Formularea orarului, cu Python şi Sphinx
Faţetele orarului şcolar
Orarul şcolar implică două probleme: elaborarea orarului şi publicarea acestuia.
Adevărata problemă este elaborarea orarului - chestiune dificilă, de care nu ne vom ocupa aici. Precizăm doar că există pachete software care modelează şi rezolvă în măsură suficientă "problema orarului" (acoperind mai mult sau mai puţin şi aspectul publicării orarului); menţionăm aici FET.
Publicarea orarului înseamnă expunerea lui (fireşte, undeva pe Internet), cu scopul de a permite profesorilor şi elevilor (în principal) să obţină uşor informaţiile relevante pentru fiecare caz, privitoare la orarul curent.
Pentru a obţine uşor informaţiile relevante, nu este acceptabil un tabel Excel (ori Word) care să prezinte orarul respectiv (însemnând de fapt, vreo patru coli A4 aşezate una lângă alta la afişierul şcolii); într-un astfel de caz, ca să extragi de exemplu orarul unei clase - trebuie să cauţi celulele în care apare clasa respectivă (pe coloanele corespunzătoare zilelor) şi să notezi manual obiectul sau profesorul corespunzător rândului respectiv.
O expunere a orarului care într-adevăr să satisfacă toate interesele posibile este una care:
permite profesorilor, diriginţilor, elevilor să obţină direct şi oricând (click şi "gata de printat") orarul propriu, într-o formulare clară şi nesofisticată
permite conducerii şcolii sau şefilor de catedră să obţină direct orarul corespunzător uneia dintre disciplinele existente (de exemplu, în scopul stabilirii unei întruniri a catedrei)
permite celui care se ocupă de întreţinerea orarului să sesizeze uşor unele scăpări care se pot întâmpla (doi profesori în acelaşi timp la o aceeaşi clasă)
Concepţia obişnuită pentru realizarea unei asemenea expuneri a orarului presupune crearea şi întreţinerea unei baze de date, conţinând tabele relaţionate corespunzător pentru profesori, clase, discipline, încadrări (care profesor, la care clasă, ce disciplină, câte ore). Avem şi aici câteva exemplificări (vezi încadrare şi orar şcolar), folosind PHP sau Perl şi MySQL.
De obicei lucrurile sunt "amestecate" (publicare, dar şi elaborare), procedura tipică decurgând astfel: se preiau datele necesare de la utilizator şi se stochează într-o anumită bază de date (sau în anumite fişiere); apoi, se lansează funcţiile care construiesc un orar pe baza datelor înregistrate; în final fireşte că se externalizează orarul construit, prevăzând "în plus" diverse formate finale.
Să recunoaştem că este mai greu de separat, decât de amestecat… Dacă avem forţa de a separa lucrurile, atunci am putea vedea că de fapt publicarea orarului - respectând chiar toate clauzele precizate mai sus - nu necesită nicidecum, existenţa vreunei baze de date.
Este suficient (ca "input") un simplu tabel obişnuit, care să conţină orarul propriu-zis. Putem folosi chiar şi numai javaScript, pentru a extrage din acest tabel datele cerute ("informaţiile relevante" solicitate de utilizatorul curent) şi a le organiza corespunzător într-o pagină HTML de răspuns.
Word-apetitul şi chestiunea realizării documentaţiilor utile
JSDoc este o aplicaţie (scrisă în Perl prin anul 2000 şi reluată ulterior în javaScript) care primind ca "input" fişiere cod-sursă javaScript (conţinând şi anumite "taguri" speciale de "comentariu") produce un set de pagini HTML care împreună, constituie documentaţia necesară pentru codul sursă respectiv. JSDoc serveşte pentru a produce automat documentaţia (sau manualul de utilizare) pentru o bibliotecă javaScript (a vedea jsdoc/index.html).
