Aspecte de compatibilitate
Folosim sisteme diferite şi fiecare crede că sistemul său e cel mai bun; folosim şi credem în funcţie de ce ştim, de aplecările proprii şi de interesul faţă de ce vrem să mai ştim. Cel mai adesea, ai de folosit lucruri care nu te interesează pentru a produce lucrurile care te interesează; fiecare se poate mulţumi cu sistemul său, dar uneori trebuie să te întrebi şi despre celălalt sistem (poate chiar şi despre propriul sistem).
Uneori am de asigurat o anumită compatibilitate între documente produse pe sisteme diferite. Dar să precizez întâi că eu lucrez pe un sistem Ubuntu-Linux, pot zice "de peste 10 ani"; ar fi probabil, trei întrebări (la care, conjuctural, că am mai răspuns pe aici).
Ce lucrez?
Pe de o parte, programe în diverse limbaje; nu m-am sfiit să folosesc mai multe limbaje, iar Ubuntu oferă în modul cel mai firesc această posibilitate (am folosit "după caz" C, C++, GNU Assembler, Bash, Perl, AWK, Python, MySQL, R, MetaPost, javaScript, PHP, Prolog "şi altele"). Pe de altă parte, lucrez (în HTML, implicând eventual şi MathJax) articolele prezentate aici (pe //docerp.ro).
Cum lucrez?
Folosesc o tastatură obişnuită pentru programatori (pentru care virgula, punct-şi-virgula, parantezele şi slash-urile sunt caractere esenţiale şi este foarte neplăcut ca acestea să fie înlocuite prin 'ţ' sau 'ş' sau 'ă'); am setat "keyboard layout" pe "Romanian (cedilla)", deci introduc litere româneşti apăsând tasta 'alt gr' şi apoi litera de bază (de exemplu, pentru ă apăs 'alt gr' şi 'a', iar pentru â - 'alt gr' şi 'q' unde 'a' şi 'q' sunt deja nişte locuri "automate" pentru degetele mele). Această tastatură este una obişnuită, adică mai are şi extensia inutilă denumită "tastatură numerică" (cea vizată în Windows prin celebra tastă "NumLock") - dar nu ştiu nicio situaţie (în toţi aceşti ani) în care să fi avut nevoie de aşa ceva.
Folosesc un editor de text simplu, gedit (ales din start de către Debian şi Ubuntu); acesta îmi oferă imediat, facilităţile de editare obişnuite şi evidenţiază cuvintele cheie şi sintaxa pentru o gamă foarte mare de limbaje, permiţând şi tab-uri pentru a edita concomitent mai multe fişiere.
Folosesc un terminal simplu, xfce4-terminal, care îmi pune la dispoziţie linia de comandă prin intermediul căreia accesez comenzile sistemului şi lansez când am nevoie diverse programe utilitare, interpretoare, sau compilatoare.
Mai folosesc GNOME Commander, pentru vizualizarea comodă a structurilor de directoare de pe disk.
De obicei am deschise într-un acelaşi "workspace" un terminal, gedit şi GNOME Commander, iar într-un alt "workspace" am Firefox (un lucru foarte important pentru "sistemul meu" este conexiunea la Internet, dar desigur… îmi amintesc de acest fapt doar când se întâmplă să "cadă").
Ce aplicaţii utilizez curent?
Am avut nevoie mereu, să mă documentez asupra unor limbaje, formate de fişier, subiecte (de exemplu, diverse clase de curbe); aceasta înseamnă să cauţi pe Internet, să alegi, să accesezi, să deschizi şi (mai ales) să citeşti un document sau altul pentru a te lămuri asupra chestiunii respective. După o experienţă de peste 20 de ani, pot preciza: documentele utile pentru propria instruire (articole redate din diverse reviste de informatică sau de matematică, cărţi sau pur şi simplu, documentaţii) se găsesc în marea lor majoritate, în limba engleză.
Sursa de documentare favorită, pentru diverse itemuri (în principal, specifice matematicii şi informaticii) este https://en.wikipedia.org/wiki/.
Folosesc Firefox; "Document Viewer"-ul implicit este evince ("Simply a Document Viewer"). Mă folosesc uneori şi de instrumentele de depanare din Firefox şi Google Chrome, pentru a investiga HTML, JS şi CSS şi a pune la punct diverse pagini.
Drept "Image Viewer" folosesc de obicei eog ("Eye of GNOME"). Pentru capturi de ecran folosesc de obicei GNOME Screenshot.
