"Centralizatorul" Educaţiei Naţionale - de la Word la XML
În mod ideal, un document ar fi caracterizat prin consistenţa şi consecvenţa termenilor şi structurii generale şi printr-un grad acceptabil de stabilitate temporală; de regulă, documentele furnizate de instituţiile publice sunt produse ad-hoc (folosind MS-Word), fără vreo elaborare prealabilă.
Centralizatorul Educaţiei Naţionale
"Ministerul Educaţiei şi Cercetării" furnizează un document Anexă la ordinul ministrului educaţiei şi cercetării nr.178 /2007 care se intitulează pe prima pagină exact aşa:
C E N T R A L I Z A T O R
PRIVIND
DISCIPLINELE DE ÎNVĂŢĂMÂNT, DOMENIILE ŞI SPECIALIZĂRILE, PRECUM ŞI PROBELE DE CONCURS
VALABIL PENTRU ÎNCADRAREA PERSONALULUI DIDACTIC DIN
ÎNVĂŢĂMÂNTUL PREUNIVERSITAR
2007
Acest document este important în primul rând din punct de vedere procedural: dacă vrei să te titularizezi pe o catedră, sau să obţii ore într-o altă disciplină decât cea pe care eşti încadrat, atunci trebuie să consulţi Centralizatorul şi să vezi dacă specializarea ta (înscrisă pe diploma de licenţă) figurează în dreptul catedrei pentru care optezi.
Acest document este chiar mai important, dintr-un punct de vedere mai general: el oferă imaginea întregului sistem de educaţie destinat să formeze corpul profesoral calificat din învăţământul românesc şi este (sau se vrea) exhaustiv în acest sens.
Geneza Centralizatorului educaţiei naţionale
Ne-am lămurit cumva, prin mail:
...problema Centralizatorului este a Directiei Generale Managementul Resurselor Umane...
"Centralizatorul a aparut din cauza prevederilor extrem de restrictive din Statutul personalului didactic, care solicita sa formam catedrele in specialitatea de pe diploma. Din cauza marii diversitati a numelor specializarilor din invatamantul superior, aceasta prevedere ar fi lasat in afara sistemului o multime de oameni. Din aceasta cauza a inceput elaborarea centralizatorului, care a largit mult aria specializarilor care permit titularizarea. Centralizatorul a fost largit in fiecare an, de multe ori in urma unor solicitari de la cadre didactice. Aceasta largire a permis multor cadre didactice sa participe la titularizare, ceea ce nu s-ar fi intamplat daca el nu exista."
(nota mea) "Centralizatorul Educaţiei Naţionale" este deci, o instituţionalizare a zorzoanelor sindicale? rezultatul multiplelor reguli, "articole de Regulament" şi de "Statut" chiţibuşite de vechii şi mai noii noştri "reprezentanţi"? Aş afirma măcar (că se ştie - nu-i nicio pagubă!), declinarea apartenenţei la un sindicat care în fond este un generator şi manipulator de birocraţie vulgară.
E greu să lămureşti pe cineva, că de la "diplomă" şi până la "specialitate" sau specializare este cale lungă!
Prezentarea documentului
În situaţia stresantă de a fi descalificat, a trebuit să caut pe edu.ro "Centralizatorul privind disciplinele de învaţământ, domeniile şi specializările, precum şi probele de concurs, valabil pentru încadrarea personalului didactic din învăţământul preuniversitar 2007, aprobat prin O.M.Ed.C. nr. 178/2007".
Am găsit anexe OMEdC 178.zip, un fişier de 1.13 MO. L-am descărcat; arhiva respectivă conţine 4 fişiere de tip "MS-Word document", totalizând aproape 15 MO; am ales Centralizator 2007 (cultura generală...) şi am dezarhivat, obţinând un fişier DOC de aproape 5 MO. Am ales să-l deschid cu OOo (OpenOffice.org este o suită de programe open-source care pot fi utilizate pe orice platformă—Linux, Windows, Mac—în loc de MS-Word, Excel şi PowerPoint specifice Windows).
Documentul are 76 de pagini şi o fi bine realizat cât timp scopul asumat este numai acela de a tipări pe hârtie (formatul chiar este "landscape", deci adresat paginii de hârtie). Însă este mai util (şi mai firesc astăzi, când accesul la Internet este la îndemâna tuturor) să se ofere posibilitatea de a răsfoi documentul direct din browser (fără a impune utilizatorului să aibă instalată cutare aplicaţie).
OpenOffice.org permite între altele, exportul unui fişier DOC într-un fişier PDF (formatul DOC este particular Microsoft Windows+Office, din motive comerciale evidente; PDF este un format portabil, universal). Documentul original avea dimensiunea de 5 MO (= 5120 KO); fişierul PDF rezultat de sub OpenOffice Writer are mai puţin de 950 KO (v. Centralizator.pdf). Folosind apoi modulul Perl Image::Magick::Thumbnail::PDF, am obţinut un fişier PNG corespunzător paginii 35, redat parţial aici:
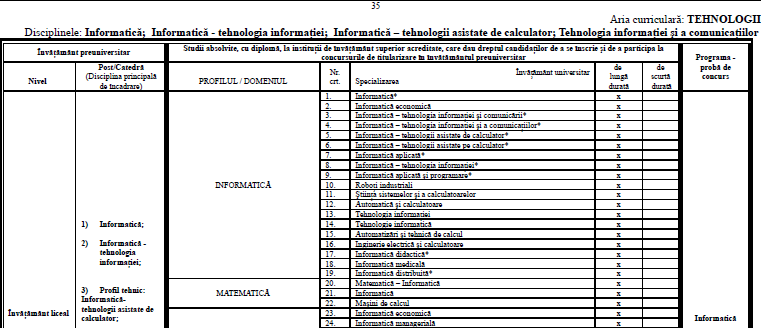
Documentul original (acum, de 5 MO) se prezintă ca un tabel continuu, desfăşurat pe 75 de pagini, cu antetul aproape invariabil; căutarea este asigurată prin meniul "Find..." din Word; dacă e cazul de a adăuga/şterge ceva (un rând de tabel, sau un item într-o coloană) atunci trebuie să ai grijă să nu strici formatarea paginii, să repaginezi, etc. (iar pe de altă parte, modificarea respectivă trebuie operată a doua oară, în altă parte: în cadrul "sistemului computerizat"!)
Nu poate să fie aceasta (folosind Word) calea recomandată astăzi, pentru realizarea, întreţinerea şi accesarea unor asemenea documente!
Încercăm să vedem cum putem elabora (la nivel conceptual) şi cum putem realiza tehnic asemenea documente, încât să evităm defecţiunile evidenţiate mai sus - adică să obţinem un document uşor de accesat prin Internet, de o dimensiune rezonabilă, vizibil (şi printabil) din browser (fără impuneri de sistem de operare sau de pachete "Office"), eventual cu posibilităţi fireşti de acces direct la anumite secţiuni, cu posibilităţi comode şi extensibile de "formatare" şi astfel încât modificarea eventuală a datelor să se facă într-un singur loc (fiind automat propagată în toate componentele, inclusiv în "sistemul computerizat").
Ideea fundamentală este clasică: separarea datelor propriu-zise, faţă de aspectele care ţin de prezentarea datelor; este evident că aceleaşi date pot fi prezentate în diverse forme: de tabel, de listă secvenţială numerotată sau nu, sau sub o formă arborescentă, etc.
Structura datelor înregistrate în tabel
Coloana care este denumită în antetul tabelului Nivel, are următoarele valori (repetate pe diverse pagini, cu formatare neunitară): Învăţământ preşcolar; Învăţământ primar; Învăţământ liceal/Şcoală de arte si meserii/Anul de completare/Învăţământ gimnazial; Învăţământ liceal; Învăţământ gimnazial; Învăţământ sportiv; Învăţământ special; CJAPP/Cabinet asistenţă psihopedagogică.
