Notaţia prefix canonică şi reprezentarea DOT a expresiei
[1] Algoritm pentru descrierea DOT a arborelui sintactic al unei expresii
[2] Arbori aritmetici şi expresii uzuale
[3] How to implement a programming language [google mishoo]
Programul din [1] preia o expresie aritmetică în format infixat şi (folosind Climb::get_tree() din [2]) obţine arborele sintactic ArTree corespunzător expresiei; reprezentarea textuală prefixată indusă de operator<< pentru obiecte ArTree este apoi transmisă funcţiei to_DOT(), care analizează formatul prefixat primit şi produce un fişier conţinând descrierea DOT a arborelui.
Dar putem remodela (sau "simplifica") lucrurile, renunţând să mai angajăm clasa ArTree: este uşor de "rescris" metoda principală implicată Climb::parse_climb(), astfel încât aceasta să construiască şi să returneze chiar forma prefixată "canonică", în loc de obiect ArTree.
Pentru o expresie algebrică dată (în formatul obişnuit, infixat) - vrem să construim un obiect care să asigure o verificare sintactică minimală a expresiei date, inducând apoi formatul prefixat complet parantezat precum şi descrierea DOT a arborelui sintactic al expresiei:
#include <string> #include <iostream> #include <sstream> // operaţii "stream" cu şiruri #include <algorithm> // copy_if(), find(), adjacent_find() #include <cctype> // tipuri de caractere (isspace(), etc.) class Symbex { public: Symbex(std::string&); // verifică sintaxa şi construieşte obiectul void set_prefix(); // constituie formatul prefixat complet parantezat void get_DOT(); // furnizează descrierea DOT a arborelui sintactic private: std::istringstream infix; // "buffer" pentru expresia infixată dată (fără spaţii) std::string prefix; // pentru formatul prefixat complet parantezat bool syntax, has_prefix; void croak(const std::string&); // verifică sintaxa expresiei std::string parse_climb(int); // conversie `infix` —> `prefix` ("precedence climbing") std::string parse_primary(); void cout_DOT(); // constituie descrierea DOT a expresiei (pentru `dot`, sau Graphviz) char look_ahead() { // furnizează caracterul următor, păstrând poziţia curentă char c; infix >> c; infix.putback(c); // reînscrie caracterul citit, în buffer-ul expresiei return c; } friend std::ostream& operator<<(std::ostream&, const Symbex&); // emite `prefix` };
Constructorul constituie întâi o "copie" a expresiei date, ignorând însă caracterele spaţiu (eliminarea spaţiilor simplifică verificarea sintactică); şirul rezultat este transmis metodei private croak() şi dacă aceasta nu semnalează vreo eroare de sintaxă - atunci el este reţinut pe câmpul privat infix.
Symbex::Symbex(std::string& expression) { std::string expr; expr.resize(expression.size()); auto it = std::copy_if(expression.begin(), expression.end(), expr.begin(), [](char c) { return !isspace(c); }); expr.resize(std::distance(expr.begin(), it)); syntax = true; try {croak(expr);} // "cârâie" (comutând `syntax`) dacă vede greşeli sintactice catch(std::string& error) { std::cout << error << '\n'; } if(syntax) // reţine textul expresiei date (fără spaţii) infix.str(expr); has_prefix = false; }
Pentru a asigura copierea din şirul "expression" în şirul "expr" - am folosit mai sus std::copy_if() din <algorithm>; predicatul care decide ce caractere să fie copiate (cele diferite de spaţiu) este furnizat prin funcţia anonimă [](char c) {return ! isspace(c);} (a vedea C++11). Este necesară trunchierea finală - prin expr.resize(distance(expr.begin(), it)), unde it pointează după ultimul caracter copiat; altfel, unele teste din croak() ar parcurge şi spaţiile reziduale rămase la sfârşitul şirului expr.
Metodele publice set_prefix() şi get_DOT() ţin cont de starea câmpurilor booleene private syntax şi respectiv has_prefix, declanşând metodele private parse_climb() şi respectiv cout_DOT():
void Symbex::set_prefix() { if(syntax) { // numai pentru expresie corectă sintactic prefix = parse_climb(1); has_prefix = true; } } void Symbex::get_DOT() { if(has_prefix) cout_DOT(); // numai dacă s-a obţinut `prefix` } inline std::ostream& operator<<(std::ostream& out, const Symbex& S) { out << S.prefix << '\n'; // inserează şirul `prefix` în stream-ul `out` return out; }
Forma prefixată se va obţine pe câmpul privat prefix; în loc de o metodă (publică) de acces la acest câmp, am preferat să supraîncărcăm operator<<() - încât şirul prefix va putea fi obţinut şi într-un obiect sstringstream (astfel că va putea fi remis "public", ca şir).