Sphinx este deasemenea un generator de documentaţie, dezvoltat iniţial pentru documentarea automată a proiectelor bazate pe limbajul Python. Primind ca "input" fişiere-text structurate conform unui limbaj de marcare realmente simplu, ReStructuredText - Sphinx produce "documentaţia" corespunzătoare, într-un format sau altul (inclusiv, ca site HTML, sau ca document PDF).
În cazul nostru, avem ca "input" un fişier Excel (sau un fişier-text) în care este scris orarul (în coloane cu semnificaţia "numele profesorului", "ziua", "ora I", "ora a II-a", etc., în coloanele "ora" fiind înscrise clasele la care trebuie să intre profesorii). Ideea este de a folosi fie JSDoc, fie Sphinx pentru a produce "documentaţia" corespunzătoare, ca site HTML; am ales Sphinx având în vedere experienţa anterioară web24.docere.ro - dar la fel de bine puteam folosi JSDoc.
Şi dacă putem proceda astfel pentru un obiect aşa de complex cum este orarul şcolar - de ce n-am putea proceda la fel şi pentru documente mai simple, cum sunt de exemplu planificările şi alte documente şcolare tipice? Word-apetitul instituţiilor şi oficialităţilor noastre a ajuns de nesuportat! Nu este de loc necesar Microsoft-Word ca să produci astfel de documente (rezultând în fond doar documente scrise, statice şi izolate - nicidecum documentaţii utile şi uşor de întreţinut în timp).
Este grotesc să-ţi imaginezi că ai folosi Word pentru a realiza vreun soi de documentaţie pentru Python - cât de cât precum cea de la python.org.doc. Iar ceea ce este bun pentru realizarea unor documentaţii aşa de complexe este cu siguranţă adaptabil şi de recomandat pentru realizarea oricărei documentaţii utilizabile.
Şablonul comun de orar
Aplicaţia propusă constă în transformarea fişierului Excel în care este scris orarul şcolii într-un "site HTML" care să asigure posibilităţile fireşti de documentare asupra orarului (şi care să fie uşor de întreţinut, având în vedere că orarul "real" poate suferi modificări frecvente). Ca să fie într-adevăr o "aplicaţie", va trebui de la bun început să evităm aspectele particulare şi să modelăm lucrurile în aşa fel încât să se poată opera pe cât mai multe cazuri (şi nu doar pe cazul propriei şcoli).
Nu contează faptul că fişierul de "input" (în care este scris iniţial orarul) a fost realizat cu Excel, sau cu Word, sau poate este un document PDF (sau de alt tip): oricare dintre aceste formate poate fi convertit uşor într-un fişier-text şi pe acesta îl vom prelucra apoi în cadrul aplicaţiei.
Care ar fi cea mai obişnuită (comună) formă de scriere a orarului unei şcoli? Probabil aceasta:
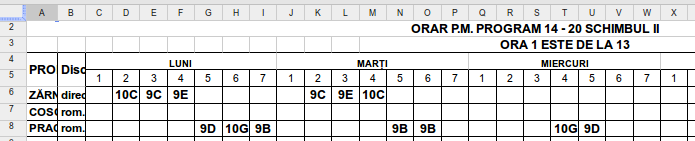
Fişierul conţine câte o "foaie" pentru fiecare schimb. Coloanele A şi B conţin respectiv numele profesorului şi disciplina; coloanele C..I conţin clasele afectate profesorilor respectivi în orele 1..7 din ziua LUNI şi analog, coloanele J..P pentru ziua "MARŢI", etc. Numărul de ore pe zi (6 sau 7) poate să difere după schimb şi după zi (şi după şcoală).
Pentru fiecare profesor, datele relevante se află pe linia care îi corespunde - de exemplu, pentru primul profesor (linia 6) putem constitui următorul "dicţionar" (cum zicem în Python) al orelor sale:
{ obiect: 'direc',
Luni: [-, 10C, 9C, 9E, -, -, -],
Marţi: [-, 9C, 9E, 10C, -, -, -],
... }
Un "dicţionar" pentru orarul unei clase va fi mai greu de constituit, fiindcă trebuie investigate pe rând coloanele corespunzătoare orelor din fiecare zi pentru a identifica acea clasă (reţinând obiectul sau profesorul de pe liniile cu care se intersectează aceste coloane).
