Cu Perl, de la ORAR.XLS (orarul şcolii) la Web
De un număr de ani avem pe acest site o aplicaţie prin care un orar şcolar poate fi vizualizat pe clase, pe profesori, pe obiecte. Însă datele necesare trebuie introduse "pe bucăţi": câte schimburi există, care sunt clasele pe fiecare schimb şi ce coduri alegeţi pentru fiecare clasă, care sunt obiectele, care sunt profesorii, ce încadrare are fiecare şi abia în final - orarul propriu-zis.
Desigur că în cazul când orarul este deja constituit, cerinţa de a introduce şi datele prealabile (cele pe care s-a bazat elaborarea orarului) seamănă a sîcâială… Convenabil pentru utilizator ar fi să aibă de făcut un singur pas - să furnizeze orarul final - urmând ca aplicaţia ta să-l "webalizeze" corespunzător. Am încropit aici a webaliza (a integra sau a transforma o sursă brută de date într-o aplicaţie Web), dar poate să ţină.
Date de încadrare versus orar
Vizarea separată (date de încadrare versus orarul propriu-zis) a avut următoarea raţiune: cu datele de încadrare (orarul poate lipsi!) se poate contacta o altă aplicaţie care… concepe şi furnizează unul sau mai multe orare, corespunzător încadrării primite. Dar această prelungire (partea care şi realizează orarul) nu este montată pe site: timpul de execuţie ar fi prea mare, în raport cu cerinţele rezonabile de "aplicaţie on-line". Dar chiar şi în absenţa acestei prelungiri, datele de încadrare sunt necesare; de exemplu ele servesc pentru verificarea corectitudinii orarului, în urma unor modificări.
Datele necesare aplicaţiei sunt păstrate într-o anumită bază de date, constituită desigur din mai multe tabele relaţionate între ele. Există un tabel al şcolilor care şi-au înscris orarul; şcolii îi corespunde o intrare unică într-un tabel de conturi, astfel încât utilizatorul autentificat prin acel cont (nume şi parolă) va avea drept de editare asupra orarului acelei şcoli.
Tabelul şcolilor este în relaţie "1-n" cu un tabel al claselor, în care pentru fiecare şcoală se păstrează date despre clase: în ce schimb funcţionează clasa, de care nivel aparţine (clasele a IX-a, a X-a, etc.), ce cod s-a ales pentru ea (am introdus de mult coduri de câte o singură literă… constatând însă că lumea reală acceptă foarte greu simplificări precum 'a' în loc de "5A" şi 'A' în loc de "6A").
La fel, avem relaţii "1-n" cu un tabel al obiectelor şi cu unul al profesorilor. O intrare în tabelul profesorilor conţine (pe lângă câmpul de identificare a şcolii) numele, prenumele şi "încadrarea" profesorului respectiv (pe fiecare schimb). Încadrarea este formulată pe baza codurilor claselor, de exemplu: A3B3e4 (are 3 ore la clasa de cod 'A', 3 ore la 'B' şi 4 ore la clasa de cod 'e'); aici (şi apoi, în alte locuri din aplicaţie) se vede avantajul folosirii unor coduri de câte o singură literă.
În sfârşit, fiecărui profesor îi corespunde o intrare bine determinată într-un tabel care conţine chiar orarul acelui profesor, sub forma unor şiruri de caractere precum ..AeB.. - adică în ziua cutare, are 3 ore: a III-a la clasa 'A', a IV-a la clasa 'e' şi a V-a la clasa 'B'.
Tabloul încadrărilor poate fi transmis unui program al cărui scop este realizarea în serie a câtorva repartizări posibile distincte pe zilele săptămânii, a circa 90 - 95% dintre orele existente; utilizatorul trebuie să aleagă una dintre schemele de repartizare incompletă furnizate şi să o completeze/modifice convenabil. Odată definitivată repartizarea tuturor orelor pe zilele săptămânii, ea poate fi transferată unui program care realizează orarul propriu-zis pe fiecare zi; interesul acestui program (realizat direct în limbaj de asamblare) ar fi acela că în condiţii rezonabile (caz în care şi timpul de execuţie este scurt) produce un orar cu ZERO ferestre (… chiar dorim să prezentăm programul, desigur cu un alt prilej).
