Un set de date URÂT: rezultatele bacalaureatului (I: curăţarea datelor)
[1] data.gov.ro "date accesibile, reutilizabile si redistribuibile" de la instituţii publice
[2] Statistici pe judeţ, mediu şi grupe de medii, folosind R (partea a III-a)
În ultimii ani, datele constituite în urma desfăşurării examenelor naţionale ajung să fie publicate pe [1]. Zicând "publicate", avem de înţeles "publicate în format utilizabil" - adică (subliniem), nu ca "document Microsoft Word" (şi nici ca "document PDF", sau "imagine JPG", sau ca secvenţă de cadre video - a vedea de exemplu, edu.ro care este în fond un depozit de fişiere ".DOC" şi ".PDF" oferite spre "download"): se colectează date asupra unui anumit subiect de interes nu pentru a le tipări şi a ne uita la ele - ci în vederea explorării, prelucrării şi analizei ulterioare; datele respective au sens şi devin valoroase în măsura în care ele fac posibilă deducerea unor anumite caracteristici şi eventual, tendinţe ale subiectului sau domeniului pe care - în mod punctual - îl reprezintă.
După ce specialiştii le-au disecat, sintetizând concluziile corespunzătoare - datele respective îşi pierd importanţa practică (punctuală), devenind o simplă notiţă pentru istorie; eventual, dacă sunt păstrate ca atare - ele pot servi oricând drept material didactic. Datele preluate de la [1] pentru "examenele naţionale" constituie un material didactic de bună calitate: avem de-a face cu seturi voluminoase, de date reale şi în plus, avem de sesizat şi îndreptat carenţe (obişnuite din păcate, pentru instituţiile noastre) ale reprezentării şi înregistrării datelor respective.
Într-o serie de articole anterioare (încheind cu [2]) am prezentat elemente de limbaj R şi de grafică statistică, angajând datele examenului de evaluare naţională; de fapt, aveam de ales între două seturi de date de examen şi am preferat pe cel pentru care fişierul CSV de la [1] are dimensiunea mai mică (de aproape opt ori: 14.4 MB faţă de 105.8 MB). Cu această experienţă în spate, vom angaja acum şi datele examenului de bacalaureat, din fişierul de 105.8 MB bacinscriere2015sesiuneai00.csv.
1. text CSV versus document ODS
De fapt aveam de ales şi acum, între două fişiere (şi am ales CSV):

"ODS" indică un fişier în format Open Document Format for Office Applications; toate suitele "office" - inclusiv Microsoft Office - suportă formatul ODF (.odt pentru Text sau "document Microsoft Word", .odp pentru "Presentation", .ods pentru "Spreadsheet", .odg pentru "Graphics", etc.).
Am descărcat ambele fişiere indicate şi mai întâi le-am comparat ca dimensiune (folosind ls cu -s pentru "size" şi -h pentru "human readable format"; -1 listează câte un fişier pe linie):
vb@Home:~/15_bac$ ls -hs1 bacins* # fişierele numite începând cu "bacins" 38M bacinscriere2015sesiuneai000.ods OpenDocument Spreadsheet 106M bacinscriere2015sesiuneai00.csv Comma Separated Values
Dar să nu ne păcălim comparând mot à mot 38 MB şi 106 MB; un fişier ODF (dar nu-i de loc necesar să ştii asta, ca să foloseşti ODF) constă dintr-o arhivă ZIP conţinând fişiere XML asociate conţinutului şi specificaţiilor de formatare ale documentului:
vb@Home:~/15_bac$ unzip bacinscriere2015sesiuneai000.ods Archive: bacinscriere2015sesiuneai000.ods extracting: mimetype inflating: styles.xml inflating: content.xml inflating: META-INF/manifest.xml inflating: meta.xml vb@Home:~/15_bac$ ls -hs1 *.xml 902M content.xml 4.0K meta.xml 4.0K styles.xml
Ultima secvenţă redată mai sus arată că prin dezarhivarea fişierului ODS (de 38 MB) avem un fişier XML care are peste 900 MB; este clar preferabil, fişierul CSV de 106 MB (care arhivat, ar avea 7 MB).
