Tabelul unic versus "bază de date" (între practică şi teorie)
Programa şcolară distinge "teorie" de "practică", indicând 1 oră teorie şi 2 ore laborator; ruperea este iminentă… Manualele propun mereu să se scrie un program care, vizând cam imprudent scrierea, în loc de construirea (realizarea) programului. Rezultanta în practica obişnuită a adoptării unor astfel de portiţe de evitare a eforturilor de corelare, constă în programe monolitice: o singură funcţie - void main() - sau în orice caz, un singur fişier (nume.CPP) şi un singur "tabel" - anulând astfel, orice "teorie" şi orice legătură cu realitatea.
Nu-i vorba numai de "teorie", după cum nu-i vorba numai de "scriere". E vorba şi de formarea gustului specific, pentru autodocumentare. Manualele noastre au rămas cantonate pe produsele exclusiv comerciale, exclusiv din gama Windows-ului, vizând cu precădere dacă nu exclusiv, maniera point-and-click; nu te pregătesc prin nimica, în vederea abordării unui nou sistem sau produs. Practic, în laborator se vizează nu "programarea" (care chipurile, ţine de "teorie") cât scrierea programelor - se folosesc "medii de dezvoltare" IDE, dar ele sunt pur şi simplu reduse la rolul de editor; programul nici nu există, decât prin intermediul IDE, ca text-sursă.
În informatică - măcar pentru ceea ce ţine de "programare" - este valabil principiul şahist: teoria este practica maeştrilor. Odată înţeleasă, "teoria" ajunge să ţină pur şi simplu de bunul-simţ; nu sunt necesare citări (şi nici… dictări) de formulări "teoretice" abstracte, pentru a şi folosi teoria în practica obişnuită.
Vom viza aici (la nivelul bunului-simţ) câteva aspecte de practică obişnuită, legate de "baze de date" şi de teoria normalizării; documentăm extensia PHP mysqli (pentru lucrul cu baze de date MySQL dintr-un program PHP5) şi relevăm conceptul general Model-View-Controller pe care se bazează diverse framework-uri larg utilizate pentru dezvoltarea de aplicaţii Web care angajează baze de date.
Sindromul tabelului unic
Un exemplu real (dintre cele mai la îndemână) este Declaraţia privind evidenţa nominală a asiguraţilor şi a obligaţiilor de plată către bugetul asigurărilor sociale, pe care fiecare angajator trebuie să o transmită lunar către Casa Teritorială de Pensii.
Fiecare angajator trebuie să depună lunar Anexa 1.1 şi Anexa 1.2, atât în "format electronic", cât şi "pe suport de hârtie (listate la calculator, semnate şi ştampilate)". Desigur, instituţiile respective au realizat şi oferă generos un "program pentru angajatori", prin care aceştia pot să introducă datele respective, să le verifice, să salveze pe dischetă şi să listeze cele două declaraţii; programul este realizat desigur, folosind VFP (cu toate costurile de licenţiere şi restricţiile de operare şi utilizare specifice platformei comerciale Microsoft Windows).
Datele respective trebuie introduse într-un tabel "de tip DBF sau TXT (înregistrări de lungime fixă)", având următoarea structură de câmpuri (coloane):
AN, LN, CF, RJ, RN, RA, NUME, CNP, CM, CV, PE, SOM, TT, NN, DD, SS, PP, TV, TVN, TVD, TVS, CASAT, CASTOT, BASS, CNPA, NORMA, TIPD, TIPR, NUMEANT, CNPANT, PPS, PPD, PPBASS, PPFAAMBP, FAAMBP, PPCAS, IND_CS, NRZ_CFP
pentru "Anexa 1.1" şi respectiv
AN, LN, DCZZ, DCLL, DCAA, DEN, CF, RJ, RN, RA, NRM, FS, FSN, FSD, FSS, CASS, CASAN, BASS, CASS145, CASVIR, NRF, B1, F1, C1, B2, F2, C2, B3, F3, C3, B4, F4, C4, CNPA, CAAMBP, A_LOCA, A_STR, A_NR, A_BL, A_SC, A_ET, A_AP, TELEFON, A_JUD, A_SECT, E_MAIL, TIPD, NRCAZB, NRCAZA, NRCAZP, NRCAZL, NRCAZI, NRCAZC, NRCAZD, NRCAZR, NRPPB, NRPPA, NRPPP, NRPPL, NRPPI, NRPPC, NRPPR, SUMAB, SUMAA, SUMAP, SUMAL, SUMAI, SUMAC, SUMAD, SUMAR, CODCAEN, TPP, PCAMBP, TPPA, CASS145A, PFAAMBP, NRCAZIT, NRCAZTT, NRCAZRT, NRCAZCC, NRPPIT, NRPPTT, NRPPRT, NRPPCC, SUMAIT, SUMATT, SUMART, SUMACC, FAMBPV, DATORAT, NRIG, DATAIG, NUME, PRENUME, DATACOMPL, FUNCTIA, TSUMAIT, TSUMATT, TSUMART, TSUMACC, TBASS, TBASS_N, TBASS_D, TBASS_S, CASAN_CM, CONTR_CM
pentru "Anexa 1.2".