De la Microsoft Office Excel la baza de date specifică aplicaţiei
Să presupunem că am primit un fişier .XLS conţinând orarul unei şcoli. Ce înseamnă aceasta se poate deduce de pe următoarea imagine, extrasă de pe ecran după deschiderea fişierului respectiv cu Gnumeric (analogul open-source al aplicaţiei Microsoft Office Excel cu care a fost produs fişierul iniţial); desigur, aici am preferat să înlocuim numele reale ale profesorilor cu denumiri generice.

Problema noastră constă în extragerea şi organizarea datelor din acest fişier, în aşa fel încât să le putem înscrie corespunzător în tabelele bazei de date descrise mai sus.
Notăm că este vorba de schimbul I, pe care sunt trei nivele de clase: 11 (codificate începând cu A), 12 (codificate de la a) şi 10 (codificate x, y şi S); pentru clasele 11 şi 12 va trebui dedus câte clase sunt (de la 'A' şi respectiv 'a', până la care literă). Reţinem că Luni, Joi şi Vineri sunt zile cu câte 6 ore, iar Marţi şi Miercuri au câte 7 ore (noi vom pune unitar 7 ore pe fiecare zi, chiar dacă a 7-a va fi foarte rar întrebuinţată).
Putem şterge de-acum rândurile 1—6, precum şi vreo trei coloane vide iniţiale (păstrând coloanele pentru nume, obiect şi ore). Apoi, salvăm în format CSV, Comma-separated values:
Prof1,biologie,,,,,,,,,,,,,,,,,,,,,,,,B,Y,b,,,,,,Y
Prof2,fizică,,,,,,,,,,,,a,,,,,,,,,,,,,,a,,,,a,,
Prof3,română,,,,,a,f,,,,,,,,,,,a,C,f,,,,,,,,,,f,C,C,a
Prof4,română,,E,b,Y,d,,,,Y,E,,,,,,b,d,,,,,,E,Y,b,,,,,d,,
Prof5,română,,,,D,G,X,,,,e,D,c,,c,x,D,,G,e,,,,G,c,x,e,,,,,,
Prof6,română,A,F,,,,,,,,,,,,A,F,,,,,,A,F,,,,,,,,,,
(am redat aici numai textul CSV corespunzător datelor redate în imaginea anterioară)
Pentru a demara prelucrările pe care le avem de făcut este suficient fişierul-text pe care l-am obţinut. Dar dacă dorim, putem obţine uşor o formă lizibilă a acestui fişier: încărcăm fişierul .CSV în Emacs, activăm pentru bufferul respectiv modul CSV şi folosim opţiunea auto-definitorie Align Fields into Columns:

Urmează acum să formulăm un program care analizează conţinutul fiecărei linii, producând în principal încadrările specifice bazei noastre de date; de exemplu, pentru Prof5 va trebui furnizată încadrarea de 15 ore D3G3x3e3c3. Să observăm la timp că se foloseşte ba 'X', ba 'x' - deşi la început s-a menţionat doar 'x' (şi anume, drept cod pentru clasa 10A); folosind facilităţile editorului de text, înlocuim peste tot 'x' cu X şi 'y' cu Y (acestea vor fi codurile claselor 10A, 10B, în baza noastră de date).
Limbajul în care formulăm acest program nu poate fi chiar oricare; trebuie să ţinem seama de faptul că în aplicaţia noastră baza de date descrisă mai sus (creată cu MySQL) este gestionată folosind în principal limbajul Perl. Dar şi este foarte avantajos să folosim Perl: pe CPAN găsim module destinate cam oricărui tip de prelucrare imaginabil. Putem folosi Class::DBI pentru operaţiile specifice bazelor de date (indiferent că se foloseşte MySQL, sau Oracle, etc.); putem folosi Text::CSV::Simple pentru prelucrări specifice fişierelor CSV.
Cu Perl, de la CSV la tablouri asociative
Următorul program Perl angajează un obiect $parser, produs de Text::CSV::Simple,
my $parser = Text::CSV::Simple->new();
obiect care prin metodele proprii - sintetizate în read_file($datafile); - transformă fiecare linie din fişierul CSV într-un tablou având drept componente câmpurile respective (acestea sunt separate în CSV prin ','); în final, rezultă un tablou al acestor tablouri.

