Tutorial de PS ca site HTML şi ca document PDF
De ce, te-ai strădui să înveţi încă un limbaj?!
De curând, m-am apucat şi de PostScript… Multe programe de grafică ajung până la urmă la un interpretor de PS. Întâi a apărut TeX (şi MetaFont); apoi a apărut PS, iar imprimantele au început să fie înzestrate cu interpretoare de PS; ceva mai târziu, a apărut MetaPost (iar R de exemplu, a beneficiat oarecum, de toate acestea).
TeX produce fişiere binare DVI, care descriu aspectul vizual al documentului procesat fără a avea în vedere însă, vreun display sau vreun printer; fişierele DVI sunt pasate de regulă unui program "driver", care le converteşte în PS (sau în PDF), asigurându-se în final vizualizarea pe display, precum şi tipărirea.
Ordinea cronologică şi legăturile menţionate justifică interesul pentru PS (fie şi după ce am învăţat câte ceva din TeX şi MetaPost şi-mi poate părea deja suficient, pentru grafica pe care o practic). MetaPost produce în modul implicit fişiere EPS, subordonate limbajului PS; putem verifica lucrurile de exemplu astfel: creem o figură simplă (un triunghi), vizualizăm fişierul text rezultat prin compilarea figurii, decupăm eventual partea esenţială şi transmitem imprimantei.
% test.mp beginfig(1); u = 1in; % unitatea de măsură (1 inch = 2.54 cm = 72 bp) draw (1u, 3u) -- (3u, 5u) -- (4u, 2u) -- cycle; endfig; end
Compilând prin mpost test.mp, obţinem fişierul "test.1", din care extragem ceea ce ar fi partea esenţială (şi o salvăm drept "test.1"):
%!PS 72 216 moveto 216 360 lineto 288 144 lineto closepath stroke showpage %%EOF
Transmitem "test.1" imprimantei (instalată şi conectată la sistem):
lpr test.1
Dacă eliminam şi prima linie ("comentariul" %!PS), atunci imprimanta considera fişierul primit ca fişier-text obişnuit (încât s-ar fi tipărit "codul-sursă"). Imprimanta vede "%!" de pe prima linie ca pe o directivă de activare a interpretorului propriu de cod PS; acesta recunoaşte şi execută rând pe rând instrucţiunile din fişierul respectiv: se poziţionează fasciculul imprimării (sau "capul de imprimare") la 72 puncte (=1 inch) de marginea stângă a foii de hârtie şi 216 puncte (=3 inch) faţă de marginea de jos (executând instrucţiunea "moveto"), apoi se trasează o linie (cu grosimea şi culoarea implicite) până în punctul (216bp, 360bp), ş.a.m.d. În final, pe hârtie apare desenat triunghiul care fusese descris în "test.mp".
Un tutorial de PS sub formă de site HTML
"Tutorial" (termen încă nepomenit în DEX) este un text de 10-30 de pagini (uneori şi mai mult), menit să-l iniţieze pe cititor într-un anumit domeniu sau subiect, relevând, conexând şi exemplificând cât mai direct principiile şi aspectele esenţiale.
Pentru PS (deasemenea, pentru TeX, MetaPost, etc.) sunt disponibile numeroase tutoriale (a căuta de exemplu "PostScript tutorial"), fie ca documente PDF (cel mai adesea), fie ca fişiere HTML; unele dintre acestea sunt bine structurate şi orientate, sunt scrise atractiv şi îngrijit, fiind şi actualizate din timp în timp.
Faptul că sunt scrise în engleză (mai rar, în franceză sau germană) nu trebuie să fie un impediment, ci eventual o oportunitate, un imbold de a te familiariza cu o limbă necunoscută momentan; vei folosi pentru început şi probabil, mult timp, un dicţionar (şi poate, Google Translate); încet-încet, tot citind astfel, ajungi să te deprinzi cu noua limbă (eu unul aşa am procedat, când acum vreo 25 de ani, mă aflam în această situaţie). Întâlnim uneori o situaţie analogă: te străduieşti un timp, fără succes, să rezolvi o anumită problemă, folosind ceea ce ştii; la un moment dat, găseşti undeva un program care-ţi rezolvă elegant problema - dar e formulat în alt limbaj (să zicem, în Haskell) decât cele pe care le foloseşti; este clar că vei încerca să te familiarizezi cumva cu acel nou limbaj (în loc să cauţi o "traducere").
