De la orarele individuale, la tabelul de încadrare
Pe unele site-uri de şcoală, orarul – semnat de aScTimeTables.com – apare cam aşa:
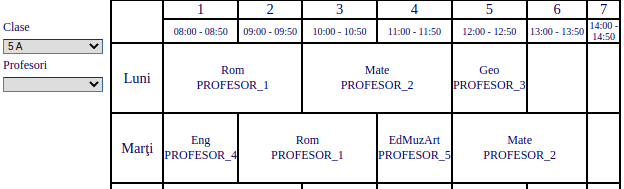
Poţi alege o clasă, respectiv un profesor şi obţii orarul (individual) corespunzător.
Mai precis, cele două elemente HTML <select> conţin opţiuni ca
<option value="teacher_008.html"> PROFESOR_2 </option>
şi analog pentru clase: value="form_003.html"> 6 B </option>
şi au setat câte un eveniment onchange care produce – prin window.open() – pagina *.html indicată în atributul value al opţiunii selectate.
Pagina „de bază” /index.html produce orarul clasei 5A (pe imaginea redată mai sus am omis titlul "Clasa: 5 A"); pagina /form_001.html produce orarul clasei 5B, ş.a.m.d.
Toate paginile "form_001.html", ..., "form_034.html" – care dau orarele claselor – şi "teacher_000.html", ..., "teacher_068.html" (pentru orarele profesorilor), au conţinut identic cu pagina de bază până în punctul în care apare orarul corespunzător opţiunii selectate – în particular, toate prevăd cele două elemente <select>; în plus, pe fiecare pagină este prevăzut un link către "Pagina următoare".
Se subânţelege că toate aceste pagini nu au fost formulate manual, ci au fost fireşte generate în prealabil, printr-un anumit program (probabil, din aScTimeTables).
Ceea ce ne-a atras atenţia în orarul evocat parţial mai sus este „înghesuirea” orelor (încât, probabil că mai fiecare profesor are măcar câte o zi liberă şi în plus, nimeni nu are ferestre): cele 4 ore de "Română", sau de "Matematică" se fac în câte două zile, cam la toate clasele; cele 2 ore de "Biologie" sau de "Geografie", sau "Franceză", "Educaţie Fizică" etc. se fac în câte o singură zi; în plus, unele clase au 7 ore într-o zi şi au doar 4, într-o altă zi.
Probabil că aşa s-o fi convenit de la bun început (avantajând cumva, profesorii)…
Însă în principiu, pentru a asigura condiții propice desfășurării fluente a procesului de învățare în care sunt implicați elevii școlii – se clamează că lecțiile trebuie distribuite cât mai uniform pe zile, profesori, clase și obiecte (chiar şi cu „riscul” de a apărea ferestre, pe lângă ignorarea unor „nazuri” individuale).
Ne propunem ca, plecând de la aceste fişiere *.html, să constituim un set de date coerent – permiţând de exemplu, să formulăm „tabelul de încadrare” (fundamentul pe care se va putea genera un orar sau altul, depinzând în primul rând de principiile adoptate pentru alocarea lecţiilor pe zile şi ore).
Obţinerea, reducerea şi curăţarea fişierelor
Desigur, din browser (prin click-dreapta şi "Save As...") poţi obţine doar pagina afişată curent pe ecran (eventual, "Web Page complete")…
Dar putem obţine imediat cele 35+69 de fişiere .html de pe site-ul orarului, folosind wget (de exemplu); ţinem seama de link-ul care leagă o pagină de următoarea (de exemplu, în "teacher_055.html" apare <a href="teacher_056.html">Pagina următoare</a>) şi folosim opţiunea "-r" (sau "--recursive") pentru a obţine toate paginile astfel legate una de alta (dar avem de specificat şi "-l depth", unde "depth" induce numărul de legături):
vb@Home:~/22mar/CNIV$ wget -r -l 123 http://orar.ienachita.com/
Nota Bene. Da… orarul de pe care ne inspirăm aici este preluat (în martie 2022) de pe site-ul Colegiului Naţional „Ienăchiţă Văcărescu” //www.ienachita.com.