Text::CSV::Simple mizează pe codul ASCII standard, dar uzează "în spate" de Text::CSV_XS - iar acesta asigură flagul opţional binary inclusiv în scopul marcării caracterelor codificate UTF8, permiţând astfel recunoaşterea şi a caracterelor româneşti (existente în CSV-ul originar).
Folosind Data::Dumper (după use Data::Dumper;) putem face o verificare prin
print Data::Dumper->Dumper(\@data);
Anume, constatăm că @data este un "array of arrays", conţinând tablouri de forma:
[ 'Prof5','română','','','','D','G','X','','','','e','D','c','','c','X','D',
'','G','e','','','','G','c','X','e','','','','','','' ],
adică, redând mai clar datele (splitând pe zile, dar… manual, deocamdată):
[ 'Prof5', 'română', # nume = $data[4][0], obiect = $data[4][1] '','','','D','G','X', # ziua 1, 6 ore: $data[4][2] .. $data[4][7] '','','','e','D','c','', # Marţi (7 ore: $data[4][8] .. $data[4][14]) 'c','X','D','','G','e','', # Miercuri (7 ore) '','','G','c','X','e', # Joi (6 ore) '','','','','','' # Vineri (6 ore) ],
Dar tabloul obţinut @data este cel puţin incomod de folosit pentru ceea ce avem aici de făcut: ar trebuie să folosim indici 2..7, 8..14, etc. pentru a accesa orele fiecărei zile; în plus, în unele zile sunt 7 ore, în altele 6. Continuăm programul început mai sus, pentru a transforma @data într-o structură de date mai convenabilă:
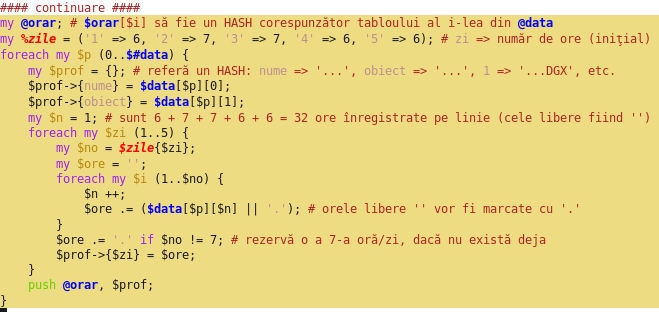
Noul tablou @orar este un "array of hashes" (de fapt, referinţe la hash-uri). Cu
print Data::Dumper->Dumper(\@orar);
putem vedea ce înseamnă aceasta:
$VAR1 = [
{
'4' => '..GcXe.',
'1' => '...DGX.',
'3' => 'cXD.Ge.',
'obiect' => 'română',
'nume' => 'Prof5',
'2' => '...eDc.',
'5' => '.......'
},
{ ... }, # etc. (celelalte HASH-uri)
]
Acum nu mai este necesar să indexăm 2..7, 8..14, etc. - putem folosi de exemplu:

afişând orarul pe linii succesive de forma:
4. Prof5 română ...DGX. ...eDc. cXD.Ge. ..GcXe. .......
Este drept că în secvenţa tocmai redată încă este implicată indexarea clasică, accesând componentele tabloului @orar prin $orar[$pr], unde $pr este indexul componentei. Dar în Perl "orice este un obiect" (cu metode şi posibilităţi de acces proprii)- încât putem simplifica elegant secvenţa de mai sus astfel:

Aici $pr este chiar componenta curentă a tabloului, anume o referinţă la HASH-ul care conţine datele asociate unui profesor (ale căror valori pot fi accesate prin $pr->{proprietate}).
Reconstituirea încadrărilor
Următoarea etapă de lucru ar consta în modelarea obţinerii încadrărilor (de înscris în final într-un anumit tabel al bazei noastre de date); de exemplu, pentru Prof5 trebuie reconstituită încadrarea D3G3X3e3c3.
Concatenând şirurile $pr->{$zi} care reprezintă orarul pe câte o zi, obţinem de exemplu pentru Prof5:
my $ore = "...DGX....eDc.cXD.Ge...GcXe........";
şi rămâne să determinăm frecvenţa fiecărei litere în şirul $ore.
Metoda obişnuită (în Perl) pentru aceasta, constă în a considera un HASH my %fr = (); prin care literei îi va fi asociată frecvenţa; pentru a determina valorile $fr{litera} se foloseşte operatorul de substituţie s/// şi mecanismele de lucru cu expresii regulate.