Am redat aici numai câmpurile actuale. Se foloseşte o "bază de date", că FoxPro este totuşi un "RDBMS" (sau, numai la "teorie"?); dacă nu-l foloseşti ca atare - ca RDBMS - atunci de ce să-l mai foloseşti? poate fi suficient un editor de text, sau poftim - Word, sau hai să zicem - Excel. "Baza de date" angajată de programul instituţiei conţine încă o serie de alte coloane care "există pentru compatibilitate cu versiunea anterioară a programului" (citez mereu din documentaţia programului): din 2000 încoace, "baza de date" şi-a tot schimbat structura (de fapt, s-au tot adăugat coloane noi, făra a elimina coloanele devenite inutile), iar programul a trebuit mereu să fie actualizat corespunzător.
Ar fi de făcut câteva obiecţii - în fond, reflectări la nivelul bunului-simţ a unor principii de normalizare studiate desigur, la "teorie" (a vedea programa sau manualul, pentru "1 oră teorie").
Să observăm întâi că s-au ales denumiri criptice, pentru numeroase câmpuri; recomandabil (la "teorie", desigur) este ca identificatorii angajaţi să fie cât mai sugestivi, pentru ca programul să poată fi mai uşor întreţinut în timp.
RJ, RN, RA înregistrează primele 3, respectiv caracterele 4-8 şi respectiv ultimele 4 caractere din "numărul de înmatriculare în registrul comerţului al angajatorului"; dar RJ, RN, RA se deduc evident dintr-o aceeaşi entitate (numărul de înmatriculare). În schimb, Nume nu este descompus în "nume" şi "prenume", cum s-ar cuveni totdeauna pentru a evita în modul cel mai simplu, confuziile.
În ceea ce priveşte valorile Nume ar mai fi de contestat această pretenţie (explicitată de fapt de majoritatea instituţiilor noastre): să se folosească numai majuscule, fără "diacritice"... Se cere să se scrie nu Tănasă Mihăiţă cum este corect, ci TANASA MIHAITA (dar… cine contestă?! - probabil că George Pruteanu n-a avut ocazia de a observa şi această încălcare penibilă şi forţată, a legilor limbii române).
Dar ce caută "numărul de înmatriculare al angajatorului" în tabelul angajaţilor -consecinţa fiind că la toţi angajaţii va trebui înscris numărul de înmatriculare (şi încă separându-l pe cele trei componente); este drept că aceasta se poate face printr-o singură instrucţiune "replace all", dar RJ, RN, RA, CF ("cod fiscal angajator") sunt date specifice angajatorului (nu angajatului) şi ar trebui să fie suficient că ele figurează deja în "Anexa 1.2" (alături de "adresa angajatorului", care şi ea este descompusă băbeşte: A_LOCA, A_STR, A_NR, A_BL, A_SC, A_ET, A_AP, etc.).
Termenii B1, F1, C1, B2, F2, C2, B3, F3, C3, B4, F4, C4 se referă la bănci (nume B, filială F, cont C); dar angajatorul poate fi în relaţie şi cu alte bănci decât cele patru care au fost astfel prevăzute, în al doilea tabel (după cum, poate fi în relaţie numai cu una - caz în care câmpurile prevăzute pentru încă trei bănci devin inutile). Şi în fond, băncile ţin de… bănci, nu de angajator şi doar, există o relaţie între una şi alta (un angajator are conturi la diverse bănci, respectiv o bancă ţine conturi la mai mulţi angajatori).
Multe câmpuri din cele două tabele sunt "câmpuri calculate", adică derivă prin formule simple din alte câmpuri existente; de exemplu, CASAT care "conţine contribuţia de asigurări sociale reţinută de la asigurat" se determină prin CASAT = ROUND((TV + BASS) * cota CAS asigurat /100,0), unde "cota CAS" este unică pe ţară, iar TV şi BASS sunt câmpuri existente în tabel.
În plus, al doilea tabel (care conţine o singură înregistrare) poate fi dedus (cu excepţia a câtorva câmpuri) din primul tabel, prin obişnuita însumare a valorilor din diverse coloane ale acestuia.
Este evident că tabelele DBF descrise mai sus nu au a face cu "bază de date". VFP a fost implicat din cu totul alte considerente, decât că ar fi un RDBMS; la fel de bine - şi de fapt, mult mai bine! - se putea implica Excel, pentru a obţine tabelul respectiv (dar şi în acest caz avem "teorie": un "tabel Excel" poate fi constituit din mai multe "sheet"-uri, separând şi relaţionând într-o anumită măsură entităţile respective).
De la date şi cerinţe la bază de date
Se tot cer tabele; dacă motivele sunt doar de natură formală (în vederea aprobării, semnării, ştampilării), atunci este absolut suficient să le produci funcţionăreşte, folosind Microsoft Word-ul, sau Excel. Are sens să implici o bază de date numai dacă există anumite cerinţe (neimediate) faţă de datele respective şi evident, dacă există date… (nu-i cazul să implici baze de date, dacă-i vorba de un tablou de vreo 30 de elevi!).