Desigur, primul lucru care trebuie făcut este să transformăm fişierul în care este scris orarul (oricare ar fi formatul acestuia) în fişier-text. În cazul unui fişier Excel, aceasta se obţine direct din meniul Excel, alegând opţiunea de salvare ca fişier CSV; altfel, orice format-text ar rezulta - acesta va putea fi uşor convertit într-un format CSV (pe fiecare linie text avem valori separate prin virgulă, reprezentând consecutiv valorile din coloanele A, B, C, etc. din fişierul iniţial).
Prin urmare, nu restrângem cu nimic generalitatea considerând că "inputul" aplicaţiei noastre sunt fişierele în format CSV corespunzătoare schimburilor existente - fie acestea orarAM.csv şi orarPM.csv (presupunând pentru simplitate că avem obişnuitele două schimburi; dar desigur, putem adăuga dacă este cazul şi orar_special.csv).
Desigur (tot în vederea generalităţii) eliminăm din aceste fişiere porţiunea iniţială de antet, precum şi eventualele linii libere. Însă trebuie să reţinem numărul de ore pe fiecare zi (de exemplu sub forma ore_zi_I = (7, 7, 6, 6, 7)) - fiindcă altfel, de pe o linie CSV ca
"BAZON V.",mat/inf,,,,9D,10A,9E,,,,,9E,10A,10A,,,,,,10A,10A,,,,,10A,9D,10A,,,9E,10A,9D,10A,,
nu am putea deduce care ore sunt LUNI (primele, dar câte anume?), care în ziua a doua, etc.
Rangurile orelor din zi
Toate rândurile CSV de forma redată mai sus au acelaşi număr de câmpuri (coloane), în cadrul unui aceluiaşi schimb. Indexând de la stânga, câmpul de nume are rangul 0, iar cel pentru disciplină are rangul 1; dacă prima zi are 7 ore, câmpurile corespunzătoare acesteia au rangurile 2, 3, ..., respectiv 8 (iar orele corespunzătoare următoarei zile încep de la rangul 9).
Următoarea funcţie (denumită "ranguri") primeşte un tuplu conţinând numărul de ore pe fiecare zi (dintr-un acelaşi schimb) şi returnează o listă în care fiecare element este lista rangurilor câmpurilor corespunzătoare câte unei zile 0..4.
# -*- coding: utf-8 -*- def ranguri(ore_zi): rgs, m1 = [], 2 # rgs este 'lista vidă', m1 este iniţializat cu 2 for nro in ore_zi: # nro = numărul de ore din ziua curentă m2 = m1 + nro # rangul primului câmp din ziua următoare rgs.append(range(m1, m2)) # adaugă lista rangurilor orelor pe ziua curentă m1 = m2 return rgs
Prima linie este un comentariu special, care indică interpretorului Python că (în celelalte comentarii) se foloseşte codificarea Unicode (o literă precum 'ă' este codificată pe doi octeţi şi nu pe unul singur ca în cazul setului ASCII standard).
Lansăm Python şi importăm modulul creat (în fişierul test1.py); "importarea" modulului înseamnă doar că numele respectiv este adăugat în lista de simboluri a sesiunii Python curente - pentru a şi accesa o funcţie din modul, numele acesteia trebuie prefixat cu numele modulului:
vb@vb:~/ORAR$ python >>> import test1 >>> rgs = test1.ranguri >>> print rgs((4, 6, 5)) [[2, 3, 4, 5], [6, 7, 8, 9, 10, 11], [12, 13, 14, 15, 16]] >>>
Desigur, am făcut aici un simplu test, pe un caz oarecare de "ore_zi" (şi am avut în vedere cazul unui prim contact cu Phyton). Dar ideea de a scrie separat câte o funcţie şi a o testa şi pune la punct astfel - înainte de a o şi încadra definitiv în modulul "de bază" - ţine de "bunele practici" pentru dezvoltarea oricărei aplicaţii.