$sir =~ s/Şablonul-expresiei-de-înlocuit/Expresia-înlocuitoare/eg este sintaxa generală a unei operaţii de substituire: în şirul iniţial $sir se caută toate (datorită adăugării în final a modificatorului g, pentru "global") apariţiile unei secvenţe de caractere care corespunde şablonului precizat şi fiecare dintre aceste secvenţe este înlocuită cu expresia-înlocuitoare precizată. De exemplu, dacă my $data = "8-10-2009"; atunci după $data =~ s/-/\./g; şirul $data va conţine "8.10.2009" (s-a înlocuit '-' cu '.').
Pentru a obţine frecvenţa de apariţie a unei secvenţe de caractere într-un şir folosim "parantezele de grupare" şi variabilele implicite $1, $2, etc. care referă respectiv apariţiile (prima, a doua, etc.) secvenţei dintre paranteze (plecând de la un hash %fr, cum am precizat mai sus). De exemplu,
my %fr = (), $cuv = 'aba..ba.';
$cuv =~ s/(.)/$fr{$1}++;$1/eg;
print $cuv . "\n" . ' a' . $fr{a} . ' b' . $fr{b} . '.' . $fr{' .'}; # a3 b2 .3
$cuv este investigat de la stânga spre dreapta, caracter după caracter. Şablonul (.) grupează câte un singur caracter (oarecare), iar grupul respectiv este referit de $1; la prima apariţie a caracterului 'a' (pe prima poziţie din $cuv) se creează o intrare $fr{'a'} = 1 şi se înlocuieşte (conform definiţiei pentru s///) acea apariţie cu secvenţa referită de $1, deci tot cu 'a'; la a doua apariţie, $fr{'a'} este incrementat; ş.a.m.d.
Pentru fiecare profesor, concatenăm cele 5 şiruri care reprezintă orarul pe câte o zi (rezultând şirul $or). Instituim un HASH %clp care să asocieze fiecărui cod de clasă existent în $or, numărul de apariţii în şirul $or:

Rezultă cum ne-am dorit, secvenţe de genul Prof5 română D3G3X3e3c3. Şablonul de grupare folosit ([^\.]) corespunde unei secvenţe de un singur caracter, diferit însă de '.'.
Dacă vrem să obţinem numărul total de ore pe săptămână, aşezate în orar pentru fiecare clasă - putem refolosi secvenţa de mai sus, externalizând însă declaraţia my %clp = (); (mai sus aceasta figura în interiorul ciclului, astfel că HASH-ul respectiv era reiniţializat la fiecare nouă iteraţie).

Acum incrementarea valorilor $clp{$1} pe parcursul unei iteraţii se face plecând de la valoarea lăsată de precedenta iteraţie, încât obţinem numărul total de ore ale claselor:
S29 F30 a32 d29 E30 Y35 C30 f29 e29 A29 X35 B29 c29 D30 b32 G30
ceea ce este util mai ales pentru procedurile de verificare a orarului.
Între editare şi automatizare
Am secvenţiat mai sus cam toate prelucrările necesare pentru extragerea şi organizarea convenabilă a datelor din fişierul .XLS iniţial, în vederea încorporării lor în aplicaţia "Orarul şcolii". Intenţia tacită iniţială era de a strânge aceste secvenţe într-un modul Perl unitar, adăugând o funcţie care să şi înscrie în baza de date a aplicaţiei datele rezultate astfel din fişierul .XLS. Cu alte cuvinte, voiam să eliminăm complet necesitatea vreunei intervenţii manuale, între momentul uploadării fişierului XLS (de către un utilizat autorizat) şi momentele imediat următoare ale unor posibile cereri referitoare la orarul tocmai înregistrat în baza de date a aplicaţiei.
Însă ideea unei proceduri absolut automate se loveşte mereu de realităţile "minore". De exemplu, în fişierul .XLS furnizat iniţial se folosesc coduri diferite pentru o aceeaşi clasă (x şi X, cum am evocat mai sus), sau denumiri diferite pentru acelaşi obiect; ori faptul că e unul şi acelaşi obiect (clasă, disciplină, sau profesor), dar denumit diferit - îl ştim sau îl putem afla noi, dar aplicaţia cum să-l decidă indubitabil, pe ce bază? De obicei, gama confuziilor posibile este prea mare, pentru a lua în seamă ideea unei proceduri automate de decizie.