Dar modalitatea de prezentare a orarului evocată mai sus apare şi pe alte site-uri de şcoală.
Prin comanda redată mai sus, în subdirectorul CNIV/orar.ienachita.com/ obţinem 105 fişiere; nu ne interesează fişierul ".css" şi îl eliminăm; iar "index.html" – care de fapt conţine orarul clasei 5A – îl redenumim "form_000.html".
Din fiecare fişier "*_0NN.html" ne interesează numai elementul <table> care conţine orarul clasei sau profesorului – iar tabelul respectiv este precedat de un element <h1> care conţine numele clasei/profesorului; deci, formulând ca expresie regulată, ne interesează numai fragmentul '<h1.+</table>'.
De fapt, specificatorul ".+" reprezintă o secvenţă arbitrară de caractere, dar diferite de '\n' – ori fragmentul de text HTML vizat mai sus conţine mai multe linii de text (separate prin '\n'); pentru a evita problemele, preferăm să eliminăm din start caracterele de „sfârşit de linie” (înlocuindu-le de exemplu cu spaţiu obişnuit) şi atunci fragmentul care ne interesează (fiind acum o singură linie de text) este descris într-adevăr, prin '<h1.+</table>' şi poate fi extras prin grep -o:
#! /bin/bash cd orar.ienachita.com for f in $(ls) do perl -p -e 's/\n/ /' $f | grep -o -P '<h1.+</table>' done
Salvăm programul Bash redat mai sus în CNIV/, îi setăm bitul de mod „executabil” şi îl lansăm, redirectând ieşirea pe un fişier:
vb@Home:~/22mar/CNIV$ chmod +x getor.sh vb@Home:~/22mar/CNIV$ ./getor.sh > cniv.html
În cniv.html avem acum (pe aproape 380 KiB) toate orarele claselor şi profesorilor, reprezentate prin tabele HTML precedate fiecare de câte un element <h1> care conţine numele clasei/profesorului.
Dar nu ne interesează să afişăm orarul (putem deschide într-un browser cniv.html, deşi este numai un fragment HTML) şi nici să-l printăm; adică, nu ne interesează atributele de aliniere, dimensionare şi poziţionare (ca align="center", valign="middle", width="14%", height="70"), nici atributele de font sau de bordare. Ceea ce ne interesează sunt datele propriu-zise – clasa, profesorul, obiectul, ziua şi ora în care se desfăşoară lecţia.
Dintre toate numeroasele atribute de pe elementele <h1>, <table> şi <td>, am avea de reţinut unul singur: <td colspan="2"> – indicând că lecţia respectivă este alocată în două ore (coloane) consecutive; folosind facilităţile de căutare ale unui editor de text (gedit), putem constata că există foarte multe lecţii care se desfăşoară în câte două ore (iar câteva lecţii se desfăşoară în câte 3 ore consecutive).
Dar măcar acum, să observăm că nu avem nevoie şi de orarele claselor şi de orarele profesorilor… Programul Bash redat mai sus a prelucrat fişierele respective în ordinea alfabetică a numelor acestora (cum rezultă prin comanda ls implicată în program), deci este uşor să identificăm în "cniv.html" linia la care încep tabelele corespunzătoare orarelor profesorilor şi să extragem aceste tabele, într-un fişier nou, "cniv2.html" (desigur şi mai simplu era să fi utilizat de la bun început numai fişierele "teacher_0NN.html").
Separând astfel lucrurile, putem preciza exact câte lecţii se desfăşoară pe câte două sau pe câte trei ore consecutive (la câte o aceeaşi clasă): în "cniv2.html" avem 277 de apariţii <td colspan="2"> şi 10 apariţii cu colspan="3".