Aici încercăm să imaginăm un context cât mai familiar (ţinând de mediul şcolar), care să implice în mod firesc o bază de date. Anume, alegem lucrările de atestat ale elevilor; acestea pot interesa din diverse puncte de vedere: pe laborant îl va interesa ce soft-uri trebuie să preinstaleze în sala în care se vor prezenta lucrările; elevii din seriile următoare celei curente vor dori poate să vadă cam ce teme au tratat cei dinaintea lor (şi-i va interesa nu doar "titlul", dar şi un sumar consistent); inspectorul şcolar va avea poate ambiţia de a constata frecvenţa temelor abordate de-a lungul anilor, pe profesori sau pe şcoli; etc.
În cursul anului pot apărea diverse probleme: un elev vrea să-şi schimbe lucrarea cu care a fost deja înregistrat, sau vrea să modifice sumarul, sau îşi aminteşte că va avea nevoie şi de alt soft decât cele înregistrate, sau a apărut necesitatea înlocuirii unui profesor îndrumător cu un altul; profesorii vor vrea să-şi înregistreze elevii şi lucrările acestora, etc.
Ca de obicei - înainte de a începe să scrii vreun program (şi înainte de a deschide vreun meniu "Table"), trebuie să vezi (şi să judeci) cam ce date trebuie să modelezi, cam ce corelaţii există între ele, cam ce operaţii vor fi de făcut asupra lor şi cam care vor fi cererile de satisfăcut privind datele respective. Păi cum altfel? — a construi un program este analog de exemplu, cu a construi o casă; înainte de a te apuca de clădit, trebuie să faci o listă de materiale şi de instrumente necesare, o planificare a operaţiilor de efectuat, trebuie să cauţi echipele pe care să le angajezi pentru realizarea acelor operaţii, trebuie să constitui o anumită documentaţie prealabilă, inclusiv o schiţă a viitorului edificiu etc.
Plecând de la interesele existente faţă de atestate (cum am evocat mai sus, din partea laborantului, a elevilor dintr-o serie sau alta, a inspectorului şcolar, etc.), putem stabili cam care ar fi datele pe care trebuie să le cuprindem şi să le organizăm în baza noastră de date.
Într-o primă organizare ierarhică, datele vizează localităţi (că pe inspector nu-l interesează o singură şcoală, ci toate şcolile dintr-o anumită regiune geografică), şcolile aparţinătoare acestora, clasele terminale existente în acele şcoli, profesorii îndrumători, elevii care susţin atestatul, lucrările de atestat, soft-urile folosite.
Între aceste entităţi există anumite relaţii: o localitate are mai multe şcoli, o şcoală are an de an, mai multe clase terminale, o lucrare foloseşte mai multe soft-uri şi un acelaşi soft poate fi utilizat de mai multe lucrări, etc.
Trecem acum la descrierea amănunţită a datelor, grupându-le desigur în tabele. În toate aceste tabele, desemnăm prin id "cheia primară" (şi prin id_... o "cheie străină"). Orice tabel trebuie să aibă un atribut (se zice şi coloană, sau câmp) calificat drept Primary Key, ale cărui valori sunt unice în acel tabel (astfel că oricare tuplu din tabel - se mai zice înregistrare, sau "rând" de date - poate fi identificat prin valoarea conţinută în câmpul PK); în general, odată calificat drept "PK" - valorile acelui câmp vor fi gestionate în mod automat de către DBMS.
Următoarele tabele conţin date care vor trebui referite din înregistrări ale altor tabele:
localitate id nume
serie id an
soft id nume
Evident (dar… mai bine să precizăm) - în contextul de faţă nu ar avea sens să includem în localitate şi valori precum "primarul localităţii"; în tabelul serie nu are sens să înscriem şi diriginţii, ş.a.m.d.
Este însă de observat un posibil "defect": valorile nume-lui vor fi unice (nu vom înregistra de două ori, un acelaşi nume) şi la fel, valorile an; păi atunci, de ce să nu folosim drept PK chiar nume şi respectiv an? Se poate aceasta, fiindcă DBMS menţine un fişier-index separat de fişierul de date; dacă nume este declarat ca PK, atunci (în principiu) valorile respective (care sunt şiruri de caractere) vor fi scurtate la o anumită lungime (suficientă pentru a asigura unicitatea) şi codul respectiv va fi înregistrat ca index al înregistrării.
Dar preferăm totuşi folosirea unitară (pentru fiecare tabel) a unui câmp id explicit (analog obişnuitului "NrCrt"), având valori numerice (acestea şi sunt gestionate mai rapid decât indecşii nenumerici, iar asocierea prin FK cu alte tabele este mai simplă).
