Statistici pe probe şi grupe de medii, folosind R
Din [1] avem setul de date evna - de la "examenul de evaluare naţională" din 2015; variabila sa "Media" (pentru media finală a candidatului) este o structură de date "factor":
> str(evna$Media) Factor w/ 705 levels "","1","10","1.02",..: 135 313 261 467 419 367 303 513 593 189 ... > levels(evna$Media) [1] "" "1" "10" "1.02" "1.05" "1.06" "1.07" "1.1" [9] "1.12" "1.15" "1.16" "1.17" "1.18" "1.2" "1.21" "1.22" ... ... ... [697] "9.87" "9.88" "9.9" "9.91" "9.92" "9.93" "9.95" "9.97" [705] "Absent"
Avem deci 703 categorii de medii propriu-zise: 1, 1.02, 1.05, ..., 9.95, 9.97, 10 (şi deducem că nici un elev n-a avut media 1.03 de exemplu, sau 9.98, etc.) plus categoriile "" şi "Absent". În [1] ne-am folosit de nivelul "Absent" al acestui factor pentru o statistică a prezenţei la examen; acum (pentru "partea a III-a") vom viza mediile propriu-zise.
Putem obţine imediat nişte statistici simple, la nivelul contorizării:
> table(evna$Media) # contorizează nivelele factorului indicat 1 10 1.02 1.05 1.06 1.07 1.1 1.12 1.15 1.16 1 174 457 5 19 1 13 29 22 28 2 ... ... ... 9.83 9.85 9.86 9.87 9.88 9.9 9.91 9.92 9.93 9.95 9.97 4 523 7 302 2 477 2 165 2 225 62 Absent 4829 > summary(evna$Media) # pentru 'factor' produce numai contorizare (descrescător) Absent 9.5 9.35 9.55 9.65 9.15 9.25 9.1 9 9.45 4829 926 858 826 825 802 796 794 789 787 ... ... ... 7.8 8.97 8.92 7.7 8.37 6.95 7.45 6.9 7.6 (Other) 618 618 616 615 615 614 614 612 612 91664
Constatăm astfel că au fost 457 note de 10, două note de 9.91, ş.a.m.d.; 9.5 este nota care apare cel mai frecvent (la 926 de elevi), apoi 9.35 şi 9.55 (la 858 şi respectiv 826 elevi), ş.a.m.d. în timp ce un număr de 91664 elevi au medii sub 7.60.
Pentru statistici pe probe şi grupe de medii (poate şi pe judeţe), dintre cele 21 de coloane din evna ne vor interesa numai "Cod_siiir", cele trei coloane "Nota_finala_" şi "Media". Salvăm într-un fişier structura de date evna şi "rezumăm" obiectul respectiv la coloanele menţionate, folosind subset(); instituim denumiri mai simple pentru coloane şi în final, forţăm tipul "numeric" pentru variabila "media":
Următoarea funcţie foloseşte funcţia cut() pentru a clasifica mediile unei probe în intervalele [1, 5), [5, 6), ..., [9, 10] şi apoi foloseşte funcţiile aggregate() şi length() pentru a constitui un obiect "data.frame" care conţine pentru fiecare interval numărul de medii la proba respectivă, cuprinse în acel interval:
De exemplu, apelând pentru coloana evna$Lbm (pe care avem foarte multe valori "NA"):
> str(classify(4)) # coloana 4 din 'evna' corespunde mediilor la "Limba maternă" (evna$Lbm) 'data.frame': 6 obs. of 2 variables: $ lim : Factor w/ 6 levels "[1,5)","[5,6)",..: 1 2 3 4 5 6 $ evna[, k]: int 561 905 1377 1978 2511 2025 # valorile "NA" (not available) sunt ignorate
Precizăm că specificaţia "right=FALSE" din apelul de mai sus al funcţiei cut() impune intervale de forma [a, b) - inclusiv a, exclusiv b - încât o prevedere ca "breaks=c(1, 5:10)" ar fi creat intervalele corecte [1,5) (pentru categoria de "respins"), [5,6), ..., [8,9) şi apoi intervalul [9,10), care ar fi greşit pentru că nu ar cuprinde şi elevii cu media 10.
