în seamă acest aspect de formatare vizuală — rezultând (defectuos, într-adevăr):

Mai sunt câteva cazuri de colapsare orizontală (de două sau trei celule); poate n-ar fi greu să corectăm fișierele „defectuoase”rezultate în CLS/, dar preferăm să le ignorăm (ne interesează datele și nu chițibușurile vizuale). Mai precis, ștergem din CLS/, cele câteva fișiere defectuoase (reținând separat, despre ce este vorba); în final, vom adăuga direct și datele corespunzătoare celor 12 fișiere șterse — anume: 9B și 10B, "informatică", pe câte 2×3 ore și respectiv 1×2 ore; 9E cu "franceză" pe 4×2 ore.
Obs. Deci vom avea de adăugat 16 ore, nu 12 câte am șters; diferența se explică astfel: conținutul scris pe celulele colapsate vizual aparține de fapt primei (sau primelor două) celule, ultima celulă rămânând (în general) „goală” — ori mai sus, ștersesem fișierele PNG aferente celulelor goale.
Observăm încă o dată, că obiceiul (specific Microsoft-Word și -Excel) de a colapsa vizual celule, într-un tabel de date, chiar este foarte prost… (de fapt, prost este a folosi Word și Excel !)
Vorbind de „retușări”, se cuvine să îndreptăm și structura de fișiere pe care am lucrat mai sus: de vreme ce numele celor 822 fișiere PNG rămase, indică și numele claselor (exemplu: "9A-12.png"), nu prea are sens gruparea acestor fișiere în subdirectoare numite după clasă (exemplu:"9A/9A-*.png"). Înființăm subdirectorul LSS/ ("lessons"), în care copiem —fiind deja „pățit” adică nu așa bun cunoscător, evităm să mutăm, prin mv— cele 822 de fișiere din subdirectoarele lui CLS/; în final, ștergem vechea structură de fișiere CLS/:
mkdir LSS find CLS -type f -exec cp '{}' $HOME/24Sep/LSS ';' rm -r CLS
Dar… observăm acum încă o retușare de făcut. Managerul de fișiere pe care-l folosim, Thunar are setarea "Show thumbnails" și a fost ușor de observat, filând fișierele din LSS/ și văzând miniaturile acestora (apoi, verificând prin "Image Viewer"), că pentru unele clase, fișierele PNG respective încă păstrează câte un border sau fragment de border, lateral:


Cel mai probabil, la introducerea sub scanner, paginile-orar ale unor clase au fost abătute spre stânga sau spre dreapta, față de celelalte pagini — încât marginile tăiate mai sus pentru a elimina bordurile celulelor sunt în aceste cazuri, prea mici.
Fiind multe asemenea fișiere, evităm să „reparăm” interactiv (prin meniul Image Edit din display, cum procedasem mai sus). În schimb, putem folosi "-draw", sub mogrify ținând seama că de exemplu pentru clasa 7A, borderul din stânga este conținut într-un dreptunghi de colțuri opuse $(0,0)$ și $(12,279)$ și avem doar de „albit” (prin -fill) conținutul acestuia:
cd LSS
mogrify -fill white -draw "rectangle 0,0 12,279" 7A*.png
Procedăm analog pentru a elimina borderul din dreapta, păstrat încă în acest moment pe fișierele {10C,11E,12E}*.png (dar poate și pe altele, neobservate acum).
Directorul LSS/ conține acum 822 imagini PNG suficient de „curate”, reprezentând toate lecțiile cls | obj | prof (exceptând cele 16 lecții notate separat undeva).
4. Extragerea textului din celulele PNG
În [1] antrenasem Tesseract, pentru a recunoaște textul de pe imaginile din CN/ — furnizându-i inițial vreo 90 de exemple de recunoaștere; între timp însă, am mai adăugat unele exemple (ajungând la 105 exemple) și am reluat make training, rezultând în final fișierul orr.traineddata (în loc de "hwr", cum apare inițial în [1]).
Însă cu acest antrenament, Tesseract recunoscuse în mod nesatisfăcător, textul din imaginile inițiale, cu tabele 5×8, din CN/; acum însă, dat fiind că nu mai avem de-a face cu tabele, ci doar cu celule PNG individuale — este de așteptat ca Tesseract (odată ce l-am scutit de problema segmentării pe linii și coloane a imaginii) să recunoască mai bine, textul respectiv (folosind -psm 6: "Assume a single uniform block of text"), chiar și fără alt antrenament.
S-ar putea să fie suficient să folosim fișierul orr.traineddata constituit deja în [1]; dar cel mai bine probabil, ar fi să antrenăm „de la capăt”, furnizând ca exemple de recunoaștere nu litere și cuvinte individuale (ca în [1]), ci linii de text dintre cele existente pe celulele PNG ale noastre (cum și sugerează parcă, formula "a single uniform block of text").
Vom explora mai încolo, această idee de antrenare… Deocamdată să verificăm recunoașterea bazată pe fișierul orr.traineddata existent.