Următorul tabel conţine o "cheie străină" (Foreign Key, FK):
scoala id nume adresa id_localitate
Înregistrările din acest tabel care au o aceeaşi valoare id_localitate, reprezintă şcoli dintr-o aceeaşi localitate - anume cea pentru care localitate.id = scoala.id_localitate. Numele localităţii este înregistrat o singură dată, apoi când este necesar este referit prin FK; se uşurează astfel introducerea sau editarea datelor şi se evită greşelile datorate editării multiple (iar DBMS-urile oferă mecanisme comode pentru "reunirea" sau "alipirea" ulterioară a datelor din tabelele relaţionate astfel).
Următoarele două tabele vor conţine datele necesare pentru profesorii-îndrumători şi pentru clase:
prof id nume pren id_scoala
clasa id id_scoala id_serie nume efectiv
O clasă aparţine unei anumite şcoli, unei anumite serii anuale şi are un anumit număr de elevi; întrucât susţinerea atestatului nu este obligatorie, poate fi interesant să se vadă şi să se compare proporţiile de participare la atestat (de aceea am inclus câmpul efectiv).
În privinţa modelării pentru tabelele (sau relaţiile) atestat şi elev putem avea o dilemă. Fiecare elev are o singură lucrare şi fiecare lucrare aparţine unui singur elev (relaţie "one-to-one"); dar fiecare lucrare are un profesor-îndrumător (presupunem firesc că unul singur) şi acesta îndrumă mai multe lucrări (relaţie "one-to-many"). În general sunt mai convenabile relaţiile "1-n", încât propunem această organizare:
atestat id titlu sumar id_prof
elev id nume pren id_clasa id_atestat
Alegerea între a modela "1-1" şi respectiv "1-n", decurge de obicei gândindu-ne la ce s-ar întâmpla când ar apărea necesitatea de a şterge vreo înregistrare. În alegerea făcută aici, dacă s-ar şterge o înregistrare din elev atunci datele lucrării corespunzătoare lui în atestat, n-ar fi afectate (simulând situaţia - care poate fi reală - că lucrarea este propusă dar n-a fost luată de nici un elev); în schimb, dacă am fi preferat să legăm "1-1" aceste tabele (înlocuind id_prof cu id_elev, în atestat), atunci ştergerea elevului atrage de obicei şi ştergerea lucrării (automat sau nu, depinzând şi de maniera în care se foloseşte DBMS).
Să observăm că am preconizat un tabel soft, dar în atestat n-am inclus şi o referire la soft-ul folosit. Motivul este că între aceste entităţi avem în mod firesc o relaţie "many-to-many" (o lucrare foloseşte mai multe soft-uri; un acelaşi soft este angajat în mai multe lucrări); avem nevoie deci, de o "punte" între aceste două tablouri:
soft_atestat id id_atestat id_soft
De exemplu, ştiind că "Firefox" este înregistrat în soft, având acolo id = 5, putem afla lucrările care îl angajează astfel: SELECT * FROM atestat, soft, soft_atestat WHERE soft_atestat.id_soft = 5 AND soft_atestat.id_atestat = atestat.id (sunt posibile şi alte soluţii).
Imaginea următoare sintetizează cele preconizate mai sus (este ceea ce se cheamă o "entity relationship diagram", ERM). Am schimbat însă termenul atestat cu lucrare (fără a fi necesar, rezervăm totuşi atestat pentru baza de date constituită de tabelele respective).
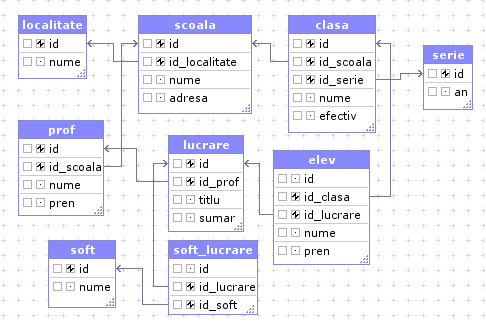
Această diagramă a fost obţinută (în browser, după crearea bazei de date în MySQL) printr-un program (PHP, javaScript) din 2003, oferit de către Dynarch.com (parcă nu apăruseră, în 2003-2004, "ER diagramming tools", ERM - în orice caz, nu pentru browser).