Putem folosi funcţia lapply() pentru a aplica "deodată" pe toate cele patru coloane de medii, funcţia de clasificare introdusă mai sus:
> medii <- data.frame(lapply(2:5, classify)) # 4 coloane identice; nume incomode #> medii # lim evna...k. lim.1 evna...k..1 lim.2 evna...k..2 lim.3 evna...k..3 #1 [1,5) 23069 [1,5) 41937 [1,5) 561 [1,5) 32736 # ...
Dar astfel, coloanele de rang impar sunt identice (indicând fiecare, intervalele de medii considerate în funcţia classify()), iar numele de coloane care au rezultat automat sunt incomod de utilizat. Eliminăm coloanele aflate "în plus" şi apoi (folosind funcţia names()) schimbăm numele respective:
> medii <- medii[-c(3, 5, 7)] # '-' elimină coloanele 3, 5, 7 > names(medii)[2:5] <- names(evna)[2:5] # numeşte coloanele 2..5 la fel ca în 'evna' #> medii # lim Rom Mat Lbm media #1 [1,5) 23069 41937 561 32736 #2 [5,6) 21982 25976 905 22683 #3 [6,7) 23163 19550 1377 24570 #4 [7,8) 28871 18151 1978 24644 #5 [8,9) 33476 21362 2511 27312 #6 [9,10] 28467 31614 2025 26643
Putem aplica funcţia sum() coloanelor 2..5 din structura "medii", pentru ca apoi să împărţim coloanele prin sumele corespunzătoare şi să obţinem rezultatele în formă procentuală:
> sume <- lapply(medii[2:5], sum) # totalul de medii pe fiecare probă > medii[2:5] <- round(medii[2:5]/sume, 4)*100 # proporţia (%) grupei în totalul probei #> medii # (în procente) # lim Rom Mat Lbm media #1 [1,5) 14.51 26.44 6.00 20.64 #2 [5,6) 13.82 16.38 9.67 14.30 #3 [6,7) 14.57 12.33 14.72 15.49 #4 [7,8) 18.15 11.45 21.14 15.54 #5 [8,9) 21.05 13.47 26.84 17.22 #6 [9,10] 17.90 19.93 21.64 16.80
La o primă vedere, s-ar părea că elevii care au avut şi proba de "Limbă maternă" au fost avantajaţi (?): numai 6% dintre mediile acestei probe sunt sub 5 şi aproape 70% sunt între 7 şi 10. Este drept că Rom, Mat şi media contorizează şi elevii din Lbm - dar chiar şi cu aceştia, procentul celor cu media peste 7 abia ajunge 45% la Mat şi 57% la Rom. Desigur că până la urmă, bănuiala strecurată mai sus trebuie verificată prin analiza separată a rezultatelor acelora care au susţinut exact trei probe.
Mai întâi însă, iată o reprezentare vizuală (mai mult sau mai puţin reuşită) a datelor de mai sus:
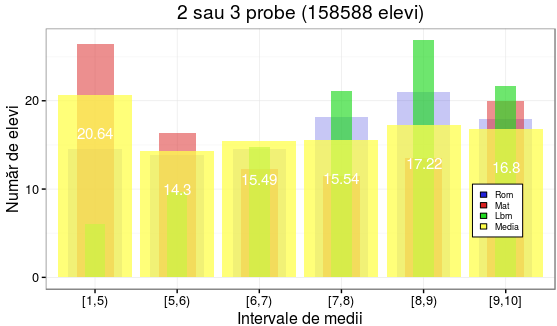
Am folosit pachetul ggplot2. Cele patru coloane de date aferente unui aceluiaşi interval de medii sunt reprezentate prin bare de lăţimi diferite, colorate diferit, cu nivele de transparenţă diferite (implicând respectiv atributele "width", "fill" şi "alpha", în funcţiile geom_bar()):
În loc să fie alăturate, sau stivuite una la capătul celeilalte - barele noastre se suprapun (ceea ce este probabil, un aspect original); dar pentru culoare şi transparenţă ar fi de căutat valori mai bune…
Vrem tabele de medii şi pentru anumite subseturi - de exemplu, pentru elevii care au susţinut şi proba de limbă maternă, sau pentru cei care nu au avut şi această probă, sau pentru elevii dintr-un judeţ sau altul. Rescriem funcţia "classify()", înglobând şi comenzile date separat mai sus, astfel:
Clasificarea pe medii vizează elevii prezenţi la proba respectivă, încât pentru a completa informaţiile, classify() returnează o listă care pe lângă tabelul mediilor conţine şi numărul de elevi corespunzător.