Aplicaţia noastră nu are de ce să măsoare mai mult de 150-200 de linii-program, încât alegem să scriem totul într-un singur modul. Folosind funcţia testată mai sus, putem începe acest modul prin:
# -*- coding: utf-8 -*- csv1 = file( "orarAM.csv", "r" ) csv2 = file( "orarPM.csv", "r" ) ore_zi1 = (6, 6, 6, 6, 6) # tuplul numărului de ore pe zi ore_zi2 = (7, 7, 7, 7, 7) n_col1 = sum(ore_zi1, 2) # numărul total de câmpuri n_col2 = sum(ore_zi2, 2) def ranguri(ore_zi): rgs, m1 = [], 2 for nro in ore_zi: m2 = m1 + nro rgs.append(range(m1, m2)) m1 = m2 return rgs rgs1, rgs2 = ranguri(ore_zi1), ranguri(ore_zi2)
Desigur, va trebui să nu uităm că fişierele accesate prin csv1 şi csv2 vor trebui şi închise, la un moment sau altul.
Variabilele instituite mai sus sunt suficiente (dacă ignorăm faptul că ne-am limitat la două schimburi) pentru a trece la constituirea "dicţionarelor" necesare scrierii comode a fişierelor cerute de Sphinx.
Dicţionarul de bază al aplicaţiei
Un dicţionar Python este o structură de date asemănătoare cu hash-urile din Perl, cu "tablourile asociative" din PHP, cu "object"-ul din javaScript, etc. - conţinând perechi de forma KEY: VALUE, în care KEY este de obicei un şir de caractere, iar VALUE poate fi o "valoare" propriu-zisă, sau poate fi orice altă structură de date.
Următoarea continuare a modulului pe care l-am început mai sus construieşte un dicţionar denumit orar, având drept chei valorile din primul câmp (numele profesorilor) de pe fiecare rând din cele două fişiere CSV şi drept valori câte un dicţionar de chei 'disc' (pentru disciplina corespunzătoare profesorului respectiv), 'AM' şi 'PM'; cheii 'AM' (şi analog, cheii 'PM') îi corespunde un dicţionar care asociază fiecărei zile 1..5 lista orelor din acea zi pentru profesorul respectiv.
Construcţia respectivă decurge prin apelarea funcţiei add_to_orar(row) pentru fiecare dintre rândurile existente în primul şi respectiv al doilea fişier CSV; variabilele necesare (care schimb, câte coloane are fişierul CSV respectiv, între ce ranguri se află orele din fiecare zi) au aceleaşi valori pentru toate rândurile dintr-un acelaşi fişier CSV - aşa că le-am setat corespunzător înainte de a apela "add_to_orar()" (în loc de a le fi postat drept parametri de apel ai funcţiei).