Lecţiile sunt reprezentate sub forma "BIOLOGIE<br>12 H" (încât conţinutul elementului <td> să fie redat pe două rânduri: obiectul şi dedesubt, clasa); înlocuim peste tot <br> cu spaţiu şi eliminăm spaţiul din denumirea de clasă:
perl -p -i -e 's/<br>(\d+) (\w)/ $1$2/g' cniv2.html
N-ar fi o idee rea să eliminăm tagurile şi atributele care nu prezintă interes pentru scopul nostru de a extrage datele (iar prin eliminarea acestora, fişierul respectiv şi-ar reduce dimensiunea cam de 5 ori) – dar vom vedea că nu este necesar…
Însă pare necesar – având în vedere că apar taguri (ca <font>) şi atribute care de mult timp nu mai sunt în uz – să ne încredinţăm că fişierul respectiv este valid ca fragment HTML: se ştie că browserele nu prea fac nazuri la redarea unui fişier sau fragment HTML (chiar şi „incorect”), dar programul prin care vom extrage datele poate şi claca, dacă formularea HTML care i se pasează este incorectă.
Am folosit validator.w3.org, dar puteam observa şi direct că "cniv2.html" conţine şi erori probabil importante: gedit ne arată că termenul "<table" apare de 69 de ori, iar tagul-pereche "</table>" apare de 138 de ori; altfel spus, structura care conţine orarul unui profesor începe cu "<table fel_de_fel_de_atribute>" şi se încheie cu două elemente "</table>" (ca şi când ar fi un tabel într-un altul – dar nu este):
<table width = "100%" border="1" bordercolor="#808080" cellspacing="0" cellpadding="0"> <!-- elemente <tr> şi <td> --> </table> </td></tr> </table>
Am eliminat deci din "cniv2.html", secvenţa "</td></tr> </table>" (şi ca urmare, fişierul respectiv este deschis în browser cam de două ori mai repede… Browserul nu te pedepseşte dacă greşeşti HTML, dar pierde totuşi timp ca să decidă cum să interpreteze un cod greşit).
Acum, după corecturile descrise mai sus, putem trece la adevărata problemă…
Extragerea datelor din HTML, în seturi de date ("data.frame")
„Dialectul” R tidyverse conţine şi pachetul rvest, prin care este foarte uşor să obţinem într-un obiect de tip "data.frame", datele existente pe liniile <tr> şi coloanele <td> ale unui tabel HTML.
Dar tot mai trebuie o operaţie preliminară, pentru a monta un antet corect pe tabelele din "cniv2.html"; antetele originale folosesc "<td>", nu <th> şi au două rânduri: primul rând indică "Ziua" şi rangul 1..7 al orei, iar al doilea indică intervalul orar corespunzător ("08:00-08:50", etc.) – păstrăm numai primul rând, înlocuind "<td>" cu "<th>" (după ce, în plus, eliminăm "rowspan=2" din "<td rowspan="2">Ziua:</td>").
Să mai facem şi această simplificare: înlocuim "Ziua:" cu "zi" şi zilele "Luni", "Marţi" etc. cu "Lu", "Ma", "Mi", etc.
Prin următorul program R extragem numele din elementele "<h1>" şi datele din tabelele HTML existente în "cniv2.html" şi constituim o listă conţinând ca obiecte "data.frame", orarele profesorilor:
library(tidyverse) library(rvest) html <- read_html("cniv2.html", encoding="utf-8") Profs <- html %>% html_nodes("h1") %>% html_text() # numele profesorilor lDF <- html %>% html_nodes("table") %>% html_table(fill = TRUE) # orarele profesorilor names(lDF) <- Profs
Să inspectăm un element al listei rezultate prin execuţia programului:
> lDF[[3]] zi 1 2 3 4 5 6 7 1 Lu Fiz 10G Fiz 10G Fiz 10B Fiz 10B Fiz 12C Fiz 12C NA 2 Ma NA 3 Mi Fiz 7A Fiz 7A Fiz 9G Fiz 10B NA 4 Jo NA 5 Vi Fiz 9G Fiz 9G Fiz 12C Fiz 10G Fiz 10D Fiz 10D NA
Numele profesorului este înregistrat în vectorul names(lDF), la indexul 3.
De observat că rvest::html_table() a interpretat "colspan=2" prin multiplicarea conţinutului din <td>-ul respectiv; de exemplu, cele 3 ore de "Fiz" la 10G se fac în primele două ore din ziua "Lu" şi în ora 4 din ziua "Vi".