Din "meta.xml" deducem imediat că fişierul ODT oferit la [1] a fost generat din Microsoft Excel:
<meta:generator> MicrosoftOffice/12.0 MicrosoftExcel/CalculationVersion-4518 </meta:generator>
"styles.xml" defineşte formatări pentru afişare sau scriere: numele (şi aspecte ca mărimea) fontului folosit, margini de pagină, caracteristici ale antetului şi subsolului paginii, etc.; iar "content.xml" conţine şi el - pe lângă datele propriu-zise, aflate fiecare sub câte un tag XML <text:p> - numeroase specificaţii de formatare a rândurilor şi celulelor. Cam aşa arată în final, tabelul rezultat încărcând fişierul ODS în Gnumeric (coloanele se întind până la AZ - 52 de coloane):
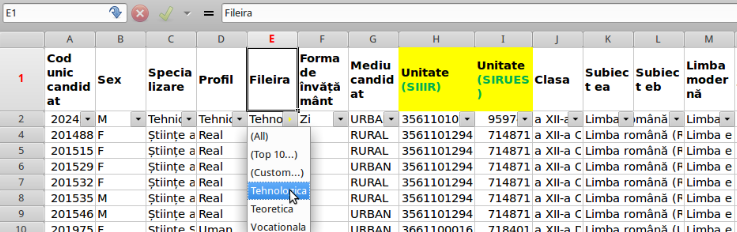
Foaia de calcul sugerată în imaginea de mai sus a permis desigur - şi aceasta, fără a şti ceva despre formatul ODF! - introducerea şi modificarea datelor (de exemplu, era aplicată culoarea galben pe antetul coloanelor obligatoriu de completat), precum şi tipărirea "frumoasă" a tabelului sau a unor porţiuni din tabelul respectiv. Dar aici nu vom avea de afişat sau de tipărit tabelul respectiv (sau porţiuni ale sale) şi nici de introdus ori de modificat date - încât am ales fără nicio ezitare fişierul în format CSV (de 9 ori mai scurt decât celălalt, conţinând numele coloanelor şi doar datele propriu-zise - nimic altceva - din fiecare coloană).
1-notă: document ODS versus LAMP (aplicaţii Web cu baze de date)
Ar fi fost cum nu se poate mai firesc ca la originea datelor respective să fie o bază de date (cu tabele relaţionate între ele, pentru candidaţii seriei curente, pentru candidaţii din promoţii anterioare, pentru profile, probe, etc.), întreţinută eventual prin intermediul unor formulare adecvate fiecărei etape a desfăşurării examenului, începând de la înscrierea candidaţilor. Ar fi vorba în fond de o aplicaţie Web tipică, angajând de exemplu MySQL (măcar pentru crearea bazei de date) şi - de exemplu - Python (prevăzând funcţii pentru conectare autorizată la baza de date, pentru crearea formularelor de transfer a datelor spre şi dinspre utilizatori, etc.), folosind eventual şi javaScript şi bineînţeles, HTML şi CSS.
Dar tehnologia vizată astfel - numită generic LAMP, cu variante moderne bazate pe Node.js - este cu siguranţă mai greu de înţeles şi de însuşit decât mecanica point-and-click specifică gamei Microsoft Office şi educaţiei facile şi în plus este mai nouă: produsele web framework de exemplu, au început să apară şi să "prindă" după anul 2006, în timp ce ODF s-a definitivat şi s-a impus în 2002-2005.
Faptul că ODF a fost împins în diverse ţări şi organizaţii drept formatul standard pentru documentele oficiale publice ne este explicat ca fiind un mare câştig: nu mai depinzi de un software anume, fiindcă toate suitele "office" (nu numai Microsoft Office) recunosc acest format şi totodată, acest format este valabil şi pentru documente produse cu "procesoare de text" precum Microsoft Word şi pentru documente tabelare produse cu aplicaţii precum Microsoft Excel, etc.
Însă această justificare… şchioapătă. De exemplu, ca individ eşti scutit să cumperi licenţe Microsoft - poţi deschide documentele respective folosind free software; dar instituţiile care produc documentele respective folosesc Microsoft Windows şi Microsoft Office (nicidecum "free software"), angajând mereu bugetul public pentru a achiziţiona licenţele aferente, pentru fiecare calculator în parte. Şi chiar este departe de adevăr, că "nu mai depinzi de un software anume" - depinzi de "office", adică de limitările specifice "point-and-click" (urmând cu asemenea educaţie, să devii treptat un funcţionăraş standard).
ODF este în fond un format şi rigid şi greoi, oferind mult mai puţin decât oferă o aplicaţie Web chiar şi modestă; dar lucrurile nu pot evolua în altă direcţie decât cea vizată de ODF, dat fiind că pentru guvern(e) şi parlamente şi instituţii informartizare este nimic altceva decât microsoftizare.
2. Windows "widechar" (UTF-16) versus UTF-8
Windows foloseşte UTF-16 pentru codificarea caracterelor, în vederea reprezentării şi manipulării textelor scrise în diverse limbi; deci pentru fiecare caracter se utilizează 16 biţi (pentru caractere mai rar întâlnite se îmbină după o anumită regulă, două coduri de câte 16 biţi). În imaginea redată mai sus a tabelului rezultat încărcând fişierul ODS în Gnumeric - vedem şi caractere specifice limbii române (în cuvântul "Ştiinţe" din coloana C, în cuvântul "învăţământ" din antetul coloanei F, etc.); în Excel putem verifica reprezentarea acestor caractere folosind funcţiile unicode() şi unichar():

Micul experiment sugerat de această imagine arată că "ă" este reprezentat prin codul de 16 biţi cu valoarea zecimală 259, iar codului 0xC483 (redat în notaţie hexazecimală) îi corespunde nu caracterul "ă", ci un anumit caracter japonez (redat în coloana E din imagine). Însă în UTF-8, codul de doi octeţi (tot 16 biţi, dar văzuţi nu împreună ca valoare de tip "wchar-t", ci ca un grup de câte 8 biţi) 0xC483 reprezintă chiar caracterul "ă" (şi nu caracterul japonez din coloana E).