Coloana Catedra/Postul de încadrare—denumită pe alte pagini şi "Post/Catedră (Disciplină principală de încadrare)"—are şi ea valori predeterminate, precum: Educatoare; Învăţător; Limba şi literatura română; Limba latină; Matematica ş.a.m.d. Aceste valori sunt într-o anumită corelaţie cu valorile din prima coloană (de exemplu, la Nivel="Învăţământ liceal" nu putem avea Catedră/Post="Educatoare").
Aceleaşi observaţii sunt valabile si pentru celelalte coloane; de exemplu, coloana Profilul/Domeniul are valorile "SOCIOPSIHOPEDAGOGIE", "Pedagogie", "Filologie", "Teologie", "Istorie" etc. aflate în corelaţii evidente cu valorile din primele două coloane.
În treacăt să zicem, nu putem înţelege pe aceştia care scriu cuvintele cu MAJUSCULE; care scriu odată "Învăţământ liceal" şi apoi în aceeaşi coloană "Învăţă-mânt liceal"; care cred că în contextul de faţă, "Învăţător-maistru" este o categorie diferită de "Învăţătoare-maistră".
Prin urmare, tabelul respectiv—cum se şi cuvine pentru un tabel—este mai mult decât o simplă dispunere de date arbitrare, pe linii si coloane; el conţine date specifice fiecărei coloane, coloanele sunt relaţionate între ele în sensul că unei valori anumite dintr-o coloană îi corespunde o anumită gamă predeterminată de valori în alte coloane, iar valorile existente reprezintă în general nişte termeni standard predefiniţi.
Dacă structura tabelului ar fi bine gândită de la bun început, atunci ea va fi valabilă pe o perioadă mare de timp; dar datele din tabel vor trebui modificate destul de frecvent, datorită modificării contextului pe care ele trebuie să-l reprezinte (apar modificări de concepţie şi de structură a sistemului de învăţământ, cu implicaţii asupra "profilelor", "catedrelor", "specializărilor" etc.). Este foarte nepotrivit să foloseşti Word pentru tabele în care datele urmează să se modifice, fiindcă vei fi obligat la diverse operaţii de reformatare, de repaginare, etc.
Pentru problemele care trebuie rezolvate pe tabele corelate în care datele pot să varieze, dispunem de sistemele de "gestiune a bazelor de date" (SGBD); pentru a modela "Centralizatorul" folosind SGBD, am începe probabil prin a asocia fiecărei coloane câte un tabel de valori posibile şi prin a defini relaţionările necesare între aceste tabele. Pe lângă SGBD, dispunem şi de alte limbaje (bazate pe XML) care de asemenea permit definirea structurii documentului, înregistrarea într-un format "simplu" a datelor pe care trebuie să le conţină documentul şi specificarea a diverse formate de afişare, tipărire sau transmitere a documentului (în plus, XML este recunoscut şi de browserele moderne).
La pag. 65 apare sub-tabelul "LISTA DISCIPLINELOR DE ARTE VIZUALE CODIFICATE ...", iar la pag. 70 "Abrevieri pentru fiecare disciplină de la specializările muzică, teatru, coregrafie"; aceste tabele asociază nişte coduri/abrevieri diverselor discipline din aria "Arte", servind pentru a putea referi mai scurt aceste discipline din cadrul tabelului de bază. Aceste tabele de coduri ar putea fi poate necesare doar în situaţia tipăririi pe hârtie a întregului document; ele devin inutile daca e vorba numai de vizualizare/răsfoire din browser a documentului şi ele sunt oricum inutile, dacă folosim tabele relaţionate (SGBD).
Există această notă explicativă, la subsolul pag. 70:
Notă. Abrevierile au fost făcute în vederea introducerii datelor în sistemul computerizat.
…Acum e clar - este un "sistem computerizat" bazat pe cartele perforate (1960-80).
Structura tipică a unei aplicaţii Web pentru documente tabelare
În principiu, o aplicaţie Web care să permită editări/vizualizări/actualizări etc. pe tabele precum cel descris mai sus, conţine trei componente (cu sarcini specifice) cu denumirile standard Model, Controller şi View. Am reţinut de undeva, datorită conciziei: The View should handle everything specific to HTML rendering, and the Controller should really be a very thin translation layer that maps HTTP inputs into View updates and Model calls.
Model, View, Controller
Partea de Model-are face legătura între SGBD-ul implicat pentru gestionarea la nivel de fişier a tabelelor de date pe de o parte şi limbajul de bază folosit de aplicaţie, pe de altă parte; practic, Model-ul descrie în limbajul aplicaţiei tabelele şi relaţiile respective, furnizând la nivelul limbajului aplicaţiei variabile/obiecte de memorie corespunzătoare grupurilor de date corelate din cadrul fişierelor care păstrează tabelele respective; subrutinele destinate prelucrării datelor vor cere eventual Model-ului să aducă în memorie datele corespunzătoare aflate pe disk şi apoi vor opera cu variabilele de memorie obţinute.
Partea de View are rolul de a "formata" conform unor şabloane prespecificate (cunoscute de către browsere), datele care trebuie prezentate în final utilizatorului aplicaţiei. Controller-ul controlează întregul flux al aplicaţiei; conţine modulele necesare pentru a analiza cererile de informaţii venite de la clienţii aplicaţiei, pentru a obţine prin intermediul componentei Model datele necesare, pentru a le prelucra conform cererii, pentru a furniza părtii View datele de afişat drept răspuns.
Sarcinile de bază ale unui Controller sunt în fond cerinţe comune tuturor aplicaţiilor Web; de exemplu, toate aplicaţiile Web au nevoie să gestioneze corect conexiunile, cererile şi răspunsurile cu/dinspre/către clienţi. Există deja multe framework-uri care pot fi utilizate drept Controller, rămânând doar să adaptăm/adaugăm unele submodule pentru a ţine cont de aspectele particulare aplicaţiei concrete respective. Cam la fel stau lucrurile şi privind (independent) celelalte două componente, Model şi View.
Integrare şi genericitate
Dar a folosi toate acestea în scopul de a realiza o aplicaţie dedicată unui singur document (tabelul de pe cele 75 de pagini) este o idee susceptibilă de ridicol. În realitate, cadrul obişnuit acestei situaţii asumă că deja a fost creată o aplicaţie mai generală—cu scopuri sau oferte multiple—şi aceasta deja conţine Controller şi View, eventual şi Model; "aplicaţia" aferentă documentului nostru trebuie doar integrată aplicaţiei-context existente, iar pentru aceasta de obicei trebuie adăugat un submodul Controller-ului existent şi un submodul Model-ului existent (definind desigur şi tabelele necesare la nivelul SGBD).
Desigur, ar fi mai interesant de realizat o aplicaţie generică, pregătită să deservească oricare document tabelar de genul celui despre care este vorba aici. S-ar cere utilizatorului furnizarea unui fişier text conţinând într-un anumit format, definiţiile de tabele şi relaţii; aplicaţia va instanţia apoi, submodulele de Controller şi Model corespunzător definiţiilor primite - permiţând astfel ca acel document să poată fi răsfoit/investigat/tipărit etc. (fără a apela la Word!). Partea cea mai dificilă ar fi conceperea modalităţii de definire a tabelelor şi relaţiilor şi conceperea unui modul de verificare a acestor definiţii; altfel poate că aplicaţia este uşor de realizat…
De fapt, există deja o asemenea "aplicaţie generică" (pregătită pentru orice document "tabelar"): gama de limbaje XML, XSLT, XPath, etc.; aceste limbaje—apărute acum vreo 10 ani şi în continuă evoluţie— sunt deja încorporate în browserele moderne; ceea ce indicam mai sus ca fiind "partea cea mai dificilă" ar corespunde în XML cu partea de Document Type Definition. Ar fi de menţionat că de fapt, XML este un instrument de elaborare folosit de mult timp în multe aplicaţii - inclusiv pentru realizarea produselor din gama Microsoft-Office!