Profesorul respectiv are în total 16 ore de "Fizică" şi le face în 3 zile; orele libere sunt reprezentate prin câte un „şir vid” "", sau prin constanta logică NA (care indică lipsa; de exemplu, în coloana '7' nu avem nicio lecţie).
Comasarea şi restructurarea datelor
Acum, să observăm că nu avem un set de date, ci avem o listă lDF de „seturi de date”; ce vrem de fapt, ar fi un singur obiect "data.frame" – să-i zicem "DF" – care să conţină toate orarele profesorilor, dar cu o structură aşa de simplă încât ulterior, să putem investiga uşor orice aspect privitor la datele respective.
Desigur, în DF trebuie să integrăm şi numele profesorilor (preluându-le prin names(lDF), sau direct din vectorul Profs) – iar pe de altă parte, avem de anonimizat cumva aceste nume: le vom înlocui prin "pNN" unde "NN" să fie indexul fiecăruia într-un „vector cu nume” ordonat descrescător după numărul de ore pe săptămână ale profesorilor.
În următoarea secvenţă de program (continuând pe cel început mai sus), determinăm întâi numărul de ore ale fiecărui profesor – numărând valorile „nenule” (diferite de "" şi de NA) din setul "data.frame" asociat lui în lista lDF – şi ordonăm descrescător „dicţionarul” profesor→număr_ore care se obţine (în R este numit "vector cu nume"); apoi, ordonăm lista lDF după numele acestui dicţionar:
by_h <- sapply(lDF, function(orr) sum(! is.na(orr[, 2:8]) & orr[, 2:8] != "") ) %>% sort(decreasing = TRUE) lDF <- lDF[names(by_h)]
Acum, orarele din lDF stau în ordinea descrescătoare a numărului de ore; este de subliniat că vectorul names(lDF) a fost automat ajustat pentru a reflecta noua ordine.
S-ar putea ca la sfârşitul lui lDF să avem orare „vide” (conţinând NA în toate coloanele 2:8) – putem verifica direct din consolă:
> sapply(seq_along(lDF), function(i) all( is.na(lDF[[i]][, 2:8])) ) [1] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE # ... [61] FALSE FALSE FALSE FALSE FALSE FALSE FALSE TRUE TRUE
Deci până la urmă, profesorii de indecşi 68 şi 69 nu au mai primit ore în şcoala respectivă (şi ca de obicei, s-a uitat că ei n-ar trebui să mai apară în orar); aici fireşte că îi eliminăm din lDF, adăugând în program:
lDF[68:69] <- NULL
Acum concatenăm toate orarele din lDF într-un singur "data.frame", integrând şi o coloană cu numele profesorilor – după transformarea acestora în "pNN":
Pnn <- c(paste0("p0", 1:9), paste0("p", 10:67)) # p01, p02, ..., p66, p67 DF <- map_df(seq_along(lDF), function(i) lDF[[i]] %>% mutate(prof = Pnn[i], .before = 1) )
Să inspectăm din consolă, structura de date rezultată:
> str(DF) 'data.frame': 335 obs. of 9 variables: $ prof: chr "p01" "p01" "p01" "p01" ... $ zi : chr "Lu" "Ma" "Mi" "Jo" ... $ 1 : chr "BIOLOGIE 9B" "BIOLOGIE 11C" "BIOLOGIE 9B" "BIOLOGIE 7A" ... $ 2 : chr "BIOLOGIE 9D" "BIOLOGIE 10G" "BIOLOGIE 9E" "BIOLOGIE 8A" ... $ 3 : chr "BIOLOGIE 12G" "BIOLOGIE 10G" "BIOLOGIE 7A" "BIOLOGIE 9A" ... $ 4 : chr "BIOLOGIE 12G" "BIOLOGIE 10C" "BIOLOGIE 10D" "BIOLOGIE 5A" ... $ 5 : chr "" "BIOLOGIE 10C" "" "BIOLOGIE 12H" ... $ 6 : chr "BIOLOGIE 12H" "BIOLOGIE 12C" "" "BIOLOGIE 12H" ... $ 7 : chr "BIOLOGIE 9A" "" "" "" ...
