Constituirea unei baze de date, colectând cu Python de pe Web
În şcoli - pregătind pomposul "atestat" - se lucrează probleme cu "baze de date" ca ELEV.dbf, care întâi se cere să fie "populat" cu minimum 10 înregistrări…
Ca să avem despre ce vorbi, o bază de date ar trebui constituită din măcar două tabele relaţionate şi ar fi de dorit să cuprindă un număr consistent de înregistrări. Dăm un exemplu de creare a unei baze de date proprii, prin specularea unor pagini Web care prezintă datele care ne-ar interesa (ideea generală web scraping - colectare automată a informaţiei de pe Web).
Astfel, posta-romana.ro prezintă pentru fiecare judeţ informaţii privitoare la oficiile poştale; baza de date din care sunt extrase informaţiile respective nu ne este accesibilă, dar putem investiga pagina HTML corespunzătoare în scopul de a extrage numele localităţilor.
Google "România judeţe localităţi" ne dă milioane de rezultate… Dar investigând primele vreo două pagini - constatăm că numai ro.wikipedia.org foloseşte diacriticele cuvenite pentru redarea numelor de judeţe şi localităţi (posta-romana.ro ar face excepţie, dar acolo e vorba de "oficii poştale" şi nu de localităţi).
Ne-am propus să scriem un program prin care să se acceseze rând pe rând paginile de pe //ro.wikipedia.org corespunzătoare judeţelor, extrăgând de pe fiecare pagină numele localităţilor şi constituind cu acestea un fişier text. Fişierele rezultate vor servi apoi ca sursă de date pentru tabelele bazei noastre de date.
Iniţial, am folosit wget (dar în cel mai simplu mod), pastând în linia de comandă URL-ul copiat din bara de adresă a browserului:
vb@vb:~$ \
wget http://ro.wikipedia.org/wiki/List%C4%83_de_localit%C4%83%C8%9Bi_din_jude%C8%9Bul_Vaslui
Deschizând într-un editor de text fişierul obţinut, am căutat "Listă de localități din județul Vaslui" şi am identificat lista respectivă într-un element <table>, conţinând pentru fiecare localitate:
<tr bgcolor="#FFFFFF"> <td><a href="/wiki/Ar%C8%99i%C8%9Ba,_Vaslui" title="Arșița, Vaslui">Arșița</a></td> <td align="center"></td> <td width="1px"></td> </tr>
Căutând un aspect de înregistrare invariabil de la localitate la localitate (şi de la un judeţ la altul) - am observat întâi forma atributului "href" şi a atributului "title" din aceste link-uri: ele (şi numai aceste link-uri, dintre cele existente) se încheie cu "_Vaslui" şi respectiv cu ", Vaslui" (sau "Galaţi", pentru un alt judeţ) şi am folosit atunci expresii regulate corespunzătoare pentru a extrage localităţile respective de pe pagină (lucrând în Python).
Acest prim experiment a reuşit pentru "Vaslui", "Alba", etc. - dar s-a dovedit dificil de pus la punct în cazul denumirilor care conţin diacritice ("Galaţi", de exemplu): explicaţia derivă din faptul că pe sistemul propriu folosesc "Romanian cedilla" (ş ţ), iar pe //ro.wikipedia.org se foloseşte (inclusiv în URL-uri) "Romanian comma" (ș ț) pentru alfabetul românesc.
N-am vrut să schimb codificarea locală şi m-am necăjit cu funcţii de conversie (până ce am dat de chestiunile delicate ale lucrului cu Unicode în Python)… În cele din urmă am observat totuşi un aspect invariabil care nu depinde de numele de judeţ şi care este foarte simplu: link-urile localităţilor sunt singurele (cu o singură excepţie, chiar la începutul tabelului) care au drept "parent" un element <td> (celelalte link-uri din pagină au ca "parent" elemente <th> sau <p>).
Pentru extragerea numelor din link-urile menţionate mai sus, folosim modulul BeautifulSoup: soup = BeautifulSoup(HTML) asociază documentului HTML un arbore de obiecte Python - analog DOM-ului creat de browser; apoi, soup.findAll(lambda tag: tag.name == 'a' and tag.parent.name == 'td')[1:] va returna lista tuturor elementelor <a> (cu excepţia celui de rang 0) care au ca "parent" un element <td>.
Pentru accesarea (şi download-area) paginii de localităţi corespunzătoare fiecărui judeţ alegem modulul Python urllib2:
vb@vb:~$ python Python 2.7.2+ >>> import urllib2 >>> request = urllib2.Request( r"http://ro.wikipedia.org/wiki/Listă_de_localităţi_din_judeţul_Vaslui") >>> response = urllib2.urlopen(request)
dar aşa - nu ni se permite accesul: "urllib2.HTTPError: HTTP Error 403: Forbidden". Unele website-uri (Wikipedia, Google) care permit utilizatorilor să editeze pagini, încearcă să blocheze accesarea prin programe (în loc de accesare prin intermediul unui browser propriu-zis); editarea poate fi acceptată din partea unui utilizator uman, dar nu din partea unui program…
HTTP prevede header-ul User-Agent pentru identificarea originii cererii (browser sau program); adăugând în apelul urllib2.Request() argumentul headers={'User-Agent': "o denumire oarecare"} simulăm accesarea printr-un browser şi obţinem accesul dorit.