Conceperea bazei de date asociate
Este important ca atunci când elaborezi o aplicaţie Web să te gândeşti la utilizator şi să încerci să te pui în locul lui. Eu am căutat pe edu.ro informaţii curente despre specializările care te califică să predai informatică; mi s-a oferit un document, acesta a trebuit download-at, dezarhivat şi deschis într-o anumită aplicaţie de vizualizare, derulând apoi paginile pănă am aflat ce mă interesa. Dar ce aş fi vrut eu, sau oricare utilizator? Aş fi vrut cam aşa: să pot indica/selecta Nivel-ul (în cazul de faţă "Liceal"), apoi Profil/Domeniu (în cazul de faţă "Informatică") şi probabil cam atât - şi să mi se afişeze drept răspuns, lista existentă de Specializări prevăzute, împreună cu eventualele atribute suplimentare şi cu Note-le "de subsol" aferente (fără să fiu obligat să downloadez, să dezarhivez, să intru în Word, etc.).
Specificarea tabelelor şi relaţiilor
În cazul de faţă am încercat întâi (vizând şi interesul utilizatorului) o simplificare a concepţiei, plecând de la faptul că, totuşi, elementul esenţial este "Specializarea"; utilizatorul ar introduce sau selecta "specializarea" sa (şi probabil, "nivelul-de-studii" aferent), iar ca răspuns trebuie să obţină o listă cu profile-domenii, posturi-catedre-discipline, nivele şi note-de-subsol corespunzător specializării indicate. Prin urmare, am pleca de la un tabel care să conţină toate specializările distincte existente; o înregistrare din acest tabel corespunde eventual la mai multe Nivele-de-studii; perechea (specializare, nivel-de-studii) corespunde eventual la mai multe Profile, la mai multe Posturi, etc.
Până la urmă am abandonat această idee; pe acest teren stufos al nomenclatoarelor oficiale sunt mici şansele de a ajunge la o structură de tabele acceptabilă. Ne-am mulţumi deocamdată ca această structură să permită interogările aşteptate, chiar dacă formulările SQL necesare ar putea fi mai complicate decât s-ar cuveni:
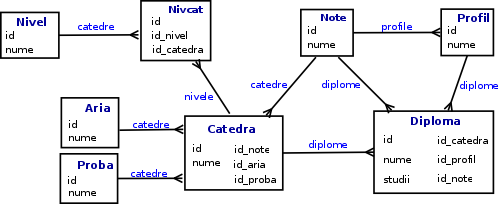
Pe această diagramă săgeţile şi etichetele aferente (marcate prin culoarea albstru) reprezintă relaţiile "has_many" (acestea vor fi definite la nivelul Model-ului, ulterior); câmpurile numite "id" sunt "primary keys" (permiţând identificarea unică a înregistrării în tabel), iar câmpurile cu numele prefixat prin "id_" sunt "foreign keys" (permiţând relaţionarea "one-to-many" cu alte tabele).
Denumirile tabelelor vor fi utilizate intern (şi pot fi arbitrare); toate valorile câmpurilor denumite "nume" vor trebui preluate din nomenclatoarele oficiale (o denumire cam pompoasă aici - fiindcă nu vom consulta Monitorul Oficial, ci ne vom baza doar pe datele înscrise în "Centralizatorul" de la edu.ro). Ca să clarificăm, indicăm aleatoriu câteva valori ale câmpului "nume" pentru fiecare tabel:
Nivel: "Învăţământ preşcolar", "Învăţământ primar", "Învăţământ liceal",
"Învăţământ sportiv (vocaţional)", "Cluburi sportive şcolare",
"Palatele copiilor", "CJAPP Cabinet asistenţă psihopedagogică", etc.
Aria: "Educatoare", "Învăţător", "Limbă şi comunicare", "Tehnologii", "Arte",
"Om şi societate", "CJAPP Cabinet asistenţă psihopedagogică",
"Matematică şi ştiinţe ale naturii", etc.
Catedra: "Educatoare", "Limba şi literatura română", "Informatică",
"Educaţie vizuală", "Istorie", "Educaţie fizică şi sport",
"Kinetoterapie", "Cultură civică", etc.
Profil: "Sociopsihopedagogie", "Pedagogie", "Pedagogic", "Filologie",
"Economic", "Matematică", "Ştiinţe economice",
"Artă teatrală/Teatru", "Mecatronică", etc.
Diploma: "Institutori - Cultură fizică - euritmie", "Filologie clasică",
"Limbi clasice", "Inginerie electrică şi calculatoare",
"Calculatoare", "Cibernetică", etc.
Această structurare a tabelelor—cât ar părea de urâtă—este acceptabilă în măsura în care poate deservi o interogare sau alta. De exemplu, se cere lista specializărilor admise pentru a participa la un concurs de titularizare pe o catedră din aria curriculară "Tehnologii" în învăţământul liceal. Presupunem că vom fi înregistrat datele în tabele şi avem înregistrările (nume="Tehnologii", id=5) în tabelul Aria şi respectiv (nume="Învăţământ liceal", id=3) în tabelul Nivel. Atunci rezultatul cerut se poate obţine prin următoarea formulă SQL:
SELECT * FROM Diploma, Nivcat, Catedra
WHERE Nivcat.id_nivel = 3 AND
Catedra.id_aria = 5 AND
Nivcat.id_catedra = Catedra.id AND
Diploma.id_catedra = Catedra.id;
Optimizări?
Tabelul auxiliar Nivcat a fost considerat în scopul de a înregistra relaţii "many-to-many" între tabelele Nivel şi Catedra. Dar valorile din Nivel sunt în număr de 17 (în orice caz, mai mic decât 32); prin urmare, putem renunţa la tabelele Nivcat şi Nivel, considerând valorile din Nivel drept constante predefinite şi adăugând în Catedra un câmp de 32 de biţi în care biţii corespund univoc "nivelelor" constante existente (la fel şi cu "studii" din tabelul Diploma: biţii din acest câmp reprezintă univoc valorile posibile pentru "studii", adică "învăţământ universitar de lungă durată", "învăţământ universitar de scurtă durată", "învăţământ liceal", etc.).
Cu aceeaşi justificare, vom renunţa şi la tabelul Aria (sunt numai vreo 10 "arii curriculare", încât putem considera un câmp numeric în tabelul Catedra, care să indice aria corespunzătoare dintr-un tabel de constante literale). Dar probabil că la fel vom proceda şi pentru tabelul Note (notele de subsol sunt multe, însă sunt multe care se repetă): vom include câte un câmp numeric corespunzător notelor de subsol respectiv în tabelele Catedra, Diploma şi Profil. Astfel că în final, baza de date e formată numai din aceste trei tabele, fiindcă şi Proba este în aceeaşi situaţie cu tabelele deja eliminate.
Reducerea la doar trei tabele prezentată mai sus este avantajoasă după criteriile obişnuite (spaţiu de memorie şi timp de acces); dar ar apărea un dezavantaj important dacă am avea în vedere o eventuală conversie automată a bazei de date într-un document XML. Până la urmă, procedeele standard (stochează toate datele într-o bază de date) sunt preferabile celor "ingenioase" (unele date în fişiere-text, altele într-o bază de date simplificată, din cadrul căreia se vor referi unele date din fişierele-text).