Avem 9 coloane (în R – care este un mediu destinat analizei statistice a datelor – se zice "variabile") pe 335 de linii ("observaţii" asupra variabilelor); într-adevăr, pentru fiecare dintre cei 67 de profesori avem câte 5 linii (câte una pentru fiecare zi). În DF s-au concatenat liniile din orarele iniţiale din lDF; deci primele linii din DF corespund profesorului "p01" (care are cel mai multe ore şi face "Biologie"), urmează liniile următorului profesor cu cel mai multe ore, "p02" ş.a.m.d.
Să observăm însă că datele din DF nu sunt „curate”: valorile din coloanele '1':'7' amestecă valori din două variabile independente, anume "obiectul" şi "clasa". În plus, numele de coloană '1':'7' sunt ele însele, valori ale unei aceleiaşi variabile, anume "ora". Pentru a „normaliza” datele, întâi creem variabila "ora" (împreună cu o variabilă temporară "obcl", care preia valorile existente pe coloanele numite '1':'7'):
DF <- DF %>% pivot_longer(cols=3:9, names_to="ora", values_to="obcl") %>% filter(! is.na(obcl) & obcl != "" ) # excludem orele libere > str(DF) # inspectăm din consolă tibble [1,035 × 4] (S3: tbl_df/tbl/data.frame) $ prof: chr [1:1035] "p01" "p01" "p01" "p01" ... $ zi : chr [1:1035] "Lu" "Lu" "Lu" "Lu" ... $ ora : chr [1:1035] "1" "2" "3" "4" ... $ obcl: chr [1:1035] "BIOLOGIE 9B" "BIOLOGIE 9D" "BIOLOGIE 12G" "BIOLOGIE 12G" ...
Bineînţeles că am eliminat orele libere, încât dintre cele 67×35=2345 valori câte erau înainte de filter(), ne-au rămas 1035 (mai puţin de jumătate).
Acum, având într-o aceeaşi coloană obcl, toate valorile "obiect clasă", le putem separa în două variabile, obj şi cls – şi la prima vedere ar fi simplu, "obiect" fiind separat de "clasă" printr-un spaţiu.
Numai că se poate ca spaţiu să apară şi în denumirea de "obiect" (de exemplu, răsfoind puţin prin DF, găsim "Educatie Financiara 11F"); mai mult, "clasă" ar putea desemna mai multe clase – găsim de exemplu, "Des/Muz 9A, 9 B" în care "clasă" este "9A, 9 B" (aaa… încă va trebui să corijăm notarea claselor, preferând "9B" în loc de "9 B").
Analizând aceste situaţii, concluzionăm că separatorul între "obiect" şi "clasă" trebuie să fie indicat ca "spaţiu neprecedat (?<!) de virgulă şi neurmat (?!) de literă":
DF <- DF %>% separate(col = "obcl", into = c("obj", "cls"), sep = "(?<!,)[[:space:]](?![[:alpha:]])") > str(DF) # inspectăm din consolă tibble [1,035 × 5] (S3: tbl_df/tbl/data.frame) $ prof: chr [1:1035] "p01" "p01" "p01" "p01" ... $ zi : chr [1:1035] "Lu" "Lu" "Lu" "Lu" ... $ ora : chr [1:1035] "1" "2" "3" "4" ... $ obj : chr [1:1035] "BIOLOGIE" "BIOLOGIE" "BIOLOGIE" "BIOLOGIE" ... $ cls : chr [1:1035] "9B" "9D" "12G" "12G" ...
Rămâne să vedem mai încolo, ce sens are o „clasă” ca "9A, 9B".
Acum DF conţine toate datele orarului (şi numai datele respective) şi ar intra în categoria „bază de date normalizată” (fiecare valoare – exceptând deocamdată, valori ca "9A, 9B" – este una dintre valorile posibile ale uneia anumite dintr-un număr de variabile independente date); orice investigaţie dorim, va decurge folosind operaţii de filtrare (pentru linii) şi de selectare (pentru coloane) – iar pentru facilitare, putem transforma o coloană sau alta în factor (analog cu tipul de date "enumerated" sau "enum" din alte limbaje), ceea ce asigură şi operaţii de grupare (şi „splitare”).