Mai mult, fişierul .XLS iniţial conţine diverse elemente suplimentare inutile, ţinând desigur de "arta formatării tabelului": coloane vide, o coloană funcţionărească de tip "Nr.crt.", rânduri vide (pentru… separarea paginilor la imprimare!), antet repetat (ca să apară pe fiecare pagină, la tipărire); unele zile au 7 coloane, altele numai 6.
Nuanţa incriminată se datorează unui fapt obişnuit: Excel este folosit ca editor, nu ca platformă de programare. S-au tastat denumiri, nume, coduri oriunde "trebuie" să apară ele în tabel - nu s-au folosit referinţe la anumite seturi de date prestabilite; ca urmare, în unele locuri s-a tastat de exemplu "ist/geog" (indicând obiectele profesorului), iar în altă parte (pe schimbul celălalt) "ist/geogr." pentru aceleaşi obiecte.
De altfel - în practica şcolară din ultimii ani, informatica (şi "informatizarea") a ajuns să fie redusă la editare (folosind nici măcar vreun editor de text onorabil, ci Microsoft Word, Borland IDE, Visual FoxPro, Excel - totul la nivel de meniuri şi "point-and-click"), practicând un soi de informatică funcţionărească.
Desigur, Excel-ul permite evitarea redundanţei şi "normalizarea" datelor complexe de înscris în tabele: în cazul de faţă, am defini un "Sheet" pentru clase, unul pentru obiecte, unul pentru profesori şi un sheet pentru orar; în coloanele orarului am înscrie nu numele profesorilor, ci referinţe la profesorii din sheet-ul profesorilor; am înscrie nu codurile claselor, ci referinţe la sheet-ul claselor şi nu obiectele, ci referinţe corespunzătoare la sheet-ul obiectelor. Gândind astfel, scăpăm de editarea mecanică (şi începe să aducă a informatizare).
Procedura finală
N-am vrut să modificăm codul existent al aplicaţiei noastre (deşi… chiar ar fi cazul de a o rescrie: oleacă altfel vedem lucrurile, după trei ani) şi având în vedere observaţiile de mai sus, ne-am decis asupra acestui procedeu: salvăm în format CSV cele două sheeturi din fişierul .XLS iniţial (unul reprezintă orarul pentru schimbul I, celălalt - pentru schimbul al II-lea) - desigur, după ce vom fi eliminat din fiecare, coloanele şi rândurile vide sau inutile, precum şi cele patru "antete de pagină". Programul următor (bazat pe secvenţele Perl descrise mai sus) analizează pe rând cele două fişiere CSV şi produce un fişier text în acelaşi format în care aplicaţia existentă "Orarul şcolii" cere introducerea datelor prin elemente <textarea>.
#! /usr/bin/perl -w use Text::CSV::Simple; use List::MoreUtils qw(uniq); # reduce valorile repetate din tablou my $parser = Text::CSV::Simple->new({ binary => 1 }); # 'binary' implică şi UTF8 my $file1 = 'orar1-12.10.csv'; # orarul schimbului 1 (fişier CSV) my $file2 = 'orar2-12.10.csv'; # orarul schimbului 2 # în unele zile sunt 6 ore, în altele 7 ore (pe fiecare schimb) my %zile = ('1' => [6,7], '2' => [7,6], '3' => [7,7], '4' => [6,6], '5' => [6,6]); my @data1 = $parser->read_file($file1); my @data2 = $parser->read_file($file2); my %prof = (); # asociază Prof => încadrare şi orar (pe cele două schimburi) my %obi = (); # asociază Obiect => lista Prof pe acel obiect foreach my $p (@data1) { # pentru schimbul 1 my $obiect = $p->[1]; push @{$obi{$obiect}}, $p->[0]; my $or = ''; my $n = 1; # în CSV sunt 6 + 7 + 7 + 6 + 6 = 32 ore pe linie (liberele fiind '') foreach my $zi (1..5) { my $no = $zile{$zi}[0]; my $ore = ''; foreach my $i (1..