Preluarea şi înregistrarea datelor în tabele
Cum să extrag valorile necesare tabelelor instituite mai sus, din fişierul DOC original? De exemplu, trebuie extrase denumirile înscrise în coloana "Profil/Domeniu" şi înregistrate în coloana "nume" din tabelul Profil. Încercăm într-o doară, din Word (OpenOffice în cazul meu) folosind desigur Copy&Paste, dar constatăm că nici măcar nu se poate selecta întreaga coloană (ci doar porţiunea corespunzătoare paginii vizibile a documentului - semn că s-au definit numeroase tabele Word, cu setări particulare privind coloanele); să abandonăm procedeele de tip "click-and-point" (acestea ar trebui folosite manual pe fiecare DOC şi tabel în parte) şi să căutăm tehnici de lucru mai generale.
Prima operaţie care trebuie făcută indiferent cum am continua apoi, constă în exportarea fişierului DOC original într-un fişier HTML, să-i zicem "centr.html"; preferăm trecerea de la DOC la HTML direct din Word - în cazul de faţă rezultă un HTML de 1.7 MO, de nivel foarte coborât (având de exemplu LANG="ro-RO" CLASS="western" şi FONT SIZE= cam pe la fiecare element).
Putem folosi acum "centr.html", pentru a observa câteva aspecte de structură a documentului MS-Word iniţial (aspecte care erau incomod sau chiar imposibil de observat din Word); de exemplu, introducând într-un terminal:
grep '<TABLE' centr.html | wc -l
determinăm numărul de tabele care au fost create în documentul MS-Word iniţial, anume 165 de "tabele" (wc numără—Word Count—cuvintele indicate). Asemănător, găsim că dintre aceste 165 de tabele un număr de 18 tabele au structura următoare (şi ne dăm seama uşor că această structură corespunde unei pagini "principale"):
<TABLE WIDTH=977 BORDER=1 BORDERCOLOR="#000000" CELLPADDING=7 CELLSPACING=1> <COL WIDTH=70> <COL WIDTH=110> <COL WIDTH=160> <COL WIDTH=22> <COL WIDTH=229> <COL WIDTH=60> <COL WIDTH=47> <COL WIDTH=40> <COL WIDTH=101>
Dacă am mai adăuga şi alte observaţii de acest gen (privind folosirea paragrafelor, formatările individuale diverse utilizate, separarea cuvintelor în silabe, etc. - cam toate defectuoase) am dovedi definitiv că documentul MS-Word iniţial este lipsit de o concepţie unitară şi în fond este prost realizat - dar nu-i acesta scopul nostru aici; doar să precizăm că documentul respectiv se putea structura categoric mai bine şi se putea realiza cu mult mai puţină muncă folosind (într-un editor de text obişnuit) HTML şi CSS (şi rezulta un fişier mult mai scurt, care poate arăta bine şi în browser şi ca document tipărit pe hârtie).
Am obţinut deci "centr.html"; mai departe, avem cel puţin următoarele trei-patru posibilităţi de a extrage textele care ne interesează:
— folosim HTML::TableExtract în cadrul unui script perl, obţinând variabile de memorie corespunzătoare conţinutului-text din elementele <TD> ale tabelelor existente în "centr.html"; scriptul respectiv va trebui să filtreze variabilele obţinute şi să le insereze corespunzător în tabelele MySQL. Această idee ar fi cea mai bună, fiindcă nu angajează aplicaţii intermediare.
— încărcăm "centr.html" sub Gnumeric Spreadsheet (aplicaţie open-source similară cu Microsoft-Excel) şi îl salvăm în format CSV ("Comma Separated Values") - rămânând de conceput un script care să parseze "centr.csv" pentru a extrage datele corespunzător tabelelor noastre. Iată cum arată partea iniţială a fişierului CSV:
Observăm fie şi pe această porţiune, că unii termeni apar în forme diferite, ceea ce va impune prelucrări suplimentare înainte de a-i înscrie în tabelele MySQL (de exemplu, avem "Învăţământ" dar şi "Învăţă-mânt").
— încărcăm "centr.html" în browserul lynx, selectăm tot conţinutul şi salvăm; rezultă un fişier text de circa 150 KO, cu exact aceeaşi formă ca a DOC-ului (dar fără liniatură); va trebui un script care să analizeze fişierul-text obţinut, pentru a extrage datele corespunzător coloanelor.
— (probabil cea mai eficace): se încarcă DOC-ul original (cu formatul MS-Word) în OpenOffice.org Writer şi se exportă de aici în formatul sxw (care este o arhivă de fişiere XML); se dezarhivează fişierul sxw şi se implică un modul Perl precum XML::Twig asupra fişierului XML obţinut (sunt necesare numai câteva linii de program pentru a extrage textele care interesează şi a le înscrie în acelaşi timp în tabelele MySQL).
Eu am parcurs măcar parţial, mai toate procedeele prezentate mai sus; nu-mi pare rău că am pierdut vremea, fiindcă am mai învăţat câte ceva - e drept, în afara "specializării" fixate de deasupra de către Centralizatoare.
Dar am ajuns la concluzia fermă că DOC-ul original este oribil realizat şi soluţia cea mai bună începe totuşi cu ceea ce am tot încercat să evit până acum: editează "centr.html" încât să restructurezi tabelele (păstrând dintre cele 165 existente numai pe cele câteva care sunt necesare), să le prevezi cu ID-uri care să-ţi permită ulterior să le accesezi din scripturi, să elimini enorm de multele şi inutilele elemente paragraf <p>, să elimini elementele demodate precum FONT şi altele, etc. etc., să defineşti un stylesheet pentru ecran şi unul pentru print în locul enorm de multele atributări din "centr.html"-ul iniţial…
Cu alte cuvinte, am ajuns aici să ne propunem s-o luăm de la capăt… Dar "nu ne retragem, ci avansăm într-o altă direcţie": vom încerca să rescriem documentul folosind XML.
Conceperea documentului folosind XML
Subliniem că documentele XML se pot realiza de la un cap la altul folosind un editor de text obişnuit (nu "procesorul de text" Word!. Este aberant, dar încă este real: cunoştinţele elementare de informatică oferite în şcoală sau la "cursuri de formare" nu vizează aproape de loc editoarele de text obişnuite, implicând numai aplicaţii de tip "point-and-click" şi numai "medii integrate de dezvoltare").
Întâi trebuie concepută structura documentului - ce secţiuni şi subsecţiuni are, cu ce legături între ele; odată ce am definit astfel documentul, se vor putea insera datele corespunzătoare (respectând regulile definite). Într-o altă etapă, va trebui să se asocieze documentului rezultat unul sau mai multe programe care să asigure prezentarea documentului într-un format sau altul, eventual pentru un dispozitiv sau altul.
Definirea structurii documentului; DTD şi DOCTYPE
XML (eXtended Markup Language) îţi permite să constitui un limbaj pentru a reflecta domeniul de cunoştinţe specific datelor respective, începând de la stabilirea unor denumiri potrivite şi continuând cu definirea regulilor pe care trebuie să le respecte elementele în cadrul documentului: ce fel de date trebuie să conţină elementul, ce sub-elemente poate să aibă un element, ce atribute (de exemplu, referiri la alte elemente).
De obicei, prima parte dintr-un document XML este destinată pentru definirea vocabularului şi a regulilor de folosire ("gramatica limbajului") şi este denumită DTD (Document Type Definition); după DTD urmează de obicei, datele propriu-zise exprimate în strictă concordanţă cu DTD.