Crearea bazei de date 'atestat'
Creem întâi (folosind desigur, un editor de text) următorul fişier atestat.sql:
create database if not exists atestat; use atestat; drop table if exists localitate, serie, soft, scoala, prof, clasa, lucrare, elev, soft_lucrare; create table localitate( id int auto_increment primary key, nume varchar(16) unique /* valori unice ('Iaşi' apare cel mult o dată) */ ); create table serie( id int auto_increment primary key, an year(4) unique ); create table soft( id int auto_increment primary key, nume varchar(32) unique ); create table scoala( id int auto_increment primary key, id_localitate int, /* "Foreign Key": valori 'id' din tabelul 'localitate' */ nume varchar(32), adresa varchar(64) ); create table prof( id int auto_increment primary key, id_scoala int, nume varchar(16), pren varchar(16) ); create table clasa( id int auto_increment primary key, id_scoala int, id_serie int, nume varchar(8), /* de exemplu, 'A' sau 'XII A' */ efectiv tinyint /* câţi elevi are clasa */ ); create table lucrare( id int auto_increment primary key, id_prof int, titlu varchar(128), sumar text(3000) ); create table elev( id int auto_increment primary key, id_clasa int, id_lucrare int, nume varchar(16), pren varchar(16) ); create table soft_lucrare( /* many-to-many între 'lucrare' şi 'soft' */ id int auto_increment primary key, id_lucrare int, id_soft int );
Pentru ca MySQL să creeze toate fişierele aferente (presupunând desigur, că serverul MySQL a fost startat), va fi suficientă următoarea comandă:
vb@localhost:~/testphp$ mysql < atestat.sql
După caz, comanda trebuie eventual completată (prin opţiunile -hhost, -u, -p): mysql -u user -ppassword. Putem apoi să
lansăm interpretorul mysql, prin comanda vb@localhost:~/testphp$ mysql atestat ("deschizând" şi baza de date tocmai creată).
Câteva comenzi MySQL de informare (autodocumentare)
Precizăm că utilizatorii de Windows pot să-şi instaleze un server Apache, MySQL şi PHP (plus Perl) folosind XAMPP. Ilustrăm aici câteva tipuri de comenzi informative simple, utile în diverse împrejurări ale lucrului cu MySQL: help, show, describe.
mysql> help 'contents'; You asked for help about help category: "Contents" For more information, type 'help <item>', where <item> is one of the following categories: Account Management Administration Compound Statements Data Definition Data Manipulation Data Types Functions Functions and Modifiers for Use with GROUP BY Geographic Features Language Structure Table Maintenance Transactions User-Defined Functions Utility
MySQL Documentation (secţiunea "MySQL Help Tables") oferă fişierul fill_help_tables-5.0.sql, care defineşte tabelele help_topic, help_category, help_keyword, help_relation (permiţând eventual, actualizarea datelor din baza de date mysql, creată de obicei de la instalarea MySQL). Aceste tabele înregistrează informaţii ajutătoare, grupate (sau relaţionate) pe categorii, subiecte şi cuvinte cheie.
vb@localhost:~/testphp$ mysql mysql ERROR 1044 (42000): Access denied for user 'vb'@'localhost' to database 'mysql' vb@localhost:~/testphp$ mysql -u root -pRootPassword mysql mysql> show tables; +---------------------------+ | Tables_in_mysql | +---------------------------+ | columns_priv | | db | | func | | help_category | | help_keyword | | help_relation | | help_topic | ............. | user | +---------------------------+ 17 rows in set (0.01 sec)
mysql> describe help_topic; +------------------+----------------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +------------------+----------------------+------+-----+---------+-------+ | help_topic_id | int(10) unsigned | NO | PRI | NULL | | | name | char(64) | NO | UNI | NULL | | | help_category_id | smallint(5) unsigned | NO | | NULL | | | description | text | NO | | NULL | | | example | text | NO | | NULL | | | url | char(128) | NO | | NULL | | +------------------+----------------------+------+-----+---------+-------+ 6 rows in set (0.00 sec)
mysql> show create table help_topic; +------------+--------------------------------------------------------------+ | Table | Create Table | +------------+--------------------------------------------------------------+ | help_topic | CREATE TABLE `help_topic` ( | | | `help_topic_id` int(10) unsigned NOT NULL, | | | `name` char(64) NOT NULL, | | | `help_category_id` smallint(5) unsigned NOT NULL, | | | `description` text NOT NULL, | | | `example` text NOT NULL, | | | `url` char(128) NOT NULL, | | | PRIMARY KEY (`help_topic_id`), | | | UNIQUE KEY `name` (`name`) | | | ) ENGINE=MyISAM DEFAULT CHARSET=utf8 COMMENT='help topics' | +------------+--------------------------------------------------------------+ 1 row in set (0.00 sec)
Am menţionat aici aceste tabele help_..., pentru că ele constituie un model general (şi instructiv) pentru realizarea unui "help" (indiferent de natura domeniului vizat), sau a unui "dicţionar".
Însă practica obişnuită e alta - am văzut lucrări dicţionar economic bilingv (în "Proiecte europene") realizate folosind (la nivelul obişnuit…) Microsoft-Word (cotate superlativ, "vai, cât au muncit!").