Tutorialul la care m-am oprit (după ce am răsfoit alte câteva) este A First Guide to PostScript (Peter Weingartner, 2006); m-a surprins totuşi, faptul că este oferit drept site HTML: pagina de bază conţine o listă de link-uri către celelalte pagini şi fiecare dintre acestea are un link spre pagina de bază şi unul spre pagina care îi urmează în listă; fiecare pagină este de fapt un fişier HTML de sine stătător (reflectând complet structura standard de document "XHTML 1.0 Transitional").
Chiar mi-a plăcut conţinutul şi maniera de prezentare (că mi se pare nepotrivit, să foloseşti Bootstrap şi trucuri publicitare într-un tutorial serios) şi am descărcat arhiva oferită printr-un link din pagina de bază, propunându-mi să transform site-ul respectiv în document PDF - format care pare mai indicat (şi în orice caz, mai obişnuit) pentru un tutorial, mai ales dacă prevezi reparcurgerea lui, din când în când.
Transformarea site-ului HTML în document PDF
Ca operaţie practică este deja banal, să transformi o pagină HTML în document PDF: de exemplu, foloseşti meniul "Print..." al browser-ului în care vei fi deschis pagina HTML şi alegi "Print to File" (pentru Mozilla Firefox) sau "Save as PDF" (pentru Google Chrome). Dar în cazul de faţă, avem de transformat nu o pagină HTML, ci un site HTML (adică un set de pagini HTML, interconectate între ele într-o anumită ordine).
Dezarhivăm întâi, în directorul fgPS/ ("first guide PS"):
vb@Home:~/1-mar$ mkdir fgPS vb@Home:~/1-mar$ tar xvzf postscript.tar.gz -C fgPS/
Opţiunea 'v' ("verbose") nu ne ajută: fişierele conţinute în arhivă sunt listate în ordine alfabetică (nu în ordinea paginilor site-ului).
Pagina index.html conţine o listă de elemente <a href="...">, referind paginile HTML ale site-ului în ordinea cuvenită; pentru a extrage valorile atributelor href înfiinţăm (prin touch şi chmod +x) următorul script Perl, extract.pl:
vb@Home:~/1-mar/fgPS$ touch extract.pl; chmod +x extract.pl
#!/usr/bin/perl -n while ( /<li><a\s+href\s*=\s*"(.*?)".*?>/ig ) { print "$1\n"; }
Opţiunea "-n" cu care este invocat interpretorul de Perl implică testarea condiţiei din while(...) pentru fiecare linie a fişierului transmis scriptului ca "input"; dacă linia curentă conţine "<li><a href=" (sau cu majuscule, "HREF") atunci se va afişa valoarea atributului href. Redirectăm ieşirea pe fişierul sections.txt:
vb@Home:~/1-mar/fgPS$ ./extract.pl < postscript/index.html > sections.txt
Eliminăm din "sections.txt" (care vrea să fie lista secţiunilor succesive din viitorul document PDF) ultimul item postscript.tar.gz (care corespunde link-ului prin care descărcasem arhiva). Pagina postprocess.html are la sfârşit trei link-uri spre alte pagini; putem folosi din nou scriptul Perl de mai sus, pentru a alipi referinţele respective (le vom muta apoi, imediat după "postprocess.html"):
vb@Home:~/1-mar/fgPS$ ./extract.pl < postscript/postprocess.html >> sections.txt
Avem de procedat la fel, pentru lista de link-uri din pagina "examples.html" (redate acolo sub forma "<li><a HREF="examples/newsprint.html">Clipping Text to a Box</a></li>", în care de data aceasta, href este scris cu majuscule). "sections.txt" va conţine apoi, în ordinea necesară, numele tuturor fişierelor HTML care vor trebui cumva transformate în secţiuni consecutive ale documentului PDF pe care vrem să-l obţinem (listate aici pe trei coloane, ordinea fiind "de sus în jos şi de la stânga la dreapta"):
vb@Home:~/1-mar/fgPS$ pr -o4 -3 -t sections.txt index.html eps.html examples/hello-text.htm what-is-it.html postprocess.html examples/color.html graphics.html galley.html examples/rotate.html language.html nup.html examples/scale.html programming.html draft.html examples/shadewidth.htm drawing.html examples.html examples/transform.html text.html examples/newsprint.html examples/translate.html color.html examples/cliptext.html examples/smile.html transforms.html examples/box1.html operators.html clipping.html examples/box2.html errors.html image.html examples/fill-box.html
De observat că am adăugat (în capul listei) şi fişierul index.html (acesta corespunde paginii de bază şi bineînţeles că nu figura în lista de link-uri prelucrată mai sus); probabil că va trebui să adăugăm şi alte câteva fişiere HTML, existente în arhiva respectivă.