Limitând dezvoltarea doar la scopuri didactice, vom căuta să adaptăm structura deja existentă a "Centralizatorului" (altfel, ar fi sarcina specialiştilor în domeniul de cunoştinţe respectiv, de a stabili elementele de bază ale documentelor specifice). Elementul esenţial în "Centralizator" este "specializarea", dar fiecare "specializare" este încadrată unei anumite "arii curriculare", unui anumit "domeniu", "catedre" etc.
Am ales să definim întâi elementele (care în fond corespund unor date predefinite, modificabile însă şi extensibile): discipline, probe de concurs, note de subsol, studii, nivele de învăţământ, catedre şi domenii; fiecare element are asociat un identificator unic, astfel încât el să poată fi referit dintr-un alt element; unele elemente au asociate referiri către alte elemente (de exemplu, o instanţă concretă a elementului catedre poate să refere eventual anumite instanţe ale elementului probe, cu semnificaţia că pentru ocuparea catedrei respective, concursul prevede acele probe):
<!-- fişierul "centralizator.xml" --> <?xml version="1.0" encoding="UTF-8"?> <!--declară că urmează un document XML--> <?xml-stylesheet type="text/xsl" href="centralizator.xsl"?> <!--asociază un program de redare--> <!--urmează DTD şi apoi, documentul propriu-zis, respectând regulile DTD --> <!DOCTYPE centralizator [ <!--precizează elementul 'rădăcină' pentru document--> <!ELEMENT centralizator ( discipline, probe, note, studii, nivele, catedre, domenii, Aria+ )> <!--'centralizator' cuprinde întâi lista disciplinelor, apoi lista probelor, lista ... şi apoi în final, una sau mai multe secţiuni 'Aria'--> <!ELEMENT discipline (disp+)> <!--unul sau mai multe elemente 'disp'--> <!ELEMENT disp (#PCDATA)> <!--denumirea disciplinei--> <!ATTLIST disp id ID #REQUIRED> <!--valoarea 'id' identifică unic disciplina--> <!ELEMENT probe (prob+)> <!--unul sau mai multe elemente 'prob'--> <!ELEMENT prob (#PCDATA)> <!ATTLIST prob id ID #REQUIRED> <!ELEMENT note (nota+)> <!ELEMENT nota (#PCDATA)> <!ATTLIST nota id ID #REQUIRED> <!ELEMENT studii (stud+)> <!ELEMENT stud (#PCDATA)> <!ATTLIST stud id ID #REQUIRED> <!ELEMENT nivele (niv+)> <!ELEMENT niv (#PCDATA)> <!ATTLIST niv id ID #REQUIRED> <!ELEMENT catedre (catd+)> <!ELEMENT catd (#PCDATA)> <!ATTLIST catd id ID #REQUIRED prob IDREFS #IMPLIED> <!ELEMENT domenii (domn+)> <!ELEMENT domn (#PCDATA)> <!ATTLIST domn id ID #REQUIRED prob IDREFS #IMPLIED stud IDREFS #REQUIRED> <!ELEMENT Aria (nume, Nivel+)> <!ELEMENT nume (#PCDATA)> <!ATTLIST Aria id ID #REQUIRED disp IDREFS #IMPLIED nota IDREFS #IMPLIED prob IDREFS #IMPLIED> <!ELEMENT Nivel (Catedra+)> <!ATTLIST Nivel niv IDREFS #REQUIRED> <!ELEMENT Catedra (Domeniu+)> <!ATTLIST Catedra catd IDREFS #REQUIRED prob IDREFS #IMPLIED> <!ELEMENT Domeniu (Spec+)> <!ATTLIST Domeniu domn IDREFS #REQUIRED niv IDREFS #IMPLIED> <!ELEMENT Spec (#PCDATA)> <!ATTLIST Spec stud IDREFS #IMPLIED nota IDREFS #IMPLIED> ]>
HTML 4.01 Strict DTD validează numai elementele şi atributele care n-au fost declarate deprecated; de exemplu, <FONT> care apare cam pe fiecare rând în HTML-urile rezultate prin conversia cu Word a documentelor MS-DOC - este deprecated; de asemenea, strict.dtd impune scrierea tag-urilor obişnuite cu litere mici (nu cu majuscule!), etc.
Pentru "centralizator.xml", DOCTYPE defineşte mai sus elementele (discipline, disp, Aria, etc.) folosind <!ELEMENT, defineşte atributele asociate (id de tip ID, stud de tip IDREFS, niv etc.) folosind <!ATTLIST, precum şi relaţiile posibile între elemente (de exemplu, o instanţă a elementului Aria subordonează obligatoriu o instanţă de element nume, urmată de una sau mai multe instanţe Nivel; o instanţă Spec poate referi prin atributele opţionale stud, nota unul sau mai multe elemente din document).
Ar fi fost de dorit ca DTD-ul pentru centralizator să fie constituit într-un fişier separat şi nu specificat direct în documentul XML, cum facem aici; avantajul ar fi de exemplu, că mai multe documente XML (bazate pe aceeaşi structură) ar putea folosi atunci, DTD-ul respectiv. Dar trebuie până la urmă să ţinem seama de un fapt: XML şi tehnologiile asociate au apărut treptat, n-au nici 10 ani vechime şi ele au început să fie implementate în browsere abia de câţiva ani; mecanismele respective sunt numai parţial implementate şi este prudent să se folosească numai părţile de bază ale lor, cu atât mai mult cu cât implementările şi diferă uneori, de la browser la browser.
Adăugarea datelor în centralizator.xml
Aşa cum am arătat mai sus (în secţiunea Preluarea şi înregistrarea datelor în tabele), am obţinut (din fişierul DOC original) nişte fişiere text conţinând respectiv lista disciplinelor, a catedrelor, a specializărilor, etc.
Fiecare linie dintr-un asemenea fişier ar trebui acum "ambalată" într-un tag corespunzător şi apoi înregistrată în locul cuvenit din "centralizator.xml"; de exemplu, linia care conţine "Limba şi literatura română" (din fişierul "discipline.txt") trebuie să devină:
<disp id="disp1">Limba şi literatura română</disp>
pentru a fi plasată în interiorul elementului <discipline> în "centralizator.xml".
Următorul program perl este tipic pentru acest scop:
#!/usr/bin/perl -w # repl-in-txt.pl TAG_TO_INSERT FRAG_ID INPUT_FILE OUTPUT_FILE # va înlocui fiecare linie din INPUT_FILE cu # <TAG_TO_INSERT id="FRAG_IDnumber">linie</TAG_TO_INSERT> # unde sufixul 'number' este 1, 2, ... # (dacă FRAG_ID este '', nu se mai adaugă atributul ID) my $tag = shift; my $pref = shift; # preia parametrii din linia de apel my $f1 = shift; my $f2 = shift; open(f1, "<", $f1); my @rw = <f1>; # tabloul liniilor din fişierul INPUT_FILE close f1; open(f2, ">", $f2); # urmează scrierea în OUTPUT_FILE if(!$pref) { # fără atributul ID foreach my $w (@rw) { chomp $w; # elimină ENDLINE print f2 "<".$tag.">".$w."</".$tag.">\n"; } } else { # cu atribut ID, prefixat cu $pref şi incrementat my $i = 1; foreach my $w (@rw) { chomp $w; print f2 "<".$tag." id=\"".$pref.$i."\">".$w."</".$tag.">\n"; $i ++; } } close f2;
Astfel, prin apelul:
./repl-in-txt.pl disp disp discipline.txt disp.txt
am obţinut fişierul "disp.txt" conţinând cele 101 denumiri de discipline din "discipline.txt", fiecare fiind încadrată între <disp id="dispNR_ORDINE"> şi </disp>; n-am făcut apoi decât să selectăm conţinutul fişierului obţinut (în speţă "disp.txt"), să-l copiem şi să-l pastăm în "centralizator.xml" (în cazul de faţă, între tagurile <discipline> şi </discipline>).