Acum obţinem clasificarea pe medii a elevilor care au avut şi a treia probă astfel:
Pentru o reprezentare grafică putem folosi ggplot(medii.lbm[[1]]) cu aceleaşi patru funcţii geom_bar() redate mai sus, modificând doar atributul "title" din funcţia labs() şi poziţia legendei:
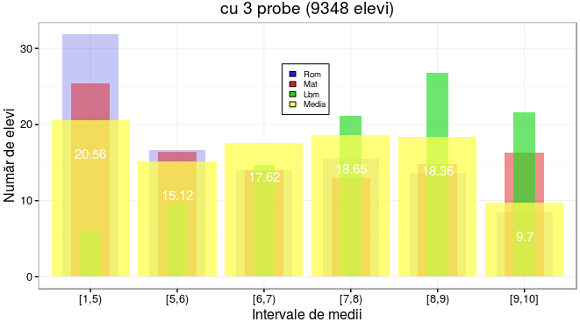
În legătură cu bănuiala avansată mai sus, am putea zice acum, comparând coloanele "Rom" din cele două tabele de clasificare date mai sus (pentru întregul set de date ale examenului şi respectiv, pentru subsetul aferent celor care au susţinut şi proba de limbă maternă), că de fapt cei care au avut şi proba de limbă maternă au fost dezavantajaţi prin faptul că au trebuit să susţină şi proba de limbă română: într-adevăr, la "Rom" au căzut sub media 5 aproape o treime (faţă de 14% pentru întregul set de date) şi au primit medii în intervalul [8, 10] numai 22% (faţă de 39%, pentru întregul set).
În schimb, coloanele "Mat" din cele două cazuri sunt vizibil apropiate, iar valorile din coloana finală "media" sunt vizibil depărtate de "Lbm" (faţă de celelalte două coloane). Am zice în consecinţă, că examenul poate fi rezumat fără pierderi la o singură probă - aceea de matematică…
Desigur că mai sus am exagerat: perturbaţiile aduse rezultatelor de către proba "Lbm" au ajuns să fie vizibile numai fiindcă am operat ca la oricare probă, cu procente faţă de participanţii la probă - fără a ţine seama de faptul că proporţia celor care au susţinut proba de limbă maternă este foarte mică, în ansamblul participanţilor; şi tocmai faptul că această proporţie este neglijabilă, anulează bănuielile de "avantajat" şi "dezavantajat" (mascând defectul existenţei acestei probe).