Acum s-ar putea continua după acest plan: eliminăm din toate fişierele, exceptându-l pe primul din listă, ceea ce este cuprins între "<!DOCTYPE..." şi "<body>" (inclusiv) şi deasemenea, eliminăm toate elementele "<div class="navbar">" (care conţin link-urile la pagina de bază şi la pagina următoare); apoi, concatenăm toate fişierele şi pe fişierul HTML rezultat aplicăm meniul "Print..." al browserului - obţinând probabil, documentul PDF dorit (aspectul interesant ar putea fi conceperea unui script care primind ca intrare "sections.txt", să facă eliminările menţionate şi să alipească succesiv fişierele). "Probabil" vom obţine astfel PDF-ul dorit - nu-i sigur că browser-ul va transforma automat link-urile existente (acestea vizează fişiere HTML).
Preferăm însă o soluţie flexibilă, vizând obţinerea unui fişier LaTeX intermediar - pe care să putem opera orice modificări am găsi de cuviinţă, înainte de a transforma în final în PDF. Folosim în acest scop Pandoc - un program utilitar (bazat pe o anumită bibliotecă Haskell) care asigură conversia între diferite formate (inclusiv, din HTML în LaTeX); va trebui să indicăm ca "input" lista numelor de fişiere din sections.txt, iar pandoc va opera pe fişierele respective - de aceea, întâi copiem sections.txt în directorul postscript/ care conţine aceste fişiere şi schimbăm "directorul de lucru" pe acest director, iar apoi înfiinţăm (direct de pe linia de comandă a shell-ului Bash) o listă conţinând numele de fişiere din sections.txt:
vb@Home:~/1-mar/fgPS$ cp sections.txt postscript/ vb@Home:~/1-mar/fgPS$ cd postscript/ vb@Home:~/1-mar/fgPS/postscript$ file_list=(`cat sections.txt`) vb@Home:~/1-mar/fgPS/postscript$ echo ${file_list[@]} # verificare index.html what-is-it.html graphics.html language.html programming.html ...
Desigur, am făcut mai sus o "verificare", ilustrând aspecte specifice interpretorului Bash; dar putem mai bine, să înlănţuim direct (prin operatorul '&&') constituirea listei numelor de fişiere şi invocarea lui pandoc pe această listă ("mai bine" pentru că variabila 'file_list' "dispare" dacă între timp terminalul în care o creasem a fost închis):
vb@Home:~/1-mar/fgPS/postscript$ file_list=(` cat sections.txt `) && pandoc -s \
-f html -t latex ${file_list[@]} \
-M title="A First Guide to PostScript" \
-M author="Peter Weingartner" \
-M date="24 February, 2006" \
-V colorlinks -V fontsize=12pt \
-o fgps.tex
Putem invoca imediat un compilator de LaTeX, pentru a vedea rezultatul PDF şi a ne da seama ce modificări ar fi de făcut pe fgps.tex:
vb@Home:~/1-mar/fgPS/postscript$ pdflatex fgps.tex
Apare o singură "eroare" - lipseşte o imagine (de la Creative Commons): "! Package pdftex.def Error: File `http://creativecommons.org/images/public/somerights20.png' not found: using draft setting."; putem descărca imaginea respectivă (în directorul de lucru curent) de la adresa indicată, apoi căutăm în fgps.tex şi actualizăm declaraţia de includere a imaginii: {\includegraphics{somerights20.png}}.