Prin urmare, fişierul CSV a ajuns aşa de mare (la aproape 106 MB) mai ales din cauza reprezentării fiecărui caracter pe câte doi octeţi; de fapt, în fişierul respectiv numărul de caractere nestandard (ca "ă", "ş", "ţ", etc.) este foarte mic - dat fiind că numele candidaţilor au fost înlocuite prin coduri numerice; iar pentru caracterele din setul standard (a-z, A-Z, 0-9, ',', '.', etc.), octetul superior din reprezentarea UTF-16 este totdeauna 0 (încât l-am putea omite, păstrând numai octetul inferior care este chiar codul ASCII obişnuit al caracterului respectiv).
Putem folosi programul utilitar iconv, pentru a transforma fişierul CSV descărcat de la [1] - codificat prin UTF-16 - într-un fişier codificat prin UTF-8:
vb@Home:~/15_bac$ iconv --from-code=UTF-16 --to-code=UTF-8 --output=bac15.csv \ bacinscriere2015sesiuneai00.csv vb@Home:~/15_bac$ ls -hs bac15.csv 55M bac15.csv
Fişierul CSV iniţial s-a redus aproape la jumătate (55 MB faţă de 106 MB) şi în continuare vom lucra numai cu fişierul "bac15.csv" rezultat astfel. În plus, această transformare ne asigură şi o anumită simplificare: unele comenzi ar necesita precizarea codificării, printr-un parametru "fileEncoding" (de exemplu read.csv("bacinscriere2015sesiuneai00.csv", fileEncoding="UTF-16")) - dar parametrul respectiv are valoarea implicită "UTF-8" (încât eşti scutit de grija lui, pentru textele UTF-8).
Fiindcă fişierul a provenit din Windows, caracterul '\n' (pentru "sfârşit de linie") este reprezentat prin 2 octeţi: 0x0D=CR şi 0x0A=LF (ne referim la "bac15.csv"; în fişierul CSV iniţial, în UTF-16 - caracterul '\n' era reprezentat prin 4 octeţi: 0x000D şi 0x000A); pe Linux, caracterul '\n' este reprezentat pe un singur octet, 0x0A=LF şi putem folosi un program utilitar ca fromdos pentru a înlocui 0x0D0A prin 0x0A.
3. Separatori: virgula separă, punctul împarte, TAB deplasează
Cu programul utilitar xxd putem lista o zonă de octeţi consecutivi din fişierul "bac15.csv":
vb@Home:~/15_bac$ xxd -g 1 -s +50 -l 48 bac15.csv 0000032: 09 46 6f 72 6d 61 20 64 65 20 c3 ae 6e 76 c4 83 .Forma de ..nv.. (0xC483 -> ă) 0000042: c8 9b c4 83 6d c3 a2 6e 74 09 4d 65 64 69 75 20 ....m..nt.Mediu 0000052: 63 61 6e 64 69 64 61 74 09 55 6e 69 74 61 74 65 candidat.Unitate
Cei doi octeţi subliniaţi compun valoarea 0xC483 care este codul UTF-8 pentru "ă" - cum am precizat deja la §2. Câmpurile "Forma de învăţământ" şi "Mediu candidat" sunt separate prin octetul 09 - care este codul caracterului de control '\t' (numit "TAB", asociat tastei de tabulare); să mai observăm că denumirile respective nu sunt încadrate de câte un caracter '"' (ghilimele).
Nu există un format CSV standard - putem separa câmpurile prin '\t' ca în cazul de faţă, sau prin ';', sau printr-un caracter convenit (care să nu fie folosit ca atare, în text). Totuşi nu degeaba numele este "Comma Separated Values", adică "valori separate prin virgulă"; experienţa comună de folosire a tastaturii pentru editarea de texte (inclusiv tabele de date) şi pentru lucrul din linia de comandă cu diverse interpretoare de comenzi induce unor taste anumite roluri: componentele (unui text) sunt separate prin virgulă (în timp ce caracterul ";" este binecunoscut în programare drept "terminator" al formulărilor de program); împărţirea în partea întreagă şi respectiv, partea fracţionară a cifrelor unui număr se face prin caracterul punct (indiferent de interpretorul matematic folosit); ne deplasăm dintr-o coloană în alta (de tabel, sau chiar şi de text) folosind tasta TAB.