De la HTML (şi utf8) la MikTex (şi probabil, iso-8859)
Cam toate documentele oficiale publicate de instituţiile noastre sunt elaborate totuşi, pe sisteme Windows, în formate specifice Microsoft: ".doc", adică document realizat prin Microsoft-Word; ".ods" adică (impresionant) Open Document Format for Office Applications (ODF), etc. M-am lovit în câteva rânduri (salarizare în învăţământ, analiza rezultatelor "examenelor naţionale") de necesitatea de a interpreta asemenea documente pe sistemul Ubuntu-Linux al meu - cum se poate vedea de exemplu, în Bacalaureat - de la forma microsoftizată, la R şi O aplicaţie de salarizare.
Dar iată că a apărut şi problema inversă: aş avea de oferit spre publicare în vreo revistă de la noi, un articol; bineînţeles că dacă mi se cere să-l trimit ca document Microsoft-Word atunci renunţ imediat (şi nici nu mă uit la revista respectivă), dar iată că mi se cere să trimit "şi sursa LaTeX " a articolului.
Chestiunea devine atunci interesantă: pe de o parte, articolul pe care l-aş avea de propus ar proveni dintr-un fişier HTML publicat pe site-ul meu şi o primă problemă ar fi aceea de a converti HTML în LaTeX (urmând apoi să modific "sursa LaTeX" rezultată astfel, ceea ce este desigur mai convenabil decât să rescriu de la început în LaTeX); pe de altă parte, trebuie să ţin cont de faptul obişnuit că editarea revistei decurge pe un sistem Windows pe care se va fi instalat MikTex (adaptarea "point-and-click", pentru Microsoft-Windows, a sistemului TeX/LaTeX) - aceasta însemnând în primul rând (cum am constatat concret) că literele româneşti "obişnuite" vor trebui înlocuite prin comenzile specifice TeX pentru "litere cu accent".
Chit că nu-i "mare scofală" (dar sunt de explicat unele aspecte), să arăt aici cam cum am procedat.
Bineînţeles că întâi am creat un director de lucru, în care am copiat fişierul HTML iniţial:
vb@Home:~/4_art$ mkdir 4; cd 4 vb@Home:~/4_art/4$ cp ~/LAST/body.html .
Apoi am folosit Pandoc, pentru a converti din "html" (plus notaţie matematică delimitată de '$') în "latex":
vb@Home:~/4_art$ pandoc -f html+tex_math_dollars -t latex body.html > body.tex
Răsfoind fişierul TeX obţinut, constat că pandoc a înlocuit '$' (pe care - când am inclus mathJax în fişierul HTML - îl setasem drept delimitator pentru expresiile matematice) cu marcarea (deasemenea obişnuită în LaTeX) "\( ... \)"; de exemplu, pentru $\frac{x^2}{a^2}+\frac{y^2}{b^2}=1$ avem:
$\frac{x^2}{a^2}+\frac{y^2}{b^2}=1$ % notaţia din "body.html"
\(\frac{x^2}{a^2}+\frac{y^2}{b^2}=1\) % notaţia rezultată în "body.tex"
Fiindcă m-am obişnuit să delimitez cu '$', o să revin la notaţia iniţială (nu văd motive ca MikTex să nu o accepte). Desigur, pentru a înlocui o secvenţă de caractere printr-o alta putem folosi chiar meniul "Find and Replace" din gedit, dar prefer să cunosc şi să folosesc comanda "obişnuită" (indispensabilă, dacă ai de făcut substituţia respectivă nu în fişierul deschis în editor, ci într-un anumit grup de fişiere):
vb@Home:~/4_art/4$ perl -p -i -e 's/\\\((.*?)\\\)/\$$1\$/g' body.tex
s/.../.../g substituie prima expresie ("...") cu a doua, în tot fişierul (fiind prezent modificatorul /g, pentru "global"); în cadrul expresiilor respective, caracterele \, (, ) şi $ trebuie "scăpate" de semnificaţia specială pe care o au, prefixându-le cu '\'. Paranteza "(.*?)" grupează toate caracterele cuprinse între delimitatorii "\(" şi "\)" şi grupul respectiv este referit în cadrul celei de-a doua expresii prin "$1" (aici '$' nu mai este "escapat", păstrând astfel semnificaţia specială de a referi prima subexpresie parantezată din cadrul expresiei de substituit).
Este de subliniat o subtilitate ("obişnuită" când se foloseşte caracterul '$' pe linia de comandă): am încadrat comanda pe care o transmitem interpretorului perl spre execuţie prin apostrofuri şi nu prin ghilimele. Dacă foloseam "s/.../.../g" (încadrând cu ghilimele), atunci caracterul '$' conţinut în expresiile respective era "interpolat" înainte de a ajunge la perl (ceea ce numim "linia de comandă" este de fapt o sesiune de lucru cu "shell"-ul sistemului, sau "interpretorul liniei de comandă" - de obicei, programul bash; ori pentru acesta, '$' are semnificaţia specială de a referi conţinutul unei variabile şi ghilimelele exterioare forţează această interpretare. De exemplu tastând pe linia de comandă a=2; echo "$a", se va afişa 2; tastând echo '$a' se va afişa $a; iar dacă în loc să folosim echo folosim perl, atunci singura schimbare este că bash va transmite către perl, în loc de a afişa pe ecran).