Compilând de două ori consecutiv, obţinem şi un "Index" - cum se vede pe imaginea următoare (prelevată din Document Viewer-ul în care am deschis PDF-ul obţinut):
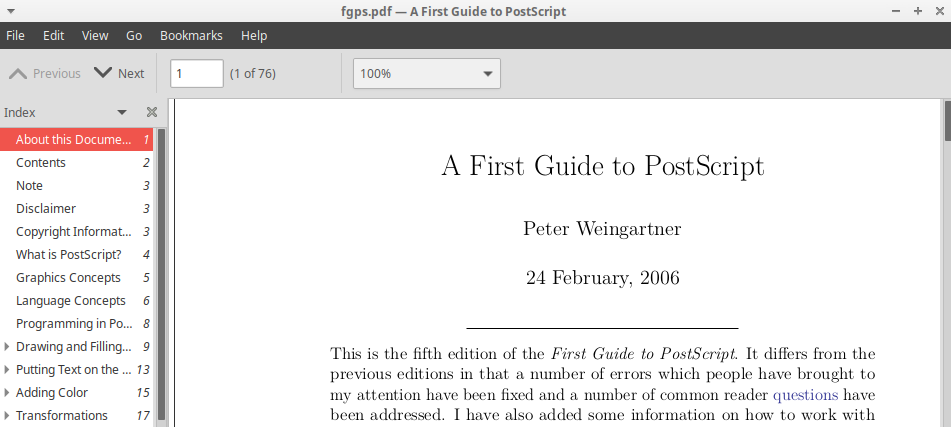
Având acest "Index", nu are sens să mai păstrăm "Contents" (de la pag. 2); deschidem într-un editor de text (gedit) fişierul fgps.tex, căutăm \subsection{Contents} şi ştergem secţiunea respectivă, apoi recompilăm (de două ori, consecutiv).
Obs. De fapt, acest "Index" apare numai la vizualizarea PDF-ului (de exemplu cu evince), nu şi când ar fi tipărit (caz în care s-ar cuveni ca secţiunea "Contents" să fie păstrată). Dar în general, tutorialele sunt parcurse folosind un "Document Viewer" (sau un browser).
Trebuie apoi să eliminăm liniile care conţin referirile la "Main/Next/Previous Page", precum \href{postscript.html}{Main Page} (şi sunt vreo 40 de linii…); cel mai simplu (şi mai sigur) este să creem un fişier "del_lines.txt" cu termenii care identifică liniile ce trebuie şterse şi să folosim grep cu opţiunea -v:
vb@Home:~/1-mar/fgPS/postscript$ cat del_lines.txt {Main Page} {Next Page} {Previous Page} vb@Home:~/1-mar/fgPS/postscript$ grep -Fvf del_lines.txt fgps.tex > fgps_.tex vb@Home:~/1-mar/fgPS/postscript$ mv fgps_.tex fgps.tex
grep -Fvf obţine şabloanele din fişierul indicat (opţiunea -f) del_lines.txt şi le interpretează ca şiruri fixate (nu ca expresii regulate) datorită opţiunii -F; în mod normal s-ar produce liniile din fişierul de intrare fgps.tex care se potrivesc şablonului dat - dar opţiunea -v inversează căutarea: exclude liniile care se potrivesc şablonului. Am redirectat ieşirea pe un fişier auxiliar fgps_.tex, pe care l-am "mutat" apoi (cu mv) peste fişierul iniţial fgps.tex. Recompilăm desigur (de două ori consecutiv), pentru a verifica PDF-ul rezultat.