orar = {} # orar[nume] = {'disc': None, 'AM': None, 'PM': None} def add_to_orar(row): """ presupune setate variabilele specifice fiecărui schimb: sch, nr_col şi rgs = 'AM'/'PM', nr. câmpuri, marginile câmpurilor""" flds = row.strip().split( "," ) for i in range(2, nr_col): flds[i] = flds[i].strip().replace('"', '').replace(' ', '') prof = flds[0].strip().replace('"', '') if prof not in orar: orar[prof] = {'disc': '', 'AM': {}, 'PM': {}} if orar[prof]['disc'] == '': orar[prof]['disc'] = flds[1].lower() for zi in range(1, 6): orar[prof][sch][zi] = list(flds[i] for i in rgs[zi-1]) sch, nr_col, rgs = 'AM', n_col1, rgs1 # respectiv = 'PM', n_col2, rgs2 for row in csv1: # in csv2 pentru celălalt schimb add_to_orar(row) csv1.close() # respectiv, csv2.close()
În vederea testării - putem implica modulul “pretty-print”, adăugând (numai temporar):
import pprint
pprint.pprint(orar)
După ce salvăm modulul astfel constituit (să zicem, în "orar.py") putem obţine rezultatele într-un fişier "test.txt" prin comanda python orar.py > test.txt; pentru exemplu, o intrare în dicţionarul rezultat arată astfel:
'BAZON V.': {'AM': {1: ['', '', '11B', '11B', '', ''],
2: ['', '', '12B', '12B', '12B', ''],
3: ['', '11B', '11B', '', '', ''],
4: ['', '', '', '', '', ''],
5: ['', '', '', '', '', '']},
'PM': {1: ['', '', '', '9D', '10A', '9E', ''],
2: ['', '', '', '9E', '10A', '10A', ''],
3: ['', '', '', '', '10A', '10A', ''],
4: ['', '', '', '10A', '9D', '10A', ''],
5: ['', '9E', '10A', '9D', '10A', '', '']},
'disc': 'mate/inf'},
Plecând de la dicţionarul "orar" este foarte uşor să obţinem un dicţionar al disciplinelor din orar (disciplină -> lista profesorilor care o predau):
obiect = {} for prof in orar: disc = orar[prof]['disc'] if disc not in obiect: obiect[disc] = [] obiect[disc].append(prof) ''' Pentru testare: ''' # for ob, list_pr in obiect.iteritems(): # print ob, list_pr
Analog procedăm (ceva mai dificil totuşi) pentru a obţine un dicţionar al claselor (reflectând orarul de furnizat fiecăreia). Investigând pe coloane, ca să depistăm obiectele de plasat fiecăreia dintre clasele respective - avem acum şi şansa de a sesiza eventualele erori de genul "doi profesori în aceeaşi oră la o aceeaşi clasă".
Crearea fişierelor ".rst" şi obţinerea documentaţiei finale cu Sphinx
Pe directorul ~/ORAR (în care avem şi modulul descris mai sus, împreună cu fişierele CSV aferente) lansăm sphinx-quickstart - program interactiv furnizat de Sphinx. Acesta crează (pe baza opţiunilor utilizatorului) un script de configurare conf.py şi un fişier Makefile; după ce utilizatorul va adăuga fişierele-text necesare, acestea vor fi transformate de către Sphinx într-o documentaţie unitară (ca site HTML, sau ca document PDF, etc.) în urma lansării comenzii make html (sau 'make latex', sau 'make latexpdf', etc.).
În cazul nostru, "fişierele-text necesare" vor trebui să fie create de către scriptul numit mai sus orar.py, încât secvenţa de comenzi pentru generarea de către Sphinx a site-ului HTML este:
vb@vb:~/ORAR$ python orar.py cele trei dicţionare, plus "fişiere-text necesare" vb@vb:~/ORAR$ make html Sphinx generează site-ul corespunzător acestor fişiere-text
Fişierele site-ului creat astfel sunt stocate în subdirectorul ORAR/_build/html. Utilizatorul are la dispoziţie şi subdirectoarele ORAR/_static şi ORAR/_templates, în care va putea înscrie eventual propriile fişiere javaScript, CSS, sau fişiere-imagine, precum şi fişiere HTML care să modifice "layout"-ul setat implicit de către Sphinx pentru pagini.
"Fişierele-text necesare" sunt în fond fişiere-text obişnuite, dar suplimentate cu nişte marcaje simple (pentru titluri de secţiune, liste de itemi, link-uri, referinţe la fişiere-imagine, etc.) - vezi de exemplu reStructuredText.