Să vedem de exemplu, cât de bine sunt recunoscute valorile obj | prof din celulele PNG corespunzătoare clasei 10A. Pentru aceasta, întâi constituim un fișier care să conțină pe câte o linie, numele fișierelor PNG respective:
vb@Home:~/24Sep$ ls LSS/10A* > 10A.lsf
Tesseract va acționa pe fiecare fișier din lista de fișiere transmisă:
vb@Home:~/24Sep$ tesseract 10A.lsf stdout -l orr --psm 6 # logfile
Rezultatul recunoașterii se obține imediat, pe ecran (fiindcă am indicat "stdout"); îl redăm aici selectiv, cu formatare ad-hoc, evidențiind mai ales unele eșecuri de recunoaștere; precizăm că dacă specificam la sfârșitul comenzii, configurarea "logfile", atunci informațiile "Page..." ar fi fost înscrise în fișierul tesseract.log, în loc să mai fie afișate pe ecran:
Page 0 : LSS/10A-0.png biologie Caraelia Alexandriuc # Camelia Page 1 : LSS/10A-10.png romana Simona Sofroni Page 2 : LSS/10A-11.png chimie Brindusa Mihai Page 3 : LSS/10A-12.png geografie Loredana Epure Page 4 : LSS/10A-13.png ala # eliminasem "antreprenori" de deasupra! Irina Geanina Harja ... ... Page 7 : LSS/10A-19.png ger mana # De!… s-au exemplificat litere, nu linii Alexandra Pascariu ... ... Page 20 : LSS/10A-32.png r | # romana (dar... cu border-dreapta!) Simona Sofroni | Page 21 : LSS/10A-33.png # "engleza | BE / CA" nerecunoscut Page 22 : LSS/10A-34.png chimie Brindusa Mihai Page 23 : LSS/10A-35.png istorie Mihai Bogdan Dranca ... ... Page 29 : LSS/10A-5.png g ermana # dacă exemplifici litere, nu linii… Alexandra Pascariu ... ...
Fiindcă am exemplificat recunoașterea pentru litere și numai pentru unele cuvinte, a rezultat ba "g ermana", ba "ger mana". Fiindcă ne-a scăpat să excludem borderul din dreapta, în cazul celulei 10A-32.png (v. Page 20) recunoașterea a eșuat aproape complet (dar acest caz se rezolvă ușor prin display, „albind” ca mai sus, un dreptunghi în jurul borderului). În plus însă, pentru 3 imagini (cu un același obj și un același prof !) rezultatul recunoașterii este vid (v. Page 21, mai sus); pentru 4 imagini s-a recunoscut (corect) numai prof, iar pentru o imagine s-a recunoscut (corect) numai obj. Am investigat cumva imaginile respective, dar n-am observat „defecte” care eventual, să explice situația…
25 dintre cele 33 de lecții PNG (ale clasei 10A) au fost recunoscute corect (în doar câteva cazuri, cu eroare de o literă sau două). Cele 8 situații de nerecunoaștere semnalate mai sus se datorează mai ales faptului că orr.traineddata se bazează pe exemplele de recunoaștere constituite în [1], într-un alt context decât cel de față, mizând pe litere și cuvinte individuale (și nu pe linii de text, cum ar fi cel mai potrivit acum).
Ne vom apuca acuși să antrenăm din nou Tesseract, exemplificând printr-un set de linii de text extrase din cele 822 celule PNG…
Dar până atunci, avem inspirația unui mic experiment; separăm liniile din celulă și încercăm alte moduri PSM (de segmentare a paginii):
vb@Home:~/24Sep$ cp LSS/10A-3.png 10a3.png
vb@Home:~/24Sep$ mogrify +repage -crop 100%x50% +repage 10a3.png
vb@Home:~/24Sep$ tesseract 10a3-0.png stdout -l orr --psm 6
matematica # recunoaște "obj"
vb@Home:~/24Sep$ tesseract 10a3-1.png stdout -l orr --psm 6
vb@Home:~/24Sep$ # rezultat vid, pentru "prof"
vb@Home:~/24Sep$ tesseract 10a3-1.png stdout -l orr --psm 13
Cristian Amoraritei # în modul 13 (nu 6), recunoaște și "prof"
10A-3.png este una dintre imaginile pentru care rezultatul recunoașterii fusese vid. Am copiat în directorul de bază imaginea respectivă și prin -crop am desprins în imagini separate cele două câmpuri, "10a3-0.png" (pentru obj) și "10a3-1.png" (pentru prof).
Păstrând "--psm 6", constatăm că este recunoscut obj (nu și prof); dar apoi, cu "--psm 13" ("Treat the image as a single text line, bypassing hacks that are Tesseract-specific") constatăm că este recunoscut (corect) și câmpul prof…
Deducem că pentru Tesseract, cum-necum, imaginea respectivă 10A-3.png, nu este "a single uniform block of text".
Bine… se pare că "uniform text" înseamnă și că este implicat un singur font: dacă o literă se repetă (a vedea literele "i", "r", "a" din câmpul prof redat mai sus), ea nu-și modifică forma — ceea ce nu prea se potrivește scrierii "de mână"; iar cu PSM-13 avem "bypassing hacks", deci se relaxează și pretențiile asupra fontului, încât prof a putut fi recunoscut.
vezi Cărţile mele (de programare)