Cum arată clasificarea pe medii pentru un judeţ sau altul? Mai întâi să determinăm media examenului pentru fiecare judeţ şi să ierarhizăm judeţele după medie:
Coloana jud indică judeţele în aceeaşi ordine ca în structura de date jud.csp din [1], astfel că putem înlocui imediat codurile prin chiar denumirile judeţelor:
Ne-a rămas să ordonăm descrescător după a doua coloană (rotunjită în prealabil, cu trei zecimale):
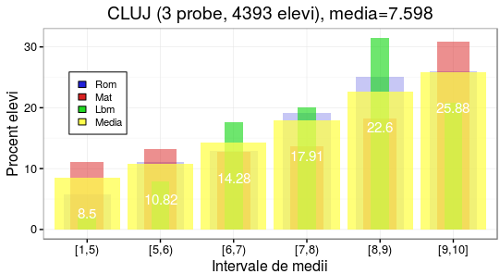
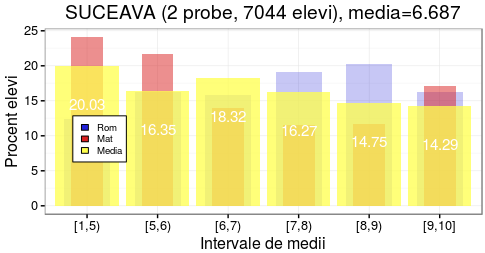
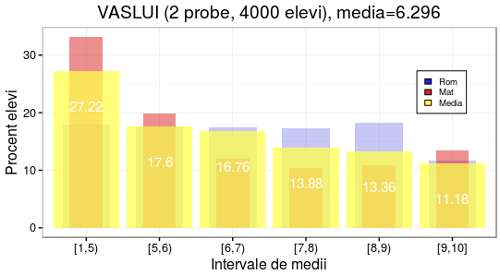
Am redat mai sus tabelul de judeţe şi medii, în ordinea descendentă a mediilor şi în dreapta acestuia am poziţionat reprezentările clasificării după medii pentru trei judeţe: unul de la începutul listei (Cluj, 7.598), unul mai dinspre sfârşit (Vaslui, 6.296) şi unul de pe mediana listei (Suceava, 6.687). Pentru judeţele din capul listei, curba procentelor de elevi este pronunţat crescătoare în raport cu intervalele succesive de medii (de la sub 10% pentru medii [1, 5) până pe la 25% pentru [9, 10]); pe la mijlocul listei, această curbă tinde să-şi niveleze valorile şi începe să fie uşor descrescătoare, iar spre capătul de jos al listei curba respectivă devine pronunţat descrescătoare (de la valori peste 25% pentru medii [1, 5) până la valori de ordinul 10% pentru capătul de sus al mediilor, [9, 10]).
Pentru a obţine clasificările pe medii pentru judeţele respective am folosit desigur funcţia classify(), dar a trebuit să ţinem cont de faptul că aceasta fusese creată pentru cazul a trei probe (erau vizate în mod explicit coloanele 2..5 ale subsetului respectiv); pentru un judeţ în care s-au susţinut numai cele două probe standard, toate valorile din coloana 'Lbm' ar fi "NA" şi atunci, funcţia aggregate() invocată în interiorul lui classify() s-ar rezuma într-o eroare de execuţie:
Pentru redresare putem schimba coloana 'Lbm' de exemplu pe valoarea 1 (în loc de 'NA'), astfel încât aggregate() să nu mai ducă la eroare; iar după ce se încheie classify(), eliminăm coloana 'Lbm':
sv$Lbm <- 1 # temporar (fictiv), toţi elevii au Lbm=1 (deci pot fi clasificaţi) medii.sv <- classify(sv) medii.sv[[1]]$Lbm <- NULL; medii.sv[[2]]$Lbm <- NULL # anulăm proba fictivă 'Lbm' medii.sv[[1]] ### lim Rom Mat media ###1 [1,5) 12.35 24.12 20.03 ###2 [5,6) 16.25 21.66 16.35 ###3 [6,7) 15.77 13.95 18.32 ###4 [7,8) 19.08 11.53 16.27 ###5 [8,9) 20.26 11.63 14.75 ###6 [9,10] 16.28 17.11 14.29
Dincolo de scopul nostru de a exemplifica (pe date reale) folosirea limbajului şi mediului R - am avea de sesizat pe baza situaţiilor statistice obţinute mai sus, că "învăţământul obligatoriu" se prezintă rău (cu rezultate de la mediocru spre submediocru).
vezi Cărţile mele (de programare)