Procedând la fel pentru celelalte fişiere text (conţinând respectiv 62 de probe, 79 catedre, 95 domenii, etc.; cu specializările a fost ceva mai complicat, trebuind să adaptăm programul "repl-in-txt.pl" şi să operăm pe "arii curriculare"), iar apoi operând manual o serie de ajustări în "centralizator.xml" (pentru setarea corectă a referinţelor de tip IDREFS, intercalarea de elemente <Nivel> etc.) - am obţinut fişierul centralizator.xml, în care însă încă nu am reuşit să terminăm toate ajustările manuale necesare (ne-am ocupat numai de primele trei "arii curriculare" din DOC-ul original, iar a treia dintre acestea este chiar incomplet operată).
Oricum, pentru scopurile de natură didactică pe care ni le-am fixat aici - este suficient şi chiar este potrivit acum (şi nu după ce am termina înregistrarea tuturor datelor!) să ne preocupăm de asocierea unui program prin care să transformăm "centralizator.xml" într-un fişier HTML (încât să asigurăm o posibilitate de vizualizare a documentului).
Merită să precizăm: "centralizator.xml" are actualmente 94 Ko şi conţine peste jumătate dintre datele din DOC-ul de 5 MO iniţial - pentru că aria curriculară "Limbă şi comunicare" este cuprinsă complet (doar că nu este şi prelucrată complet), iar primele trei arii ocupă 33 de pagini dintre cele 76 ale documentului iniţial; deci putem estima că în final XML-ul nostru ar măsura 2*94 = cam 200 Ko (iar programul de formatare care trebuie asociat poate încăpea în doar vreo sută de rânduri).
Arborele XML
Deschizând centralizator.xml într-un browser am obţine:
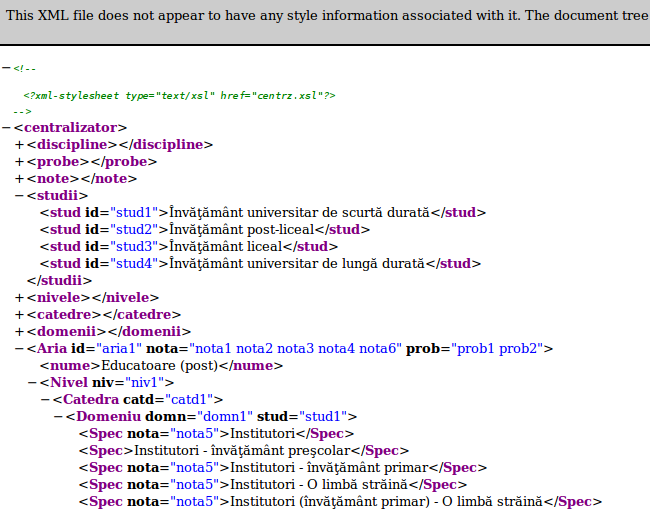
Semnele — şi + care apar la începutul fiecărui rând sunt asociate (prin click) cu operaţiile de colapsare (collapse) şi respectiv de expandare (expand) a itemurilor subordonate. Dacă este corect ("well formated", adică respectă regulile din DTD) şi dacă nu are asociat "any style information" (vezi primul rând din imaginea redată mai sus) - atunci documentul XML este redat sub forma unui arbore (tree), ale cărui noduri pot fi colapsate/expandate (prin click pe —/+).
Aici "rădăcina" arborelui este elementul 'centralizator', aşa cum s-a impus prin DTD-ul care a definit documentul; pentru a ajunge la nodurile "Spec" trebuie parcursă calea ("path") "centralizator/Aria/Nivel/Catedra/Domeniu". Specificaţia XPath asigură în mod unitar mecanismele de acces în arborele XML; de exemplu, presupunând că nodul curent este elementul "Aria" identificat prin "id=aria1", expresia "id(@prob)" va selecta din arbore (şi va returna) acele noduri care sunt referite prin atributul "prob" al elementului "Aria" curent - în speţă (vezi imaginea de mai sus), vor fi selectate nodurile care au "id=prob1" şi "id=prob2"; formula "Aria[@id='aria2']" va selecta din document întregul subarbore corespunzător nodului "Aria" identificat prin "id='aria2'".
Problema care se pune acum este aceea de a aplica documentului XML o transformare potrivită, încât el să capete la redarea lui din browser, o formă obişnuită (în loc de reda "The document tree", cum precizează primul rând din imaginea redată mai sus). Pentru a realiza asemenea transformări (în HTML, sau în text, sau chiar în PDF) şi pentru a stila diversele elemente, dispunem de limbajul XSLT. Observaţi primul element "comentariu", în imaginea noastră:
<!--<?xml-stylesheet type="text/xsl" href="centrz.xsl"?>-->
Dacă semnele de "comentariu" (<!-- şi la sfârşit, -->) ar fi lipsit (sau, ar fi şterse), atunci browserul ar fi interpretat "centralizator.xml" folosind fişierul "centrz.xsl" drept program de transformare prealabilă (întâi ar fi "executat" programul din "centrz.xsl" şi apoi ar fi redat rezultatul transformării).
Pentru a proba, puteţi proceda astfel: salvaţi "centralizator.xml" pe calculatorul propriu şi eliminaţi semnele de comentariu indicate; selectaţi programul "centrz.xsl" listat mai jos şi faceţi Copy&Paste în acelaşi director; apoi încărcaţi în browser fişierul local "centralizator.xml".
Un program de transformare (XSLT)
Redăm întâi programul realizat ("centrz.xsl", circa 100 de rânduri scurte) şi vom adăuga apoi, unele explicaţii privind programarea în limbajul XSLT.
<?xml version="1.0" encoding="utf-8"?> <xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform"> <xsl:output method="html"/> <xsl:template match="/Aria"> <html> <body> <xsl:apply-templates/> </body> </html> </xsl:template> <xsl:template match='Aria'> <script type="text/javascript">//<![CDATA[ function toggle(id) { var el = document.getElementById(id); el.style.display = el.style.display ? "" : "none"; }; //]]></script> <div style="margin:20px;padding:10px;border:2px solid blue;"> <h1 style="text-align:center; color:blue; cursor:pointer;" onclick="toggle('{generate-id()}')"> <span style="font-size:small;font-weight:normal;color:black;"> Aria curriculară: </span> <xsl:apply-templates select="nume"/> </h1> <div id="{generate-id()}"> <xsl:if test="@disp"><br/>Discipline: <xsl:for-each select="id(@disp)"> <b><xsl:value-of select="."/></b> <xsl:if test="not(position()=last())">, </xsl:if> </xsl:for-each> </xsl:if> <xsl:if test="@prob"> <b>Proba de concurs:</b> <ul id="{generate-id()}"> <xsl:for-each select="id(@prob)"> <li><xsl:value-of select="."/></li> </xsl:for-each> </ul> </xsl:if> <xsl:if test="@nota"> <ol style="font-size:small;"><b>Note:</b> <xsl:for-each select="id(@nota)"> <li><xsl:value-of select="."/></li> </xsl:for-each> </ol> </xsl:if> <xsl:apply-templates /> </div> </div> </xsl:template> <xsl:template match="Nivel"> <br/>Nivel: <xsl:for-each select="id(@niv)"> <b><xsl:value-of select="."/></b> <xsl:if test="not(position()=last())">, </xsl:if> </xsl:for-each> <xsl:apply-templates /> </xsl:template> <xsl:template match="Catedra"> <br/>Catedra: <xsl:for-each select="id(@catd)"> <b><xsl:value-of select="."/></b> <xsl:if test="not(position()=last())">, </xsl:if> </xsl:for-each> <xsl:apply-templates /> </xsl:template> <xsl:template match="Domeniu"> <br/>Domeniu: <xsl:for-each select="id(@domn)"> <b><xsl:value-of select="."/></b> <xsl:if test="not(position()=last())">, </xsl:if> </xsl:for-each> <xsl:call-template name="studii"/> <ol>Specializările admise: <xsl:apply-templates /> </ol> </xsl:template> <xsl:template match="Spec"> <li><b><xsl:value-of select="."/></b> <xsl:call-template name="studii"/> <xsl:if test="@nota"> <xsl:text> </xsl:text> <span style="font-size:small"> <xsl:for-each select="id(@nota)"> <xsl:value-of select="."/> <xsl:if test="not(position()=last())">; </xsl:if> </xsl:for-each> </span> </xsl:if> </li> </xsl:template> <xsl:template name="studii"> <xsl:text> </xsl:text> <span style="font-size:small"> <xsl:for-each select="id(@stud)"> <xsl:value-of select='.'/> <xsl:if test="not(position()=last())">; </xsl:if> </xsl:for-each> </span> </xsl:template> </xsl:stylesheet>
Procesorul XSLT încorporat în browser, vede datele XML sub forma unui arbore; elementele din documentul XML şi atributele acestora devin noduri în acest arbore; un program XSLT conţine funcţii care transformă acest arbore, putând să-l reorganizeze, să adauge/elimine noduri, etc.