Să exemplificăm comenzile redate şi pe cazul bazei noastre de date:
mysql> use atestat; Database changed mysql> show tables; +-------------------+ | Tables_in_atestat | +-------------------+ | clasa | | elev | | localitate | | lucrare | | prof | | scoala | | serie | | soft | | soft_lucrare | +-------------------+ 9 rows in set (0.01 sec) mysql> describe serie; +-------+---------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +-------+---------+------+-----+---------+----------------+ | id | int(11) | NO | PRI | NULL | auto_increment | | an | year(4) | YES | UNI | NULL | | +-------+---------+------+-----+---------+----------------+ 2 rows in set (0.00 sec) mysql> show create table lucrare; CREATE TABLE `lucrare` ( `id` int(11) NOT NULL auto_increment, `id_prof` int(11) default NULL, `titlu` varchar(128) collate utf8_romanian_ci default NULL, `sumar` text collate utf8_romanian_ci, PRIMARY KEY (`id`) ) ENGINE=MyISAM DEFAULT CHARSET=utf8 COLLATE=utf8_romanian_ci
Între baza de date (MySQL) şi aplicaţie Web (PHP)
Contextul constituirii mai sus a bazei de date atestat, induce crearea unei interfeţe comod de folosit pentru cei care ar dori să acceseze sau să editeze datele respective pe de o parte şi însăşi baza de date pe de cealaltă.
Astfel că avem de exemplificat o aplicaţie Web, să-i zicem atestate.php: baza de date este stocată undeva pe un server, iar utilizatorii - folosind fiecare, browserul propriu - vor accesa serverul (indicând adresa corespunzătoare) şi aplicaţia respectivă (adăugând la adresa serverului, /atestate.php). Serverul va pune în execuţie codul existent în fişierul atestate.php şi va returna fişierul rezultat browserului de la care a primit cererea; acest fişier va conţine şi nişte formulare HTML, prin intermediul cărora (după ce utilizatorul le completează şi face click pe un buton de tip "submit") browserul utilizatorului va putea emite serverului respectiv diverse cereri - inclusiv pentru conectare MySQL (apoi, înregistrare/modificare în baza de date atestat).
Prin urmare, ar fi de conceput fişiere (X)HTML, CSS, javaScript şi fişiere PHP (sau Perl), care să realizeze împreună cele sugerate mai sus. Toate aceste fişiere compunând împreună aplicaţia noastră, vor fi stocate pe hard-diskul serverului (web-serverul va servi numai fişiere existente în directorul care-i este specificat drept DocumentRoot); fişierele HTML, CSS, javaScript vor fi transmise direct browserului şi vor fi "executate" de către browserul-client; fişierele PHP (sau Perl) vor fi puse în execuţie de către server (rulând pe calculatorul-host) şi eventual, serverul va returna browserului-client rezultatele execuţiei.
Acestea sunt demersurile tipice, pentru a produce aplicaţii Web. Deschizi un editor de text (unul decent, desigur) şi constitui fişierele necesare; pe parcurs, trebuie să probezi frecvent cum "merge" una sau alta şi cum "se vede" într-un browser sau altul, te mai documentezi despre una sau alta, etc.
Dar să observăm chiar de la bun-început: avem de lucrat în aplicaţia noastră şi cu o bază de date - păi unde apare menţionat mai sus (între fişierele care ar compune aplicaţia) vreun fişier SQL? Păi nu apare nicăieri şi altfel - numai un program care rulează pe server (deci în PHP etc., dar nu în javaScript, sau în HTML) ar putea lansa în vreun fel mysql, pentru a-i da comenzile MySQL de executat asupra bazei de date.
Există câteva clase PHP, care asigură interfaţa necesară cu diverse DBMS-uri; ele sunt definite în fişierele .php din /usr/share/php/DB pe un sistem Debian-Linux (respectiv în subdirectorul ext, alături de alte "extensii", în cazul XAMPP pentru Windows). În /DB/common.php este definită o clasă care serveşte ca bază pentru toate DBMS-urile; metodele acesteia sunt adaptate apoi, fiecărui DBMS: mysql.php extinde clasa de bază DB_common, permiţând conectarea cu MySQL şi operarea din programe PHP cu baze de date MySQL; analog, pgsql.php serveşte ca interfaţă între PHP şi PostgreSQL, iar dbase.php pentru interfaţare cu dBase (SGBD-uri bazate pe formatul de fişier .dbf, precum FoxPro "clasic"); etc.
Ilustrăm mai jos maniera tipică pentru PHP, de lucru cu o bază de date; dar implicăm nu mysql.php, ci clasa PHP mai nouă mysqli - pentru PHP 5 (şi MySQL ulterior versiunii 4.1). Sufixul i din noua denumire vine de la "improved"; vechea interfaţă cu MySQL era de natură procedurală (operaţiile fiind asigurate prin apeluri de funcţii), în timp ce mysqli este "object-oriented" (plus încă alte aspecte avantajoase).