Dacă vom respecta normele uzuale, ne asigurăm anumite simplificări de programare: de regulă, acele funcţii care au de-a face cu CSV parametrizează separatorii - dar le asigură ca valori implicite pe cele uzuale (şi folosindu-le pe acestea ne scutim de griji şi evităm anumite dificultăţi).
Folosim sed pentru a înlocui ',' cu '.' şi apoi, '\t' cu ',':
vb@Home:~/15_bac$ sed -i -e 's/\,/\./g' bac15.csv 3.141593, nu 3,141593 vb@Home:~/15_bac$ sed -i -e 's/\t/\,/g' bac15.csv virgula separă, TAB deplasează!
Este drept că am înlocuit cu '.' şi caracterele ',' care apar în contexte nenumerice; de exemplu "Arhitectură, arte ambientale și design" a devenit "Arhitectură. arte ambientale și design". Dar nu puteam lăsa nicăieri ',' fiindcă şirurile de caractere care apar ca valori în diverse câmpuri nu sunt încadrate între ghilimele şi ca urmare, virgula internă dacă există, ar fi intrepretată ca separator de câmpuri! Redăm imaginea înregistrării complete a datelor unuia dintre candidaţi:

Observăm că într-adevăr, nu apar ghilimele; ni se pare preferabil să greşim - înlocuind toate virgulele cu '.' - în loc de a fi încorporat de atâtea ori, ghilimelele de protecţie necesare.
Lansând R putem acum să folosim funcţia read.csv() în cea mai simplă formă (cel puţin aşa stau lucrurile în cazul R version 3.3.1 (2016-06-21)):
vb@Home:~/15_bac$ R -q # --quiet (nu mai afişează mesajul introductiv) > bac5 <- read.csv("bac15.csv") > print(object.size(bac5), units="MB") 40.2 Mb
Am obţinut obiectul de memorie numit de-acum încolo "bac5", despre care vedem deocamdată (folosind funcţia object.size()) că se întinde cam pe 40-41 MB; nu vom mai avea de-a face cu fişierul "bac15.csv", iar pentru obiectul "bac5" va fi uşor să corectăm cazurile în care am obţinut '.' în locul virgulei, în interiorul valorilor textuale.
Desigur, "nu vom mai avea de-a face" în principiu; uneori va fi mai uşor să corectăm un anumit aspect luînd-o de la capăt (operând iarăşi pe fişierul CSV, cu care ziceam că "nu mai avem de-a face").
4. Coloane de tabel versus structură de date
Prin funcţia read.csv() pe care am invocat-o mai sus, denumirile coloanelor iniţiale au devenit nişte nume de variabile: caracterul ' ' (spaţiu) şi caractere precum '(' existente în denumirea iniţială au fost înlocuite prin '.' (de exemplu, "Unitate (SIIIR)" a devenit "Unitate..SIIIR."); a rezultat în final, o structură de date care în R se numeşte "data.frame" şi pe care o putem inspecta folosind funcţia str():
> str(bac5)
'data.frame': 168939 obs. of 52 variables:
$ Cod.unic.candidat : int 202458 202461 201488 201515 201529 201532 201535 201546 201975 201991 ...
$ Sex : Factor w/ 2 levels "F","M": 2 2 1 1 1 1 2 2 1 2 ...
$ Specializare : Factor w/ 96 levels "Arhitectură. arte ambientale și design",..: 59 59 20 20 20 ...
$ Profil : Factor w/ 10 levels "Artistic","Educație fizică și sport",..: 8 8 5 5 5 5 5 ...
$ Fileira : Factor w/ 3 levels "Tehnologica",..: 1 1 2 2 2 2 2 2 2 2 ...
$ Forma.de.învățământ: Factor w/ 3 levels "Frecvență redusă",..: 3 3 3 3 3 3 3 3 3 3 ...
$ Mediu.candidat : Factor w/ 2 levels "RURAL","URBAN": 2 1 1 1 2 1 1 2 2 2 ...
$ Unitate..SIIIR. : num 3.56e+09 3.56e+09 3.56e+09 3.56e+09 3.56e+09 ...
$ Unitate..SIRUES. : int 959744 959744 714871 714871 714871 714871 714871 714871 718401 714871 ...
$ Clasa : Factor w/ 3306 levels "a XII-a ","a XII-a -",..: 1952 1952 784 784 784 784 784 784 ...
$ Subiect.ea : Factor w/ 2 levels "Limba română (REAL)",..: 1 1 1 1 1 1 1 1 2 1 ...
$ Subiect.eb : Factor w/ 10 levels "","Limba croată",..: 1 1 1 1 1 1 1 1 1 1 ...