În limbajele procedurale fluxul execuţiei instrucţiunilor programului este trasat în mod explicit de către program; XSLT este un limbaj funcţional: ordinea execuţiei instrucţiunilor nu mai este descrisă de către programul respectiv.
Un program XSLT reprezintă o asociere între nodurile arborelui XML şi nişte funcţii de transformare a nodurilor respective; procesorul XSLT "execută" acest program prin următorul mecanism: după ce s-a constituit arborele de intrare corespunzător documentului XML, se realizează o parcurgere în adâncime a acestui arbore (procesorul vizitează toţi fiii unui nod, recursiv, începând de la rădăcina arborelui, până la epuizarea nodurilor) şi asupra fiecărui nod vizitat se aplică funcţia de transformare menţionată în program pentru acea categorie de nod; fiecare funcţie de transformare arată procesorului cum să creeze eventual noi noduri în arborele de ieşire (corespunzător transformării documentului iniţial); la terminarea parcurgerii, procesorul a constituit un arbore de ieşire final pe care îl serializează şi îl returnează astfel drept răspuns final (în formă HTML, sau text, sau XML după cum s-a optat în program - vezi <xsl:output method="html"/>).
O funcţie în XSLT (termenul specific este template, "funcţie" desemnând mai degrabă "funcţiile predefinite"—în diversele specificaţii implicate, în principal XPath—precum position(), id() etc.) se construieşte - cel mai obişnuit - cu următoarea sintaxă generică:
<xsl:template match = "criteriu_selecţie_Listă_Noduri"> ("begin"-ul funcţiei)
apelează (recursiv) funcţii de transformare asupra "Listă_Noduri",
sau specifică direct transformări
</xsl:template> ("end"-ul funcţiei)
Funcţiile definite pentru transformarea elementului E vor fi apelate automat dacă subarborele curent parcurs conţine nodul E, dar de obicei pentru declanşarea acestui mecanism se apelează <xsl:apply-templates />. Exemplificăm cum decurg acţiunile, pentru secvenţa următoare:
(1) <xsl:template match = "/Aria">
(2) <html><body>
(3) <xsl:apply-templates/>
(4) </body></html>
(5) </xsl:template>
Prin (1) se construieşte în memorie lista tuturor subarborilor de rădăcină "Aria" (ca şi cum s-ar extrage lista respectivă din fişierul de date XML).
Cu (2) încep transformările asupra listei de subarbori obţinută la (1). Mai întâi, prin (2) se prefixează lista respectivă cu tagurile <html> şi <body> (anunţând un document HTML); desigur "prefixează" ar însemna aici: se construieşte nodul "html", apoi ca descendent al acestuia şi nodul "body", iar apoi lista subarborilor "Aria" devine descendent al nodului "body".
Dacă (3) ar lipsi din corpul funcţiei, atunci s-ar executa (4), adică s-ar adăuga la sfârşitul listei </body> şi </html> şi apoi prin (5) acţiunea funcţiei s-ar încheia şi s-ar returna HTML-ul rezultat (dacă experimentăm astfel, am vedea probabil că rezultatul ar fi asemănător cu vizualizarea unui fişier CSV, dar fără vreun separator).
Partea frumoasă este că nu este aşa, decât în cazul când în program nu există definiţii de transformare pentru nici unul dintre nodurile subordonate unui nod "Aria"! Dacă există însă o asemenea definiţie, de genul:
<xsl:template match = "Aria">
transformări pe nodurile subarborelui "Aria"
</xsl:template>
atunci ea este aplicată automat (fără a necesita neapărat prezenţa liniei (3)!) pe fiecare nod "Aria" al listei de noduri selectate la (1) şi mai mult: la fiecare aplicare a şablonului de transformare "Aria", s-ar aplica recursiv toate funcţiile de transformare existente pentru nodurile subordonate (în cazul nostru, pentru nodurile "Nivel", "Catedra", etc.).
Programul "centrz.xsl" redat mai sus conţine un număr minimal de "formatări", exprimate cu "style=...": se bordează fiecare zonă "Aria", se implică un element <h1> pentru elementele "Aria/nume" (prevăzut totuşi cu un "handler" de click, pentru a asigura utilizatorului operaţii de "collapse/expand"), se implică "bold" sau "small" pe unele elemente şi cam atât. Cam aşa se şi recomandă: până ce pui la punct programul limitează-te la un minimum de "formatare"; abia după ce programul "merge", gândeşte-te şi la o stilare mai elevată - iar cel mai bine este să realizezi un fişier separat de stiluri (cu "type='text/css'", fişier pe care să-l referi apoi din cadrul programului printr-o linie declarativă corespunzătoare).
Filosofia "Centralizatorului": completitudinea şi separarea specializărilor
"Centralizatorul" amănunţeşte extrem de tare "specializările" (şi chiar le numerotează), ajungând până la ridicol - iată un exemplu: la pagina 3, destinată postului de Învăţător, apar specializările 23. Învăţător - maistru şi apoi 24. Învăţătoare - maistră! Încă un exemplu? la pag. 10, Limba engleză/FILOLOGIE, avem "specializările": 295. Limbi moderne aplicate (engleză – franceză) şi apoi 296. Limbi moderne aplicate (engleză, franceză) (ambele au "studii universitare de lungă durată"; ordinea este aceeaşi, "engleză" apoi "franceză"). Dacă aceste specializări (de la Nr.Crt. 295 şi respectiv 296 indicate mai sus) sunt diferite (deşi diferă numai separatorul dintre "engleză" şi "franceză"), atunci este absolut clar că specializarea "Matematică" diferă şi ea, de specializarea "Matematică - Cercetări operaţionale" ş.a.m.d.
Pare firească acea coloană "Nr. crt.", prin care se indexează specializările dintr-o arie curriculară (se ştie… "Nr. crt." este cea mai dragă coloană a funcţionarilor); dar am observat acest aspect: specializările din aria "Limbă şi comunicare" sunt numerotate de la Nr.crt = 1 pâna la Nr.crt. = 1077 însă de fapt, lipsesc specializările care ar trebui să aibă Nr.crt. = 801 până la Nr.crt. = 810; s-or fi rezervat aceste numere de ordine pentru adăugiri ulterioare - dar la alte arii curriculare nu există asemenea rezervări, deci pentru aceste alte arii s-a asumat implicit că nu va fi cazul unor eventuale adăugiri.