Verificarea sintactică (la nivel de caracter) a expresiei
Într-o expresie algebrică întâlnim operatori, operanzi şi paranteze. Următoarea funcţie testează dacă avem de-a face, sau nu, cu un operator:
inline bool isoperator(char c) { return (c=='+') || (c=='-') || (c=='*') || (c=='/') || (c=='^'); }
Acceptăm ca operanzi litere individuale (reprezentând fiecare, o "variabilă"), sau valori numerice reprezentate în modul obişnuit (ca secvenţă de cifre zecimale, intercalând cel mult un '.' - "virgula zecimală"). Metoda croak() asigură câteva verificări necesare pentru corectitudinea sintactică a expresiei infixate (fără spaţii) indicate ca argument:
void Symbex::croak(const std::string& expr) { std::string croak_msg; // colectează mesaje de eroare/atenţionare asupra sintaxei // caracterele admise (literă, operator, cifră, '(', ')', '.') auto p1 = find_if_not(expr.begin(), expr.end(), [](char c) { return isalpha(c) || isoperator(c) || isdigit(c) || (c==')') || (c=='(') || (c=='.'); }); if(p1 != expr.end()) { syntax = false; croak_msg += "- caracter nerecunoscut\n"; } // balansarea parantezelor int par = 0; for_each(expr.begin(), expr.end(), [&par](char c) { if(c=='(') par++; else if(c==')') par--; }); if(par != 0) { syntax = false; croak_msg += "- paranteze nebalansate\n"; } // "variabilă" = o singură literă (urmată de operator sau ')') // operator este precedat de operand sau ')' şi urmat de operand sau '(' auto p2 = adjacent_find(expr.begin(), expr.end(), [](char c1, char c2) { return (isalpha(c1) && !(isoperator(c2) || (c2 == ')'))) || ((c2 == '(') && isalnum(c1)) || (isoperator(c1) && !(isalnum(c2) || (c2 == '('))) || (isoperator(c2) && !(isalnum(c1) || (c1 == ')'))); }); if(p2 != expr.end()) { syntax = false; croak_msg += "- \"variabilă\"=literă; operator greşit încadrat\n"; } if(! syntax) throw croak_msg; }
Condiţiile testate mai sus acoperă cele mai importante cazuri - dar este clar că ele sunt insuficiente pentru corectitudinea sintactică a unei expresii infixate. Metoda de mai sus va depista eventualele greşeli neintenţionate - dar este uşor să o discredităm, dacă aceasta dorim (de exemplu, ")(" este acceptată…); codul respectiv este să zicem, un context de folosire a unor metode din <algorithm> (find_if_not(), for_each(), adjacent_find()) în corelare cu funcţii anonime, în C++11.
Obţinerea formatului prefixat complet parantezat
Preluăm din [2] caracterizarea operatorilor (prioritate şi asociere):
inline int priority(char op) { switch(op) { case '+': case '-': return 1; case '*': case '/': return 2; case '^': return 3; } return 0; // orice alt caracter } inline bool right_ass(char op) { return op == '^'; }
Adaptăm parse_climb() şi parse_primary() din [2], înlocuind ArTree cu std::string şi vizând în plus, operanzi literali (dar renunţând să mai semnalăm prin throw anumite erori, ca în [2]):
std::string Symbex::parse_climb(int level) { std::string tree = parse_primary(); // operand, sau expresie parantezată while(priority(look_ahead()) >= level) { // când urmează operator prioritar char op; infix >> op; int next_level = right_ass(op)? priority(op): priority(op) + 1; std::string opr; opr += op; tree = opr + "(" + tree + "," + parse_climb(next_level) + ")"; } return tree; } std::string Symbex::parse_primary() { char c; infix >> c; switch(c) { case '(': // începe o subexpresie parantezată { std::string tree = parse_climb(1); // analizează subexpresia char p; infix >> p; // sare peste ')' (final subexpresie) return tree; // sub-arborele subexpresiei parantezate } default: // operand numeric (prima cifră a sa), sau literă ("variabilă") { if(!(c>='0' && c <='9')) { // operand literal std::string tmp; tmp += c; return tmp; // return std::string(1, c); } else { infix.putback(c); // reînscrie cifra şi citeşte numărul double number; infix >> number; std::ostringstream tmp; tmp << number; return tmp.str(); } } } }
Având de combinat un char cu un string (în două locuri, mai sus) - am adoptat intuitiv o soluţie ca: std::string tmp; tmp += c; return tmp;; dar într-adevăr, soluţia "elegantă" return string(1, c); (şi tree = string(1, op) + "(" + tree + ... ) consumă un timp sensibil mai mare. Ar fi şi acest aspect, unul (dar cel mai mic…) dintre neajunsurile analizei la nivel de caracter (şi nu pe un "stream de tokeni") - când iată că trebuie să investigăm şi să decidem ce porţiune corespunde unui operand numeric, ce este operand literal, etc.