$no) { $n ++; $ore .= ($p->[$n] || '.'); # orele libere '' vor fi marcate cu '.' } $ore .= '.' if $no != 7; # rezervă o a 7-a oră/zi, dacă nu există deja $or .= $ore . ($zi != 5 ? ' ' : ''); } $prof{$p->[0]}->{or1} = $or; my %cl = (); # asociază Clasă => numărul de ore la Clasă (ale lui $pr) if($or) { $or =~ s/([^\.| ])/$cl{$1}++;$1/eg; } my $cdr = ''; foreach my $k (keys %cl) { $cdr .= $k . $cl{$k}; } $prof{$p->[0]}->{cdr1} = $cdr; } foreach my $p (@data2) { # pentru schimbul 2 my $obiect = $p->[1]; push @{$obi{$obiect}}, $p->[0]; my $or = ''; my $n = 1; # sunt 7 + 6 + 7 + 6 + 6 = 32 ore pe linie (cele libere fiind '') foreach my $zi (1..5) { my $no = $zile{$zi}[1]; my $ore = ''; $ore .= '.' if $no != 7; # rezervă o a 7-a oră/zi, dacă nu există deja foreach my $i (1..$no) { $n ++; $ore .= ($p->[$n] || '.'); # orele libere '' vor fi marcate cu '.' } $or .= $ore . ($zi != 5 ? ' ' : ''); } $prof{$p->[0]}->{or2} = $or; my %cl = (); # $clp{A} = numărul de ore la clasa 'A' (ale lui $pr) if($or) { $or =~ s/([^\.| ])/$cl{$1}++;$1/eg; } my $cdr = ''; foreach my $k (keys %cl) { $cdr .= $k . $cl{$k}; } $prof{$p->[0]}->{cdr2} = $cdr; } # nume : prenume : încadrare1 : încadrare2 : orar1 : orar2 foreach my $pr (sort keys %prof) { my @tmp = split(/\s+/, $pr); # separă Nume şi Prenume print $tmp[0] . ':' . ($tmp[1]||'') . ':' . # Nume : Prenume : ($prof{$pr}->{cdr1} || '') . ':' . ($prof{$pr}->{cdr2} || '') . ':' . # încadrări ($prof{$pr}->{or1} || '').':'.($prof{$pr}->{or2} || ''); # Orar1 : Orar2 print "\n"; } # obiect : Prof1 : Prof2 : ... foreach my $ob (sort keys %obi) { print "\n" . $ob; foreach my $p (uniq @{$obi{$ob}}) { print ':' . $p; } } # Numărul total de ore pe săptămână, la fiecare clasă my %ql1 = (); # asociază Clasă => numărul TOTAL de ore (schimb 1, respectiv 2) my %ql2 = (); foreach my $pr (keys %prof) { if(exists $prof{$pr}->{or1}) { my $or = $prof{$pr}->{or1}; $or =~ s/([^\.| ])/$ql1{$1}++;$1/eg; } if(exists $prof{$pr}->{or2}) { $or = $prof{$pr}->{or2}; $or =~ s/([^\.| ])/$ql2{$1}++;$1/eg; } } print "\n\nSchimb I: "; foreach my $k (sort keys %ql1) { print $k . $ql1{$k} . ' '; } print "\nSchimb II: "; foreach my $k (sort keys %ql2) { print $k . $ql2{$k} . ' '; } print "\n";
Fişierul text rezultat conţine linii cu structura Nume:Prenume:încadrare1:încadrare2:orar1:orar2; urmează un rând liber şi apoi, linii cu structura Obiect:Profesor1:Profesor2 etc., reprezentând profesorii corespunzători fiecărui obiect; urmează un rând liber şi apoi două linii care indică pentru fiecare clasă numărul total de ore. Bineînţeles că intervenim mai mult sau mai puţin în fişierul rezultat, modificând denumiri de obiecte, clase, etc.
Pentru a putea folosi acest fişier text, am încorporat într-unul dintre fişierele HTML ale aplicaţiei un formular simplu (fiind destinat numai administratorului), conţinând un <textarea>:

ideea fiind desigur, aceasta: se copiază prima porţiune din fişierul text (după deschiderea acestuia într-un editor de text) şi se pastează în <textarea>; apoi, click pe butonul "set" va trimite datele respective unei funcţii de pe server care le va separa şi le va înscrie în tabelele corespunzătoare din baza de date existentă. Desigur, analog am procedat pentru a doua porţiune din fişier (pentru a înscrie obiectele şi asocierile obiect-profesori).