<?php $dbi = new mysqli("host_name", "db_user", "db_password", "db_name"); /* sub Windows—XAMPP, cu setările 'default': mysqli("localhost", "root", "", "db_name") */ /* variabila introdusă $dbi referă un obiect PHP de clasă "mysqli", cu proprietăţi şi metode precum "connect_error" şi "query()", accesibile prin operatorul "—>" */ if ($dbi->connect_errno) { die("Connect failed: " . $dbi->connect_error); } /* Metoda query(string) transferă comenzi SQL serverului MySQL */ /* mai întâi, comenzi SQL care nu returnează date din DB; query() întoarce TRUE/FALSE pentru "succes/insucces" */ $dbi->query("USE testwork"); // or die("USE failed: the DB must be created before"); $dbi->query("CREATE TABLE IF NOT EXISTS elevi(nume varchar(16), pren varchar(16), " . "id int auto_increment primary key)"); // or die("CREATE TABLE failed"); $dbi->query("INSERT INTO elevi (nume, pren) VALUES('Popa','Ion'),('Popa','Jan'), " . "('Bacu','Bar'),('Pasu','Fan')"); // or die("INSERT failed"); /* or die("...") — serveşte după caz, pentru depanare (debug) */ /* acum operaţii SQL care returnează un set de date din DB */ if ( $result_set = $dbi->query('SELECT * FROM elevi ORDER BY concat(nume,pren)') ) { print("Elevi înregistraţi:<br>\n"); /* Fetch the results of the query */ while( $row = $result_set->fetch_assoc() ) { printf("%s %s<br>\n", $row['nume'], $row['pren']); } /* în final, dealocă memoria utilizată pentru setul de date $result_set */ $result_set->close(); } /* Close the connection */ $dbi->close(); ?>
Pentru un singur tabel (sau poate două, trei) sintagma redată mai sus este suficientă; mai adăugăm - dar vezi documentaţia! - că multi_query($q) permite transmiterea unei secvenţe de mai multe interogări (separate prin ";"). Dar dacă este cazul angajării mai multor tabele, atunci este de dorit să se conceapă nişte funcţii de bază de genul insert($table, $data) care să poată fi invocate pentru un tabel sau altul şi pe un "array" asociativ corespunzător, de date.
Conceptul Model-Controller-View
Am sesizat mai sus că MySQL (sau alt DBMS) şi PHP (sau Perl, etc.) sunt lucruri separate, complet diferite, fiind necesară o "punte" (mai precis, API) între ele (precum clasa PHP mysqli evocată mai sus, sau pentru alt exemplu, modulul Perl DBI). Această interfaţă conţine exact ceea ce este necesar (minimul necesar) pentru a putea opera de la nivelul limbajului (PHP, Perl, etc.) cu baze de date (MySQL, etc.); este suficient să dispui de funcţii de operare cu un singur tabel, pentru a putea lucra apoi cu oricare altul şi cu oricâte tabele. În final, am observat mai sus că dacă-i vorba de lucrat cu mai multe tabele, atunci este de dorit un model prealabil conţinând funcţii generice (pentru "insert", "update", etc.) parametrizate după $table şi $data; în Perl, avem de exemplu modulul "clasic" Class::DBI care "extinde" DBI în sensul genericităţii operaţiilor şi relaţionării tabelelor.
Avem o separare evidentă între PHP (sau Perl, etc.) şi MySQL (sau alt DBMS), ca şi între HTML şi CSS, sau între HTML şi javaScript; ba chiar între părţile constituente (explicit sau doar în mod tacit) ale unui program C care rezolvă enunţuri popularizate prin manuale să se scrie un program care citeşte de la tastatură... şi afişează...: o parte a programului modelează datele necesare, o alta este destinată operaţiilor de "citire/scriere" şi de prezentare adecvată a rezultatelor şi o altă parte le antrenează pe celelalte după caz şi modelează totodată rezolvarea propriu-zisă a problemei.
Este destul de firesc să se facă o separare între modelarea sau structurarea datelor sau documentului - la nivelul MySQL, sau HTML de exemplu (sau poftim: în secţiunea "var" a unui program Pascal) - pe de o parte, prezentarea rezultatelor sau documentului - prin CSS de exemplu - şi respectiv, controlul interacţionărilor şi formularea diverşilor algoritmi necesari (ceea ce ar reveni limbajului de programare folosit - javaScript, PHP, etc.).
Şi este aşa de naturală această separare a lucrurilor încât nici nu te gândeşti că ea ar datora ceva conceptului "teoretic" Model-Controller-View, descris prima dată înainte de 1980 (abia apăruse The C Programming Language, în 1978; iar PHP, Perl, HTML, javaScript etc. au apărut după 1990).
O aplicaţie elaborată după tiparul MVC (nu "MCV" - abreviaţie rezervată altor domenii sau concepte) este compusă din "Modele", "View-uri" şi "Controllere". Modelele conţin toate codurile referitoare la baze de date, sau la diversele structuri de date implicate; de exemplu, tabelului "localităţi" din baza noastră atestat ar trebui să-i corespundă un model conţinând funcţiile necesare pentru selectare, inserare, updatare, ştergere etc., a datelor din acel tabel (şi eventual, de relaţionare cu alte modele). View-urile conţin toate elementele referitoare la "afişare" sau la "user interface" - poate fi cod HTML, CSS, javaScript, eventual PHP, etc. Iar pentru "controllere" este specific acest lucru: fiecare funcţie dintr-un controller reprezintă o destinaţie, de exemplu o altă pagină din site-ul respectivei aplicaţii; la accesarea acelei pagini, funcţia asociată ei în cadrul controller-ului va invoca eventual modelul de date necesar, va prelucra datele obţinute astfel şi va invoca apoi view-ul corespunzător.