Obţinerea descrierii DOT a arborelui sintactic
Simplificăm funcţia to_DOT() din [2]: scriem rezultatul pe "dispozitivul standard de ieşire" (şi nu într-un fişier precizat, ca în [2]) - de aici, descrierea respectivă poate fi redirectată de pe linia de comandă (fie într-un fişier, fie ca "intrare" pentru altă comandă - de exemplu chiar pentru dot):
void Symbex::cout_DOT() { std::istringstream pref(prefix); // afişează forma prefixată parantezată (`dot` va ignora linia "#...") std::cout << "# " << *this << '\n'; std::cout << "graph G {\n"; std::cout << "node[shape=plaintext, fontsize=16]\n"; char c; int root = 1; while(pref >> c) { if(c>='0' && c <='9') { pref.putback(c); double number; pref >> number; std::cout << root << "[label=\"" << number << "\"]\n"; continue; } switch(c) { case '(': root <<= 1; std::cout << root/2 << "--" << root << '\n'; break; case ',': root += 1; std::cout << root/2 << "--" << root << '\n'; break; case ')': root >>= 1; break; default: // identificator de variabilă std::cout << root << "[label=\"" << c << "\"]\n"; break; } } std::cout << "}\n"; }
Desigur (în plus faţă de [2]), am considerat şi cazul operanzilor literali.
Concatenând toate secvenţele redate mai sus într-un fişier "symex.cpp" şi adăugând de exemplu:
int main(int argc, char** argv) { std::string ex = argv[1]; Symbex S(ex); S.set_prefix(); S.get_DOT(); }
putem compila şi executa programul, de exemplu cum se vede pe imaginea următoare:
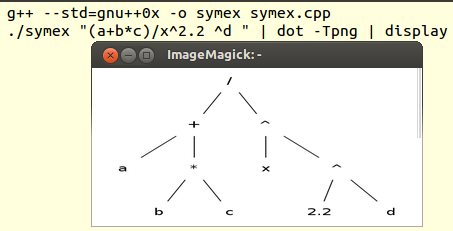
Am folosit operatorul | ("pipe"), conectând ieşirea programului (descrierea DOT a expresiei indicate ca argument pe linia de comandă) cu programul dot, iar răspunsul acestuia (fişierul grafic PNG corespunzător descrierii DOT) - cu programul display (din pachetul ImageMagick).
Desigur, invocând în modul cel mai simplu:
vb@vb:~$ ./symex "(a+b*c)/x^2.2 ^d " # /(+(a,*(b,c)),^(x,^(2.2,d)))
obţinem pe ecran linia-comentariu conţinând reprezentarea prefixată complet parantezată a expresiei indicate (urmată de descrierea DOT a arborelui sintactic al expresiei).
Observaţii finale
În cele de mai sus am urmărit (folosind şi C++11) scopuri practice - cum obţinem reprezentarea prefixată (complet parantezată) a unei expresii algebrice, împreună cu descrierea DOT a arborelui sintactic al acesteia; nu am vizat "analiza sintactică" în sine, ca tehnică sau metodologie - ci doar la nivel de algoritm, modelând direct (ca şi în [2]) metoda "precedence climbing".
Trebuie să constatăm că realizând analiza sintactică a expresiei în modul cel mai direct, anume la nivel de caracter - rezultă (cum am evidenţiat în câteva locuri) diverse scăpări de cazuri şi unele duplicări inerente de cod (de exemplu, pentru extragerea unui operand numeric).
Trebuie să recunoaştem până la urmă: chiar şi pentru expresii algebrice - constituind totuşi un limbaj mai simplu - este recomandabil să organizăm analiza sintactică după metodologia specifică limbajelor de programare. Pe scurt (a vedea însă [3], secţiunea Writing a parser) - codul trebuie împărţit în trei funcţii (obiecte, sau module): parse, TokenStream şi InputStream, fiecare asumându-şi anumite funcţii interne utilitare; funcţia "principală" parse nu operează pe un simplu şir de caractere, ci pe o secvenţă de "tokeni" - separând astfel codul care face efectiv parsarea, de codul specific pentru "analizorul lexical" TokenStream, care (deservit de "scanner"-ul InputStream) decide ce e operator, ce e număr/variabilă şi cum/când se avansează.
Compunerea parse(TokenStream(InputStream( produce arborele sintactic al expresiei (sau al codului-sursă) - pe baza căruia compilatorul (sau un interpretor, sau un translator) produce apoi codul-maşină necesar pentru evaluarea sau translatarea expresiei, sau pentru execuţia programului parsat astfel." ... ")))
Arborele sintactic poate fi serializat în diverse moduri; reprezentarea ca "listă parantezată" sau S-expresie ("symbolic expression") - de care ţine şi "formatul prefixat complet parantezat" vizat mai sus - este specific limbajelor Lisp (şi limbajului Prolog - a vedea metafora write_canonical), limbaje în care textul-sursă de program are aceeaşi structură ca şi arborele sintactic al său.
vezi Cărţile mele (de programare)