În mod standard, trebuie scris un fişier index.rst care să conţină "cuprinsul" documentaţiei (sau, al site-ului), iar în cazul nostru acesta ar putea fi formulat astfel:
Orarul şcolii ============= .. toctree:: :maxdepth: 2 Orare Profesori <orar> Orare Clase <clase> Orare Discipline <obiecte> * :ref:`genindex` profesori, clase, discipline
Întâlnind sublinierea cu "=" (şi apoi un rând liber), Sphinx va transforma titlul "Orarul şcolii" într-un element <h1>; elementele de sub directiva .. toctree:: vor fi transformate în link-uri către fişierele "orar.html", "clase.html" şi "obiecte.html" (ce vor rezulta din transformarea fişierelor ".rst" create de orar.py). Mai precis, fişierul index.html creat de Sphinx va conţine diviziunea:
<div class="section" id="orarul-scolii"> <h1>Orarul şcolii<a class="headerlink" href="#orarul-scolii" title="Permalink to this headline">¶</a></h1> <div class="toctree-wrapper compound"> <ul> <li class="toctree-l1"><a class="reference internal" href="orar.html"> Orare Profesori</a></li> <li class="toctree-l1"><a class="reference internal" href="clase.html"> Orare Clase</a></li> <li class="toctree-l1"><a class="reference internal" href="obiecte.html"> Orare Discipline</a></li> </ul> </div> <ul class="simple"> <li><a class="reference internal" href="genindex.html"><em>Index</em></a> profesori, clase, discipline</li> </ul> </div>
Intenţia noastră este ca fişierul orar.rst să conţină pentru fiecare profesor înregistrări de forma:
.. index:: Bazon V. BAZON V. - mate/inf:: - - 11B 11B - - - - - 9D 10A 9E - - - 12B 12B 12B - - - - 9E 10A 10A - - 11B 11B - - - - - - - 10A 10A - - - - - - - - - - 10A 9D 10A - - - - - - - - 9E 10A 9D 10A - -
Am prevăzut directiva .. index:: pentru ca Sphinx să încorporeze termenul respectiv în pagina de căutare genindex.html pe care o generează (împreună cu anumite fişiere javaScript: searchtools.js, searchindex.js şi altele) în baza configurărilor existente.
Considerăm absolut inutilă, înzorzonarea formatului descris mai sus cu explicitări suplimentare de genul: "Luni", etc. sau "ora I", etc. (şi evident că am preferat acest format în locul tradiţionalului format tabelar - pe o singură linie foarte largă). Dar desigur, vom plasa la începutul fişierului o indicaţie a faptului că întâi este redat orarul pentru "AM" şi apoi orarul pentru "PM".
Operaţia de modelat este relativ simplă: parcurgem dicţionarul "orar" şi scriem în fişierul orar.rst elementele curente ale acestuia, în formatul stabilit mai sus. O singură problemă apare: trebuie să folosim codificarea Unicode, iar în Python (până la versiunea 2.7) scrierea unui fişier folosind altă codificare de caractere decât ASCII nu este o operaţie nativă; soluţia obişnuită se bazează pe modulul suplimentar codecs (Encode and decode data and streams).
O soluţie instructivă, la care m-am gândit la un moment dat (până a ajunge totuşi la codecs) constă în scrierea dicţionarului "orar" într-un fişier-text (folosind "pretty-print", cum am arătat undeva mai sus) şi formularea unui script Perl - limbaj care foloseşte Unicode în mod nativ - care să preia acest fişier şi să scrie corespunzător fişierul "orar.rst".
Adăugăm în modulul "orar.py" următoarea secvenţă (notând însă, că ea ar putea fi concepută şi scrisă mai concis, sau mai elegant…):
import codecs out = codecs.open('orar.rst', 'w', 'utf-8') out.write('-AM: 6 ore, 8-14; -PM: 7 ore, 13-20\n' + '-'*35 + '\n\n') for prof in sorted(orar): nume = unicode(prof, 'utf-8') disc = unicode(orar[prof]['disc'], 'utf-8') out.write('.. index:: ' + nume.title() + '\n\n') out.write(nume + ' - ' + disc + '::\n\n') am, pm = orar[prof]['AM'], orar[prof]['PM'] for zi in range(1, 6): if(am): ore = am[zi] so = ' ' for o in ore: if o: so += o.ljust(4) else: so += '-'.ljust(4) else: so = ' '*3 + '- '*6 if(pm): ore = pm[zi] to = ' ' for o in ore: if o: to += o.ljust(4) else: to += '-'.ljust(4) else: to = ' '*3 + '- '*7 out.write(so + ' '*4 + to + '\n') out.write('\n\n') out.close()
În mod analog creem fişierele clase.rst (orarele claselor, folosind dicţionarul corespunzător constituit anterior) şi obiecte.rst (orarele disciplinelor).