Trecând prin cele redate mai sus, am constituit în final următorul program:
#!/usr/bin/python # -*- coding: utf-8 -*- import urllib2 from BeautifulSoup import BeautifulSoup import codecs url1 = r"http://ro.wikipedia.org/wiki/Listă_de_localităţi_din_judeţul_" def lista_loc(jud): url = url1 + jud request = urllib2.Request(url, headers = {'User-Agent': "Magic Browser"}) response = urllib2.urlopen(request) # html = BeautifulSoup(response).prettify(); print html soup = BeautifulSoup(response).findAll( lambda tag: tag.name == 'a' and tag.parent.name == 'td' )[1:] list_loc = [a.string.strip() for a in soup] f = codecs.open(jud + ".txt", "w", "utf-8") f.write("\n".join(list_loc)) f.close() judete = [r'Alba', r'Arad', r'Argeş', r'Bacău', r'Bihor', r'Bistriţa-Năsăud', r'Botoşani', r'Braşov', r'Brăila', r'Buzău', r'Caraş-Severin', r'Călăraşi', r'Cluj', r'Constanţa',r'Covasna', r'Dâmboviţa', r'Dolj', r'Galaţi', r'Giurgiu', r'Gorj', r'Harghita', r'Hunedoara', r'Ialomiţa', r'Iaşi', r'Ilfov', r'Maramureş', r'Mureş', r'Mehedinţi', r'Neamţ', r'Olt', r'Prahova', r'Satu_Mare', r'Sălaj', r'Sibiu', r'Suceava', r'Teleorman', r'Timiş', r'Tulcea', r'Vaslui', r'Vâlcea', r'Vrancea'] for jud in judete: lista_loc(jud)
Executând programul, rezultă în directorul curent 41 de fişiere ("Alba.txt", "Iaşi.txt", etc.), conţinând localităţile înregistrate pe Wikipedia.
Creăm o bază de date wikiloc (în MySQL) şi acest fişier "wikiloc.sql":
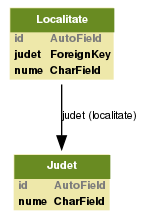
CREATE TABLE judet ( id int NOT NULL AUTO_INCREMENT PRIMARY KEY, nume VARCHAR(24) ) ENGINE = INNODB DEFAULT CHARSET=utf8 COLLATE=utf8_romanian_ci; CREATE TABLE localitate ( id int NOT NULL AUTO_INCREMENT PRIMARY KEY, judet_id int, nume VARCHAR(64), FOREIGN KEY (judet_id) REFERENCES judet(id) ON DELETE CASCADE ) ENGINE = INNODB DEFAULT CHARSET=utf8 COLLATE=utf8_romanian_ci;
Apoi, constituim tabelele prin:
vb@vb:~$ mysql wikiloc < wikiloc.sql
Anterior, pentru a obţine lista judeţelor (în variabila 'judete' din programul de mai sus) am selectat şi am copiat lista de judeţe afişată pe Wikipedia, constituind un fişier text cu câte un nume pe linie. Folosim acum acest fişier pentru a înregistra judeţele în tabelul "judet", folosind shell-ul mysql:
mysql> load data local infile '~/judet.txt' into table judet (nume);
În final, următorul program Python deschide baza de date "wikiloc" şi selectează înregistrările din tabelul "judet"; apoi, pentru fiecare judet citeşte fişierul cu acelaşi nume ca judeţul şi inserează numele citite în tabelul "localitate" (setând şi valoarea "judet_id" corespunzătoare):
import codecs import MySQLdb as mdb connection = mdb.connect('localhost', 'vb', '1234', 'wikiloc'); cursor = connection.cursor() cursor.execute("SELECT * FROM judet") judete = cursor.fetchall() for jud in judete: nume = jud[1] # jud[0] este "id", jud[1] este "nume" f = codecs.open(nume + ".txt", "r", "utf-8") localitati = f.read() f.close() locs = localitati.split('\n') for loc in locs: cursor.execute( "INSERT INTO localitate SET judet_id = '%i', nume = '%s'" % (jud[0], loc.encode('utf-8'))) connection.commit() cursor.close() connection.close()
După execuţia acestui program, putem verifica din mysql ce am obţinut - de exemplu:
mysql> select judet.nume as "Judeţ", count(*) as "Loc." from localitate, judet -> where judet.id = localitate.judet_id -> group by judet.id;
+--------------------+------+ | Judeţ | Loc. | +--------------------+------+ | Alba | 717 | | Arad | 283 | | Argeş | 586 | ......................... | Vâlcea | 608 | | Vrancea | 346 | +--------------------+------+ 41 rows in set (0.02 sec)
rezultând un total de 13760 localităţi înregistrate.
Pentru o exemplificare imediată de utilizare, am integrat baza de date creată astfel într-o mică aplicaţie django, accesibilă prin link-ul Localităţi din containerul de aplicaţii de pe coloana din dreapta paginii (abandonată, în 2018). În termeni generali, funcţionarea acestei aplicaţii se poate descrie astfel: la selectarea de către utilizator a unui judeţ, se lansează o funcţie jQuery care transmite unei anumite funcţii ("view", în termenii django) de pe server "id"-ul corespunzător judeţului; view-ul respectiv obţine de la MySQL localităţile aferente acelui judeţ, ambalează numele în taguri <li> şi returnează lista; funcţia jQuery care postase id-ul încheie prin înscrierea răspunsului în pagină.
vezi Cărţile mele (de programare)