Recapitulez: primesc un fişier .XLS, conţinând orarul unei şcoli (cu unul sau două schimburi); îl deschid cu Gnumeric, elimin rândurile şi coloanele inutile şi salvez în format CSV sheet-urile respective; apoi, lansez programul redat ceva mai sus (şi eventual, fac ce modificări ar mai fi necesare în fişierul text rezultat). Mai departe, accesez http://docere.ro/orare, mă loghez ca "administrator" şi (după ce s-a creat baza de date corespunzătoare acelei şcoli, dacă ea nu exista deja) caut formularul descris mai sus şi pastez acolo porţiunea copiată din fişierul text obţinut mai înainte.
Chiar dacă nu este complet "automată", această procedură de lucru este incomparabil mai simplă, mai directă şi mai rapidă decât procedura existentă iniţial, care cerea completarea rând pe rând a mai multor formulare (unul pentru încadrări, unul pentru orar, etc.); desigur, aceste formulare pot fi utile în continuare pentru diverse modificări punctuale asupra datelor.
Appendix (ianuarie 2011)
http://docere.ro/orare de mai sus şi sintagma "Orarul şcolii" (folosită în două locuri) erau iniţial link-uri active (permiţând să accesezi la un moment dat şi aplicaţia reală, ca suport suplimentar pentru aspectele discutate aici). Între timp însă, am desfiinţat aplicaţia respectivă (feb. 2011); mai precis, am refăcut-o folosind PHP şi symfony.
Cum de poate cineva care a recuzat mulţi ani PHP-ul (fiindcă apărea ca un maldăr de funcţii amestecate, lipsit de organizare internă) să "treacă" totuşi la PHP (încă după nu puţină experienţă, cu Perl) - este altă discuţie… în orice caz, PHP5 nu mai este de fel PHP-ul de-acum câţiva ani.
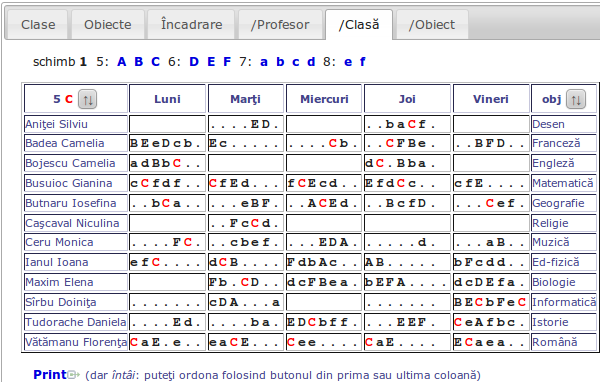
În compensaţie, adăugăm câteva imagini ilustrative pentru aplicaţia desfiinţată "Orarul şcolii". Interfaţa generală, pe care am selectat orarul unei clase se deduce din imaginea următoare:
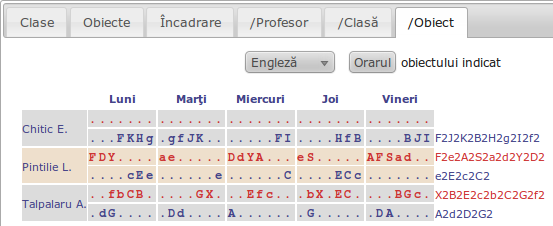
Orarul pentru obiectul selectat:
Pentru adăugarea de clase (analog pentru obiecte şi încadrări), foloseam un <textarea>:
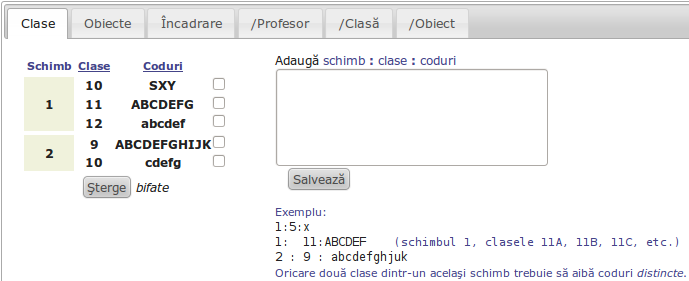
iar pentru asocierea între obiecte şi profesori:
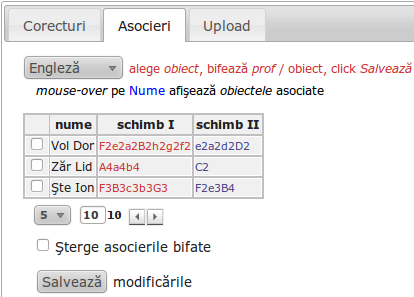
Întreaga interfaţă a fost lucrată "manual" (fişiere HTML, javascript, CSS), folosind Template Toolkit şi jQuery (mai ales pentru comunicarea Ajax cu subrutinele Perl de pe server). Pot recunoaşte că folosind acum symfony cum am specificat mai sus, am avut mult mai puţin de lucru (şi nu numai pentru că am putut refolosi unele dintre funcţiile deja scrise).