$ Limba.modernă : Factor w/ 10 levels "Limba ebraică",..: 2 2 2 2 2 2 2 2 2 2 ...
$ Subiect.ec : Factor w/ 5 levels "Istorie","Matematică MATE-INFO",..: 5 5 4 4 4 4 4 4 1 2 ...
$ Subiect.ed : Factor w/ 18 levels "Anatomie și fiziologie umană. genetică și ecologie umană",..: 2 2 ...
$ Promoție : Factor w/ 16 levels "19XY","2000-2001",..: 16 16 16 16 16 16 16 16 16 16 ...
$ NOTE_RECUN_A : Factor w/ 2 levels "Da","Nu": 2 2 2 2 2 2 2 2 2 2 ...
$ NOTE_RECUN_B : Factor w/ 2 levels "Da","Nu": 2 2 2 2 2 2 2 2 2 2 ...
$ NOTE_RECUN_C : Factor w/ 2 levels "Da","Nu": 2 2 2 2 2 2 2 2 2 1 ...
$ NOTE_RECUN_D : Factor w/ 2 levels "Da","Nu": 2 2 2 2 2 2 2 2 1 2 ...
$ NOTE_RECUN_EA : Factor w/ 2 levels "Da","Nu": 2 2 2 2 2 2 2 2 2 2 ...
$ NOTE_RECUN_EB : Factor w/ 2 levels "Da","Nu": 2 2 2 2 2 2 2 2 2 2 ...
$ NOTE_RECUN_EC : Factor w/ 2 levels "Da","Nu": 2 2 2 2 2 2 2 2 2 2 ...
$ NOTE_RECUN_ED : Factor w/ 2 levels "Da","Nu": 2 2 2 2 2 2 2 2 2 2 ...
$ STATUS_A : Factor w/ 6 levels "Absent","Avansat",..: 4 2 2 2 4 4 4 4 2 4 ...
$ STATUS_B : Factor w/ 5 levels "-","Absent","Avansat",..: 1 1 1 1 1 1 1 1 1 1 ...
$ STATUS_C : Factor w/ 4 levels "Absent","Calificativ",..: 2 2 2 2 2 2 2 2 2 3 ...
$ STATUS_D : Factor w/ 8 levels "Absent","Avansat",..: 2 8 5 5 5 5 5 5 3 5 ...
$ STATUS_EA : Factor w/ 4 levels "Absent","Eliminat",..: 4 4 4 4 4 4 4 4 4 4 ...
$ STATUS_EB : Factor w/ 5 levels "-","Absent","Eliminat",..: 1 1 1 1 1 1 1 1 1 1 ...
$ STATUS_EC : Factor w/ 4 levels "Absent","Eliminat",..: 4 4 4 4 4 3 4 4 4 4 ...
$ STATUS_ED : Factor w/ 4 levels "Absent","Eliminat",..: 3 4 4 4 4 3 4 4 4 4 ...
$ ITA : Factor w/ 5 levels "-","A1","A2",..: 3 4 4 3 3 3 4 4 4 1 ...
$ SCRIS_ITC : Factor w/ 5 levels "-","A1","A2",..: 3 1 3 3 3 3 3 3 3 1 ...
$ SCRIS_PMS : Factor w/ 5 levels "-","A1","A2",..: 4 3 2 2 2 1 2 4 3 1 ...
$ ORAL_PMO : Factor w/ 5 levels "-","A1","A2",..: 4 4 3 2 3 2 3 5 4 1 ...
$ ORAL_IO : Factor w/ 5 levels "-","A1","A2",..: 5 4 3 2 3 2 3 5 4 1 ...
$ NOTA_EA : num 6.05 7.85 9.1 6.2 8.45 5.8 7.7 5.65 7 9.9 ...
$ NOTA_EB : num NA NA NA NA NA NA NA NA NA NA ...
$ NOTA_EC : num 5.1 7.6 5.5 5 5 2.85 5.05 5.8 7.95 9.3 ...
$ NOTA_ED : num 4.2 6.85 6.2 6.45 6.95 3.6 7.15 7.3 9.1 8.4 ...
$ CONTESTATIE_EA : Factor w/ 2 levels "Da","Nu": 2 2 2 1 2 2 2 2 2 2 ...
$ NOTA_CONTESTATIE_EA: num NA NA NA 7 NA NA NA NA NA NA ...
$ CONTESTATIE_EB : Factor w/ 2 levels "Da","Nu": 2 2 2 2 2 2 2 2 2 2 ...
$ NOTA_CONTESTATIE_EB: num NA NA NA NA NA NA NA NA NA NA ...
$ CONTESTATIE_EC : Factor w/ 2 levels "Da","Nu": 2 2 2 2 2 1 2 2 2 2 ...
$ NOTA_CONTESTATIE_EC: num NA NA NA NA NA 3.2 NA NA NA NA ...