Dar avem şi expresii matematice încadrate prin '$$' (în "body.html"), respectiv (după trecerea prin pandoc) prin '\[...\]' (în "body.tex"); expresia delimitată astfel va apărea la redarea ei, pe un paragraf separat (şi nu într-unul existent). Putem adapta comanda de mai sus (click în terminal, săgeată-sus ca să recuperez linia de comandă anterioară, modific paranteze rotunde şi dublez '\$'), pentru a reveni la notaţia iniţială:
vb@Home:~/4_art/4$ perl -p -i -e 's/\\\[(.*?)\\\]/\$\$$1\$\$/g' body.tex
Să ne ocupăm acum de convertirea literelor româneşti, de la reprezentarea UTF-8 din "body.html" la o reprezentare TeX care să poată fi recunoscută direct (fără a presupune importarea unor pachete specializate) de către MikTex. Dar precizez că pe sistemul meu nu am nevoie să fac această conversie: includ în fişierul LaTeX pachetul fontspec şi compilez cu xelatex (care suportă standardul Unicode şi asumă în mod implicit că fişierul de intrare este codificat în UTF-8).
În sistemul TeX, literele "cu diacritice" fac parte din categoria literelor "accentuate"; acestea sunt produse prin macroul \accent - de exemplu, \accent21 g produce 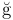 (21 fiind codul în cadrul unui anumit font, al "accentului" adăugat aici deasupra literei 'g'). Pentru a evita necesitatea de a şti codul fiecărui accent, s-au constituit câteva "scurtături"; de exemplu, pentru cazul de aici puteam folosi comanda
(21 fiind codul în cadrul unui anumit font, al "accentului" adăugat aici deasupra literei 'g'). Pentru a evita necesitatea de a şti codul fiecărui accent, s-au constituit câteva "scurtături"; de exemplu, pentru cazul de aici puteam folosi comanda \u{g}.
În următorul script pentru bash, considerăm un tablou asociativ având drept chei literele româneşti şi drept valori comenzile LaTeX cu care trebuie înlocuite; parcurgem cu "for" acest tablou şi pentru fiecare cheie invocăm ca şi mai sus perl -pie pentru a face înlocuirea corespunzătoare acesteia:
#!/bin/bash f=body.tex declare -A romletter=(["ă"]="\\\\u\\{a\\}" ["Ă"]="\\\\u\\{A\\}" ["ş"]="\\\\c\\{s\\}" ["Ş"]="\\\\c\\{S\\}" ["ţ"]="\\\\c\\{t\\}" ["Ţ"]="\\\\c\\{T\\}" ["â"]="\\\\^\\{a\\}" ["Â"]="\\\\^\\{A\\}" ["î"]="\\\\^\\{i\\}" ["Î"]="\\\\^\\{I\\}" ) for rol in "${!romletter[@]}"; do perl -p -i -e "s/$rol/${romletter[$rol]}/g" $f; done
Aici, şabloanele de forma ""\\\\u\\{a\\}" conţin perechi de caractere backslash - primul va fi "consumat" de bash, iar al doilea va fi transmis lui perl (încât în final va rezulta "\u{a}" - comanda TeX care va produce "ă"). Să mai observăm că acum am folosit ghilimele pentru a încadra expresia de substituire transmisă lui perl (pentru ca bash să înlocuiască variabilele prefixate cu '$' prin conţinuturile acestora - operaţie denumită "interpolare").
Desigur, acest script (să-i zicem "ro2tex.sh") trebuie setat ca "fişier executabil" (prin comanda chmod +x ro2tex.sh) şi apoi poate fi lansat de pe linia de comandă prin ./ro2tex.sh.
În urma transformărilor de mai sus, "body.tex" va deveni accesibil în MikTex (fără a mai fi nevoie de dactilografierea manuală a literelor sau "scurtăturilor" de comenzi TeX); iar pe sistemul meu este suficient să folosesc pdflatex (în loc de xelatex), pentru a obţine fişierul PDF corect (dar bineînţeles că eu voi continua să folosesc xelatex şi UTF-8 şi numai în final, când eventual aş zice că ar fi ceva de transmis redacţiei revistei - aş opera transformările indicate).
vezi Cărţile mele (de programare)