Un amănunt decisiv
Conţinutul ultimeia dintre imaginile redate mai sus are o semnificaţie aparte…
Pentru specificarea încadrării profesorilor pe obiecte, interfaţa respectivă prevede un <select> pentru lista obiectelor înregistrate (pe imagine apare selectat "Engleză"), un tabel paginat conţinând profesorii şi un indicator de opţiune "Şterge asocierile bifate", împreună cu un buton final "Salvează".
Pentru a reflecta asocierile între obiect şi profesorii încadraţi pe acel obiect, s-a suplimentat tabelul profesorilor cu o coloană de elemente <checkbox> (în marginea stângă a tabelului); <checkbox>-ul din dreptul unui profesor apare "bifat" dacă profesorul respectiv a fost asociat anterior, obiectului.
Fiecare dintre aceste elemente de marcare este specificat astfel: <input type="checkbox" name="pr[%pr.id%]" />, unde pr.id este valoarea de "primary key" a înregistrării (în baza de date) corespunzătoare profesorului respectiv.
Bifând corespunzător profesorii care trebuie asociaţi obiectului şi făcând click pe "Salvează" se lansează o funcţie care transmite ID-ul obiectului selectat şi valorile atributului "name" ale checkbox-urilor bifate de utilizator, unei funcţii Perl de pe server care va deduce ID-urile profesorilor (din valorile "name" primite) şi va înscrie corespunzător asocierile respective în baza de date aferentă.
Formulând mai general: dacă ai o listă de înregistrări şi vrei să asiguri posibilitatea de a efectua anumite operaţii pe anumite itemuri ale acestei liste, atunci adaugă la marginea fiecărui item câte un <checkbox> având în atributul "name" ID-ul itemului respectiv şi realizează o funcţie javascript care să transmită serverului valorile "name" ale checkbox-urilor bifate de către utilizator (şi o funcţie pe server - aici, în Perl - care să deducă din parametrii primiţi ID-urile necesare şi să realizeze corespunzător în baza de date, operaţia indicată).

Am fost chiar mândru de această idee, la vremea respectivă…
Şi tocmai faptul că am redescoperit-o, standardizată în interfeţele cu batch actions generate cu symfony, a jucat rolul de "acel mic amănunt" care te cucereşte şi te motivează iniţial, faţă de un anumit produs.
Pe imaginea alăturată se vede rezultatul obţinut folosind generatoarele din symfony pentru o anumită colecţie de obiecte.
Au fost selectate nişte itemuri din lista rezultatelor şi o operaţie ("înscrie Gradaţie de Merit") din lista acţiunilor (analog cum mai sus, am selectat profesorii şi obiectul de asociat lor, "Engleză"); iar click pe butonul "Execută" va declanşa funcţiile care în final realizează operaţia indicată asupra itemurilor bifate.
symfony generează automat (dar opţional) interfaţa respectivă (pentru colecţia de înregistrări indicată), programatorul având doar de definit acţiunile ("batch actions") necesare (adică funcţiile care să realizeze operaţia indicată asupra itemurilor bifate, angajând corespunzător baza de date).
Mai este de remarcat un "amănunt", care poate determina şi el aderarea (sau neaderarea) la un anumit framework: rămâne şi programatorului ceva de făcut? Dacă da - bine, dacă nu…
Am experimentat şi eu, situaţia extremă când programatorul nu are de scris nici o linie de cod: am realizat (ca exerciţiu) un site "Revista şcolii", folosind Diem şi anume… fără să scriu eu, nici o linie de cod semnificativă; poate că pentru unii ar fi mulţumitor, dar eu m-am jenat să public aşa ceva şi am renunţat să mai folosesc Diem (nefiind în categoria de utilizatori căreia îi este adresat).
vezi Cărţile mele (de programare)