$ CONTESTATIE_ED : Factor w/ 2 levels "Da","Nu": 2 2 2 1 2 1 2 2 2 2 ...
$ NOTA_CONTESTATIE_ED: num NA NA NA 6.85 NA 3.05 NA NA NA NA ...
$ PUNCTAJ.DIGITALE : int 56 54 78 81 75 90 83 79 NA 92 ...
$ STATUS : Factor w/ 4 levels "Absent","Eliminat",..: 3 4 4 4 4 3 4 4 4 4 ...
$ Medie : num NA 7.43 6.93 6.15 6.8 NA 6.63 6.25 8.01 9.2 ...
Cele 52 de variabile din "bac5" sunt fie vectori numerici, fie vectori "factor" şi fiecare dintre aceştia are câte 168939 valori (deci în total au fost înscrişi 168939 candidaţi). Pentru exemplificare - factorul bac5$Subiect.ed indică în ordine alfabetică opţiunile probei D a bacalaureatului:
> levels(bac5$Subiect.ed) [1] "Anatomie și fiziologie umană. genetică și ecologie umană" [2] "Biologie vegetală și animală" [3] "Chimie anorganică TEH Nivel I/II " [4] "Chimie anorganică TEO Nivel I/II " [5] "Chimie organică TEH Nivel I/II" [6] "Chimie organică TEO Nivel I/II" [7] "Economie" [8] "Filosofie" [9] "Fizică TEH" [10] "Fizică TEO" [11] "Geografie" [12] "Informatică MI C/C++" [13] "Informatică MI Pascal" [14] "Informatică SN C/C++" [15] "Informatică SN Pascal" [16] "Logică. argumentare și comunicare" [17] "Psihologie" [18] "Sociologie"
Câţi au susţinut proba D la prima dintre opţiunile redate mai sus? Cu funcţia subset() extragem din "bac5" înregistrările dorite şi apoi folosim funcţia nrow():
> subset(bac5, Subiect.ed == levels(Subiect.ed)[1]) -> D1
> nrow(D1)
[1] 29627 # 29627 linii din 'bac5' au valoarea 1 în coloana 'Subiect.ed'
Putem face şi această mică verificare - afişând coloanele 1 şi 15 din primele două înregistrări:
> D1[1:2, c(1, 15)] # coloana 15 este "Proba D" Cod.unic.candidat Subiect.ed 18 206307 Anatomie și fiziologie umană. genetică și ecologie umană 19 206308 Anatomie și fiziologie umană. genetică și ecologie umană
Dar şirul de caractere care indică opţiunea respectivă a probei D se foloseşte numai pentru afişare! Intern, opţiunea respectivă este reprezentată prin numărul de ordine al ei - putem constata aceasta împărţind dimensiunea zonei de memorie ocupate de obiect la lungimea vectorului:
> object.size(D1$Subiect.ed)
120320 bytes
> 120320/29627
[1] 4.06116 # Valorile din a 15-a coloană sunt reprezentate intern pe câte 4 octeţi
Desigur că am obţinut ceva mai mult decât 4 (care este numărul de octeţi alocat pentru "integer") - fiindcă orice structură de date memorează şi diverse informaţii contextuale. În orice caz - micul experiment redat mai sus evidenţiază unul dintre avantajele mari ale structurării datelor (implicând desigur un limbaj de programare adecvat): în fişierul text "bac15.csv" şirul de caractere "Anatomie și fiziologie umană. genetică și ecologie umană" apare de 29627 ori, ocupând în total 29627*61 = 1807247 octeţi (numărul de caractere ale şirului este 56, dar am adăugat câte un octet pentru cele 5 caractere nestandard conţinute) - adică de peste 15 ori mai mult decât ocupă în memorie variabila corespunzătoare datelor respective, D1$Subiect.ed.
5. Sensul datelor
La [1] se furnizează "rezultatele anonimizate": numele şi prenumele candidaţilor au fost "şterse", punând în loc (cum vedem în prima coloană din tabelul redat la §1) un "Cod unic candidat". Şi noi aici, am şterge sau am ignora numele dacă ar fi existat - dar nu din raţiuni de confidenţialitate, ci pentru motivul că numele persoanelor sunt irelevante din punct de vedere statistic.
Găsim şi coloane de date care sunt irelevante şi coloane de date posibil redundante (reprezentând informaţii care pot fi deduse), iar unele coloane au denumiri impracticabile ca "identificatori" de variabile în programare ("Forma de învăţământ" vizează doar scopul tipăririi tabelului). Unele denumiri sunt stâlcite ("Fileira" în loc de "Filiera") sau stângace, trădând construcţia ad-hoc a tabelului, fără prea multă gândire şi bătaie de cap (aceasta este specific pentru maniera de lucru "point-and-click").