Lansând python orar.py şi apoi make html obţinem site-ul HTML dorit. Când va apărea vreo modificare în orar, probabil ca nu vor trebui mai mult de două minute pentru a transforma fişierul Excel în fişiere CSV şi a lansa iarăşi "orar.py" şi "make html" pentru obţine din nou, site-ul HTML corespunzător orarului curent.
Publicarea site-ului creat pentru orar
Site-ul a fost creat în directorul ~/ORAR/_build/html, pe calculatorul propriu. Ca să-l punem la dispoziţia potenţialilor utilizatori trebuie să-l transferăm într-un anumit domeniu Internet. O soluţie necostisitoare este aceea de a-l transfera într-un domeniu propriu existent (în loc de a constitui unul nou); cu alte cuvinte, trebuie să creem un "subdomeniu".
Modalitatea de creare a unui subdomeniu este simplă şi o exemplificăm aici pe cazul unui "host" local existent. Presupunem că în /etc/apache2/sites-available avem următoarea definiţie:
<VirtualHost *:80> DocumentRoot /home/vb/Symfony/web DirectoryIndex app.php ServerName sfy.d # ... </VirtualHost>
În baza acestei definiţii, serverul Apache va deservi cererea http://sfy.d (formulată în cazul de faţă, dintr-un browser deschis pe acelaşi calculator cu Apache) returnând fişierul "app.php" (după execuţia instrucţiunilor PHP existente) indicat prin directiva DirectoryIndex.
Dacă plasăm _build/html ca subdirector "/html_orar" al directorului "/web" indicat de directiva DocumentRoot - atunci în mod normal, vom putea accesa şi site-ul constituit pentru orar, prin http://sfy.d/html_orar/index.html.
Aceasta ar fi în fond cea mai simplă soluţie - numai că de obicei avem de ţinut seama de unele aspecte particulare site-ului "de bază". De exemplu, "sfy.d" este bazat pe Symfony şi pentru a putea proceda în acest "cel mai simplu" mod, ar trebui să îndrăznim să facem pentru "sfy.d" anumite reconfigurări care de obicei sunt "nestandard".
În loc de aceasta, putem adăuga un "subdomeniu", deasupra definiţiei host-ului respectiv:
<VirtualHost *:80> ServerName orar.sfy.d ServerAlias orar.sfy.d DocumentRoot /home/vb/Symfony/html_orar # ... alte directive de configurare </VirtualHost> <VirtualHost *:80> DocumentRoot /home/vb/Symfony/web DirectoryIndex app.php ServerName sfy.d ServerAlias *.sfy.d # ... alte configurări </VirtualHost>
Am evidenţiat în textul de mai sus că am plasat /html_orar direct în /Symfony (şi nu în /web) - astfel că acum, "orar" este independent de site-ul de bază (orar.sfy.d nu poate accesa ce este în /web, iar sfy.d nu poate accesa ce este în /html_orar). Singura configurare suplimentară, care a trebuit adăugată în definiţia site-ului "de bază" este ServerAlias-ul *.sfy.d.
Desigur - fiind vorba de host-uri locale - trebuie să mai înscriem linia 127.0.0.1 orar.sfy.d sfy.d (în această ordine, întâi subdomeniul şi apoi domeniul de bază) în fişierul /etc/hosts.
După ce restartăm Apache, vom putea accesa ca şi mai înainte http://sfy.d, dar acum şi http://orar.sfy.d (aferent site-ului creat cu scriptul "orar.py" şi cu Sphinx).
vezi Cărţile mele (de programare)