Cu alte cuvinte: se consideră că documentul este complet (exceptând eventual, doar aria "Limbă şi comunicare") şi el corespunde realităţii sistemului de învăţământ; orice profesor titular sau care vrea titularizare, se regăseşte prin specializarea respectivă, undeva în acest Centralizator (ni se părea firesc să zicem: "aproape orice profesor", sau "cu eroare de 1%" - dar nu, documentul amănunţeşte în aşa hal specializările încât e clar: se vrea a fi "complet", n-are ce căuta eroarea sau lacuna - adică avem de-a face cu un sistem închis, care nu mai poate evolua!).
De fapt, în unele locuri documentul este mai degrabă ficţional şi lasă loc bunului-plac al unuia sau altuia. Cât este el de "complet" se poate vedea din exemplul următor (şi sunt sigur că există şi altele). La Facultatea de Matematică pe care am urmat-o eu, studenţii s-au separat în al treilea an parcă, în trei secţii: secţia de Matematică, secţia de Informatică şi secţia de Cercetări operaţionale. Fiindcă pe Centralizator - la aria curriculară Matematică şi ştiinţe ale naturii şi de asemenea la aria Tehnologii - găsim aşa ceva: Matematică - informatică (unde se regăsesc şi colegii mei care au terminat secţia "Informatică"), deducem că ar trebui să găsim şi Matematică - Cercetări operaţionale pe undeva (să mă regăsesc adică şi eu; aş zice că şi alţii dintre colegii mei de la "Cercetări operaţionale", numai că majoritatea acestora nu lucrează în învăţământ… lucrează din start în domenii informatice). Dar specializarea "Cercetări operaţionale" nu apare la niciuna dintre ariile curriculare. Rămâne să ţinem seama de nota de subsol de la cele două arii curriculare menţionate, care zice generos:
Notă. La specializările nominalizate mai sus se adaugă : (1) Toate specializările similare absolvite înainte de 1993 ; (2) Programele de conversie profesională de nivel universitar sau postuniversitar...
(apropo: caracterele ';', ':' şi altele, trebuie puse fără spaţiu înainte!)
"Programe de conversie" nu am urmat, aşa că rămâne să invocăm nota Toate specializările similare absolvite înainte de 1993. Numai că aici depindem în mod evident, de bunul plac al celui care ar "judeca" cererea… (fie un funcţionar al Ministerului, fie un funcţionar al Inspectoratului, fie "conducerea şcolii"; şi dacă e "conducerea şcolii", atunci ea "va consulta" Inspectoratul, care mai departe evident…)
Ar fi de închipuit cam aşa: Matematică - Cercetări operaţionale o fi o "specializare similară" cu Matematica, cu Matematică - Informatică, sau cu ce? (trebuie să fi existat aşa ceva, că scrie aşa pe Diplomă...) "Matematică - Cercetări operaţionale" - păi evident, trebuie să-l încadrăm la Matematică fiindcă "începe cu Matematică"...
Ia să vedem "Foaia Matricolă"; bine, atrag şi atenţia, într-o doară: "Logică şi calculatoare", "Limbaje de programare", "Practică productivă", "Limbaj COBOL şi tratarea fişierelor", "Teoria grafurilor şi aplicaţii", "Algoritmi de optimizare", "Teoria modelelor", "Teoria automatelor" (de disciplinele "matematice" uit că na—e în joc dreptul de a preda "informatică") - numai că "a atrage atenţia" are sens numai în contextul existenţei unor anumite competenţe (care nu-s obligatorii pentru funcţionar, care funcţionar este şi departe şi este şi foarte ocupat cu probleme evident mai importante). Depinde numai de bunul plac al unuia sau altuia ca să accepte că discipline de genul celor enumerate nu-s propriu-zis de matematică, ci chiar ţin şi de informatică (şi eu spun hotărât că separaţia formală întreprinsă cu atâta sârg la noi: matematica e una, informatica e alta, a fost dusă dincolo de orice bun-simţ şi de altfel, începe să fie contrazisă în mod explicit chiar şi de manuale de liceu).
Mdaa, Foaia Matricolă e totul… nu vede el funcţionarul nostru că ea este tocmai din 1976, iar Microsoft a apărut prin 1975-76… Dar eu ştiu că totuşi Diploma aia, asimilată cum se cuvine - mi-a permis să progresez. Îşi aminteşte careva ceva semnificativ de prin discursurile de deschidere a anului universitar?! eu am fost norocos: s-a putut să am ce reţine şi mi-a rămas în minte această formulare a lui Adolf Haimovici: "cine va termina onorabil Matematica, va fi în stare să facă orice altceva!". Indiscutabil, aşa este; dar nu ştiu dacă ar mai fi valabil şi azi - de când cu "baremele", "culegerile de ezerciţii" şi de când cu "descongestionarea învăţământului", care toate împreună şi la repezeală conduc sigur la limitare şi mărginire.
Dar de ce n-ai urmat mata vreun curs de "conversie profesională", că acu' ai fi avut un atestat la mână! Da' chiar - Auzi mata! campion olimpic cică, dar n-are nici măcar Facultatea de Educaţie fizică şi sport, darmite nu ştiu care specializare (a consulta Centralizatorul!).
Iată că nu m-am preocupat de atestări, deşi am prins perioada când parcă puteam face şi gratis a doua facultate; n-am avut timp, că am tot învăţat (ştiţi cum era - pe la Facultăţi se făcea din greu "limbajul Pascal" şi "programare structurată", ori eu prăpădeam vremea cu ASM, cu funcţii DOS şi cu C, ba chiar şi cu Pascal; aaa… dar asta nu ştiţi: am cam fost muştruluit ocazional de către Inspector - "Programa Şcolară" prevede "limbajul Basic" - cum faci alde matale "Pascal", nu-i permis; mai târziu, programa prevede "Pascal" păi cum îţi permiţi mata să faci "limbajul C"?!).
"Centralizatorul" se dovedeşte a fi rupt de realitate şi aceasta tocmai datorită separării extreme (în fond, artificiale) a specializărilor; eu am predat în realitatea vizibilă de zi cu zi, 30 de ani Matematică şi 15 ani Informatică şi se pare că nu m-am făcut de râs nici cu una nici cu alta - ori Centralizatorul afirmă că eu nu exist; păi asta cam ţine de "fals în acte publice"! O asemenea categorie juridică nu există? - bun, e cazul de a o înfiinţa: un funcţionar instituie în numele statului nişte reglementări care voit sau nu - afectează negativ şi în mod incorect diverse persoane, punându-le în situaţia de a tot umbla pentru a obţine recunoaşterea drepturilor; păi atunci acel funcţionar se face vinovat de fals din culpă în acte publice şi ar trebui tratat în consecinţă.
Pentru funcţionar public (cu tot cu "consilieri") trebuie impuse şi alte competenţe (de nivel onorabil), decât componenta care ţine de legislaţie şi de regulamente (sau de adaptabilitatea politică).
Notă (2011)
Centralizatorul de la edu.ro arată azi mai bine decât descriam mai sus în 2007 (altfel… tot cu Word şi cu "sistemul computerizat") şi este mai "complet": a apărut şi "Cercetări Operaţionale" pe unde trebuia - în mod tacit (deja nu mai aşteptam nimic; deja erau aproape doi ani de tratament "profesor necalificat"…); iar acum măsoară aproape 25 MO (faţă de 15 MO în 2007).
vezi Cărţile mele (de programare)