Cerinţa de bază va fi fost aceea de a tipări toate informaţiile cumulate pe parcursul desfăşurării examenului, separând aşa fel una de alta încât să nu fie pusă la încercare în nici un fel, inteligenţa celui care va căuta datele în tabel; de exemplu, apar patru coloane "NOTA_CONTESTATIE_E " pentru înregistrarea notelor acordate în urma soluţionării eventualei contestaţii - dar şi patru coloane "CONTESTATIE_E " pentru a înregistra că s-a făcut sau nu contestaţie la proba respectivă.
Chiar dacă nu este neapărat necesar (pentru a începe să ne ocupăm de statistici) şi nici nu este plăcut de făcut - vom elimina acele coloane care nu au sens şi vom simplifica unele denumiri. Întâi, salvăm pentru orice eventualitate structura de date "bac5" (o vom putea eventual recupera din fişierul respectiv, prin load()) şi listăm vectorul numelor variabilelor (avem astfel şi indecşii aferenţi):
> save(bac5, file="bac5.RData")
> names(bac5)
[1] "Cod.unic.candidat" "Sex" "Specializare"
[4] "Profil" "Fileira" "Forma.de.învățământ"
[7] "Mediu.candidat" "Unitate..SIIIR." "Unitate..SIRUES."
[10] "Clasa" "Subiect.ea" "Subiect.eb"
[13] "Limba.modernă" "Subiect.ec" "Subiect.ed"
[16] "Promoție" "NOTE_RECUN_A" "NOTE_RECUN_B"
[19] "NOTE_RECUN_C" "NOTE_RECUN_D" "NOTE_RECUN_EA"
[22] "NOTE_RECUN_EB" "NOTE_RECUN_EC" "NOTE_RECUN_ED"
[25] "STATUS_A" "STATUS_B" "STATUS_C"
[28] "STATUS_D" "STATUS_EA" "STATUS_EB"
[31] "STATUS_EC" "STATUS_ED" "ITA"
[34] "SCRIS_ITC" "SCRIS_PMS" "ORAL_PMO"
[37] "ORAL_IO" "NOTA_EA" "NOTA_EB"
[40] "NOTA_EC" "NOTA_ED" "CONTESTATIE_EA"
[43] "NOTA_CONTESTATIE_EA" "CONTESTATIE_EB" "NOTA_CONTESTATIE_EB"
[46] "CONTESTATIE_EC" "NOTA_CONTESTATIE_EC" "CONTESTATIE_ED"
[49] "NOTA_CONTESTATIE_ED" "PUNCTAJ.DIGITALE" "STATUS"
[52] "Medie"
Într-o structură "data.frame", fiecare observaţie are asociat câte un nume (în mod implicit, acesta este numărul de ordine al liniei respective); totuşi, păstrăm coloana "Cod.unic.candidat" (al cărei sens este de a identifica unic o linie, la fel ca şi numărul de ordine), dar sub numele simplu "Cand" - pentru că ea permite legarea eventuală cu tabelul de la care am plecat. Înlocuim denumirile "Subiect.ea", etc. cu "proba.A", etc. şi "NOTA_EA" etc. cu "nota.A" etc.:
names(bac5)[c(1, 5, 6, 7)] <- c("Cand", "Filiera", "Forma", "Mediu") names(bac5)[c(11:15)] <- c("proba.A", "proba.B", "limba", "proba.C", "proba.D") names(bac5)[c(38:41)] <- c("nota.A", "nota.B", "nota.C", "nota.D")
Dintre toate coloanele, cea denumită "Clasa" este chiar dubioasă, având valori cu totul particulare (ca să nu zicem însemne) precum "a XII-a B Talvac Sergiu" etc., sau bălării precum "a XII-a XII C", sau "a XII-a CLASA a XII-a" etc.; vom elimina şi cele opt coloane "NOTE_RECUN_ " de tip "Da/Nu", reprezentând recunoaşterea sau nerecunoaşterea notelor din sesiunile anterioare - coloane care au sens doar pentru fracţiunea de candidaţi care n-au încheiat examenul în anii anteriori; eliminăm şi cele opt coloane "STATUS_ " de tip "Da/Nu" - acestea induc valoarea finală a câmpului "STATUS" (păstrat):
bac5[, c(17:32, 42, 44, 46, 48)] <- NULL # elimină NOTE_RECUN_*, STATUS_*, CONTESTATIE_E* bac5$Clasa <- NULL # elimină coloana bălăriilor, `Clasa`
În plus faţă de ce am precizat mai sus, am eliminat şi cele 4 coloane "CONTESTATIE_E*"; răspunsul "Da/Nu" al acestora - dacă ar interesa - se deduce imediat din existenţa notei corespunzătoare în coloanele "NOTA_CONTESTATIE_E*" (coloane pe care le redenumim - dar nu mai redăm comanda respectivă - după modelul "nota.A.co").