Am avut grijă, când am invocat pandoc pentru a obţine fgps.tex, să setăm variabila booleană colorlinks, astfel că în PDF-ul rezultat acum, link-urile preluate din paginile HTML sunt colorate distinct (fiind astfel uşor de inspectat); dar putem obţine uşor o listă a tuturor acestor link-uri (rămânând de văzut ce-i de făcut într-un caz sau altul):
vb@Home:~/1-mar/fgPS/postscript$ grep -FnT "\href{" fgps.tex > links_html.txt vb@Home:~/1-mar/fgPS/postscript$ head -9 links_html.txt 87: common reader \href{faq.html}{questions} have been addressed. I have 91: \href{contacting.html}{e-mail} and let me know. I can't promise that 106: \href{http://www.tailrecursive.org/postscript/postscript.html}{official 108: \href{http://www.tailrecursive.org}{website}, where you can also find 115: \href{postscript.html\#note}{PostScript} page description language from 116: \href{http://www.adobe.com}{Adobe}. This document is not meant to be a 118: \href{operators.html\#opindex}{index} of some of PostScript's standard 119: operators and a list of various \href{errors.html}{errors}). There are 120: far better reference \href{books.html}{books}, if this is what you need.
Pentru exemplificare, am listat (prin head) primele 9 linii dintre cele 400 rezultate în fişierul "links_html.txt" în urma căutării cu grep a liniilor care conţin "\href{" (este de observat că pandoc ne-a ajutat: link-urile care în mod normal erau pe un acelaşi rând apar în fgps.tex pe rânduri separate).
Pentru unele dintre aceste link-uri este firesc să le înlocuim cu note de subsol; de exemplu, putem înlocui link-ul de pe linia 116 (păstrând cumva şi culoarea) cu {\color{blue}Adobe}\footnote{http://www.adobe.com}, iar pe cel de pe linia 108 cu {\color{blue}website}\footnote{http://www.tailrecursive.org}. Putem face "de probă" aceste modificări, dar ne dăm seama că întâi trebuie rezolvate link-uri precum cele din liniile 87 şi 120: fişierele vizate faq.html şi books.html (şi mai sunt alte câteva) nu figurează în lista sections.txt - deci probabil că ar trebui adăugate undeva la sfârşit, reexecutând apoi comanda pandoc (încât am obţine un nou fişier fgps.tex, iar modificările întreprinse anterior s-ar pierde).
Obs. Am putea înţelege acum, de ce s-a preferat formularea tutorialului ca site HTML: prin pagina "faq.html" autorul ar răspunde unor întrebări tocmai primite de la utilizatorii site-ului (ceea ce nu era posibil pentru formatul PDF); ignorăm totuşi această nuanţă, considerând că s-au colectat destule întrebări şi răspusuri.
După încă o investigare a fişierelor HTML iniţiale, am extins sections.txt (după ultimul item existent, errors.html) cu:
escapes.html
verbotten.html
resources.html
books.html
contacting.html
faq.html
şi bineînţeles, am reluat operaţiile descrise mai sus cu pandoc şi apoi cu grep (inclusiv, reconstituirea fişierului links_html.txt, care a devenit desigur, ceva mai mare). Între timp, m-am documentat (dar foarte sumar) în legătură cu posibilităţile de a seta în LaTeX nişte "link"-uri care să imite cumva pe cele din HTML; ca să fie "clikabile", trebuie folosit pachetul LaTeX hyperref (şi constatăm că pandoc l-a inclus deja, la sfârşitul preambulului, în fişierul LaTeX fgps.tex pe care l-a creat).
Pentru un link precum cel din linia 87 (\href{faq.html}{questions}) ar fi de făcut această înlocuire: \hyperref[frequently-asked-questions]{questions}, având în vedere că fgps.tex consemnează deja \section{Frequently Asked Questions}\label{frequently-asked-questions} (regula de bază ar fi deci: \hyperref[mark]{text} produce un link "clikabil" către obiectul indicat undeva în document prin \label{mark}). La fel, am înlocuit link-ul din linia 91 prin \hyperref[contacting-me]{e-mail} şi multe dintre link-urile existente se pretează la o asemenea înlocuire.
Am probat lucrurile pentru câteva asemenea înlocuiri, dar bineînţeles - caut un procedeu de automatizare şi mă gândesc dacă nu cumva mi-a scăpat ceva chiar din start (încât pandoc să fi putut rezolva automat şi chestiunea referinţelor la fişierele ".html", transformându-le în referinţe interne). Urmează deci să o iau de la capăt.
vezi Cărţile mele (de programare)