După anul 2000 au fost realizate numeroase framework-uri care automatizează într-o anumită măsură şi simplifică procesul de creare (sau de încropire) a unei aplicaţii Web, pe tiparul MVC. Cel mai celebru este Ruby on Rails (apărut în 2005), care a stat apoi la baza creării multor alte astfel de framework-uri (inclusiv, PHP frameworks). De obicei, trebuie doar să instalezi pe server framework-ul respectiv, să-i specifici anumite configurări (pentru server şi pentru baza de date), să accepţi anumite convenţii specifice şi să mai editezi unele dintre şabloanele de program (MVC) oferite.
Temă… şi motivaţii
În loc să exemplificăm aici, folosirea unui MVC-framework pentru a şi realiza efectiv aplicaţia descrisă mai sus - preferăm să propunem şi noi o temă, chiar şi pentru "lucrarea de atestat": realizaţi o aplicaţie Web pentru a oferi informaţii despre lucrările de atestat produse de elevii din judeţ (sau de ce nu - din întreaga ţară).
A avea în vedere că "lucrări de atestat" sunt cerute şi la alte profile (nu numai la "matematică-informatică", dar de exemplu şi la "economic"), iar informaţiile respective pot fi utile şi în anii următori; "informaţii despre" se referă nu la "ce notă a luat" (mai ştiţi să se ia mai puţin de nota 9 sau 10?!), ci mai degrabă la: titlu, autor, sumarul lucrării, ce produse soft (sau bibliografie) implică, cine este "îndrumătorul lucrării" şi eventual (dacă merită) un link la textul PDF al întregii lucrări.
A folosi eventual (şi a documenta corespunzător—eventual în limba română—dar… succint) CodeIgniter, sau CakePHP (sau un alt PHP-framework).
Desigur, în scopul de a "susţine atestatul" este suficientă constituirea şi funcţionalitatea minimală; de exemplu, planul lucrării scrise poate fi acesta: descrierea bazei de date (ce tabele, ce relaţii, eventual diagrama ERD, eventual fişierul SQL care o creează); scurtă descriere a framework-ului utilizat.
Altfel, mai ambiţios - aplicaţia ar putea fi completată cu "search", cu "forum", cu o parte de "autentificare" (permiţând anumitor utilizatori să înregistreze date), etc. Aplicaţia ar putea deveni destul de "tare", dar pentru aceasta îţi trebuie un alt nivel de motivaţie decât acela de "a susţine atestatul"…
Profesorul Anghel Rugină observa la o întrunire: "Toţi se gândesc la bani, nimeni la lumină…" şi într-adevăr, auzim şi de la unii elevi: "fac aplicaţia ca să o vând". NU, nu-i momentul de a te gândi la bani; faci aplicaţia în primul rând ca să înveţi să faci aplicaţii (împreună cu toate cele pe care se bazează această activitate); şi numai dacă-ţi place să faci, vei ajunge să faci şi aplicaţii pe care se pot obţine bani şi eventual, vei ajunge să faci şi aplicaţii bune (pe care nu neapărat se obţin imediat şi bani).
Iar în legătură cu "vânzarea", trebuie să te gândeşti şi la acest aspect: ce foloseşti ca să realizezi aplicaţia? Foloseşti cumva, ceva soft comercial? - dacă este aşa şi dacă l-ai achiziţionat legal, atunci poţi vinde legal produsul respectiv (dacă ai dreptul legalizat de a vinde) şi de obicei e treaba celui care cumpără, să achiziţioneze (suplimentar) şi licenţele soft-ului de care te-ai folosit.
Dar cel mai adesea, pentru a crea aplicaţii Web se foloseşte soft open-source - iar în acest caz principiul nu poate fi decât acesta: ai folosit soft "open-source", atunci rezultă deasemenea, un produs "open-source"; n-ai dat bani pe licenţă (fiind vorba de Free-software-lincense) - atunci nu cere bani!
Există şi în acest caz, modalităţi legale prin care se pot obţine şi bani, mai devreme sau mai târziu; şi dacă rezultă nişte bani, atunci este firesc ca o parte oarecare să fie dirijată şi către autorul soft-ului care te-a ajutat să-ţi construieşti aplicaţia - mai ales dacă ai şi apelat la el (prin mail, etc.) pentru diverse lămuriri sau pentru a cere anumite facilităţi suplimentare (cum se obişnuieşte în comunitatea "open-source").
De data aceasta, nu banii şi nu chichiţele legale sunt partea esenţială a lucrurilor, ci însuşi faptul ca soft-ul respectiv este utilizat (pentru a-ţi construi cu ajutorul lui, aplicaţia proprie); autorul acelui soft este astfel motivat să-l întreţină, să-l perfecţioneze şi să ofere sprijin utilizatorilor (sperând totuşi, că unii dintre aceştia vor putea şi să ofere cumva, un anumit suport financiar).
vezi Cărţile mele (de programare)