5.1. Constituirea factorului corespunzător judeţelor
SIRUES era folosit înainte de 1990 pentru identificarea tuturor întreprinderilor "economico-sociale" din ţară (pare să corespundă azi cu numărul de înmatriculare la registrul comerţului); câmpul respectiv (chiar dacă este marcat "orange" în tabelul iniţial) este inutil în "bac5" şi o să-l eliminăm.
Coloana "Unitate..SIIIR." conţine codul din SIIIR care pe primele două cifre dintre cele zece identifică judeţul şi apoi codifică o serie de informaţii privitoare la unitatea şcolară din care provine candidatul respectiv; ne poate interesa numai judeţul şi avem de ţinut seama de faptul că în structura de date "bac5" valorile din câmpul respectiv sunt de tip numeric - astfel că prin conversie la caracter, putem obţine doar 9 cifre în loc de 10 (pentru judeţele codificate prin '0X', zeroul iniţial "s-a pierdut" prin conversia în reprezentare numerică):
> bac5[[8]][105040:105050]
[1] 1061104147 1061104147 1061104147 961100082 961100082 961100082
[7] 661100901 661101531 661100901 461107463 961102446
Aici am avut în vedere că o structură data.frame este în fond o listă de vectori (coloane), iar operatorul "[[" asigură selectarea unei componente a listei pe baza indexului acesteia (în timp ce operatorul "$" selectează pe baza numelui variabilei respective). Am constatat (şi am redat mai sus două rânduri) că de pe la înregistrarea de rang 105000 încep să apară şi candidaţii din judeţe de cod "0X" (cu prima cifră zero) - pentru care valoarea din coloana 8 are la afişare doar 9 cifre.
Următoarea funcţie returnează prima cifră prefixată cu "0", sau primele două cifre din codul de 9, respectiv 10 cifre primit ca argument:
jud_from_siiir <- function(siiir) { return(ifelse(nchar(siiir) == 10, substr(siiir, 1, 2), paste0(c(0), substr(siiir, 1, 1))) )}
În R, de obicei, funcţiile sunt "vectorizate": odată definită pentru un obiect, funcţia respectivă se poate invoca pentru un vector cu obiecte de tipul respectiv (sau pentru care este definită o conversie la tipul respectiv). De exemplu, funcţia introdusă mai sus poate fi aplicată unui vector de coduri:
> jud_from_siiir(c("123456789", "4012345678")) # [1] "01" "40"
Folosind astfel funcţia de mai sus, adăugăm în "bac5" variabila $jud, de clasă "character", având ca valori codurile de câte două cifre ale judeţelor; în final, eliminăm codurile SIIIR şi SIRUES:
> bac5$jud <- jud_from_siiir(bac5[[8]]) > bac5[, c(8, 9)] <- NULL
Undeva în [2], creasem o structură "jud.csp" conţinând şi numele judeţelor, în ordinea codurilor acestora; o putem refolosi acum, pentru a transforma coloana de coduri bac5$jud într-un "factor" având drept valori denumirile judeţelor:
> bac5$jud <- as.factor(bac5$jud) > levels(bac5$jud) <- jud.csp$judeţ
Redăm una dintre înregistrări (transpunând-o pe coloană prin funcţia t()) pentru a avea o imagine a modificărilor întreprinse:
>t(bac5[55482, ])
Cand "308401" SCRIS_PMS "-"
Sex "M" ORAL_PMO "B2"
Specie "Științe ale Naturii" ORAL_IO "B1"
Profil "Real" nota.A "5.35"
Filiera "Teoretica" nota.B NA
Forma "Zi" nota.C "5.55"
Mediu "RURAL" nota.D "6.95"
proba.A "Limba română (REAL)" nota.A.co "6.35"
proba.B "" nota.B.co NA
limba "Limba franceză" nota.C.co NA
proba.C "Matematică ST-NAT" nota.D.co NA
proba.D "Biologie vegetală și animală" DIGITALE "31"
Promoție "2014-2015" STATUS "Promovat"
ITA "A1" Medie "6.28"
SCRIS_ITC "A2" jud "Mureş"
Se vede că am mai înlocuit "PUNCTAJ.DIGITALE" cu "DIGITALE" şi "Specializare" cu mai scurt-ul "Specie"; bineînţeles că dacă va fi de afişat, vom afişa "Specializare" (de exemplu) şi nu cum am decis mai sus să folosim intern.
Am rămas cum se vede, la 30 de coloane de date - eliminând (cu justificările cuvenite) acele 22 de coloane care chiar nu au vreo importanţă pentru analiza rezultatelor, ţinând doar de organizarea şi desfăşurarea funcţionărească a examenului şi reflectând desigur, limitările inerente ale manierei de lucru "point-and-click" cu un singur tabel.
vezi Cărţile mele (de programare)