Depistarea şi modelarea cuplajelor
Pot exista profesori pentru care găsim valori identice în coloanele zi, ora şi cls: în acea zi şi oră, clasa respectivă este împărţită în grupe şi fiecare profesor intră la câte una dintre grupe – fiind vorba de obicei, de două grupe şi doi profesori. Sau, pot exista cuplaje de clase (de obicei, două clase): într-o anumită zi şi oră, doi profesori intră fiecare la câte o „nouă” clasă, formată prin reunirea unei grupe de la prima clasă cu una de la a doua clasă (sau intră la câte o clasă dintre cele două).
Este de bănuit că notaţia evidenţiată mai sus "Des/Muz 9A, 9 B" semnifică un cuplaj de clase (într-o anumită zi şi oră) – dar probabil că nu împărţind clasele în grupe, ci mai simplu, ţinând seama de aspectul contextual că obiectele "Desen" şi "Muzică" au alocate de obicei numai câte o jumătate de oră pe săptămână (ceea ce ar echivala cu o oră la două săptămâni): în săptămânile de rang impar 9A face "Des" şi 9B face "Muz", iar în cele de rang par – invers.
Salvăm pentru orice eventualitate, setul DF constituit mai sus şi căutăm să evidenţiem cuplajele existente. Mai întâi, convertim coloana prof în factor; iniţial, în prof aveam numele profesorilor – fiecare fiind repetat după numărul de ore pe săptămână ale profesorului respectiv; ca factor, în coloana prof se vor înregistra indecşii din vectorul dat de levels(prof), care conţine numele unice ale profesorilor, într-o ordine fixată (în loc de nume, se vor repeta indecşii).
Apoi, putem folosi split(); prin split(list(<coloane>)) separăm liniile în obiecte "tibble" care conţin fiecare, linii cu aceleaşi valori în coloanele indicate; cuplajele vor corespunde acelora dintre obiectele listei obţinute, care au cel puţin două linii (pe care diferă numai profesorul, sau/şi obiectul):
saveRDS(DF, file="DF.rds") DF$prof <- factor(DF$prof, ordered = TRUE) cpl <- DF %>% split(list(.$zi, .$ora, .$cls)) cpl <- map(seq_along(cpl), function(i) if(nrow(cpl[[i]]) > 1) cpl[[i]]) %>% compact() # elimină din listă valorile 'NULL'
map() a parcurs după indici lista returnată de split() şi a returnat o listă de aceeaşi lungime, înscriind NULL pentru obiectele excluse (cele cu un singur rând); redăm şi interpretăm două dintre elementele acestei liste (cu observaţia că afişarea pe ecran implică automat numele din levels(prof), în locul indecşilor interni):
cpl[[1]] # A tibble: 2 x 5 cpl[[3]] # A tibble: 2 x 5 prof zi ora obj cls prof zi ora obj cls 1 p06 Jo 1 Des/Muz 10A, 10 B 1 p26 Jo 1 Eng 10E 2 p15 Jo 1 Des/Muz 10A, 10 B 2 p42 Jo 1 Eng 10E
p26 şi p42 intră "Jo" ora 1, la câte o grupă a clasei 10E – făcând câte o lecţie de "Eng" (probabil, cu „avansaţi” şi respectiv, „începători”).
p06 şi p15 intră "Jo" ora 1, la clasa 10A şi respectiv, 10B – sau invers, în săptămâna următoare – pentru o lecţie de "Des" şi respectiv "Muz".
În primul caz (cpl[[3]]) vorbim de un „cuplaj de profesori” şi pentru a evita aspectul de suprapunere indus de identitatea valorilor din coloanele zi, ora şi cls – înfiinţăm un „profesor fictiv”, ca p26p42, care să preia ora comună a celor doi.
În celălalt caz, vorbim de un „cuplaj de clase” şi pentru a evita suprapunerea de date, fixăm o clasă unuia şi cealaltă clasă celuilalt profesor – urmând ca la construcţia orarului să plasăm cele două clase într-o aceeaşi zi şi oră, celor doi profesori.
Transformăm lista 'cpl' într-un tibble care conţine pe fiecare linie un vector de profesori (convertind prin as.character(), întregii asociaţi acestora prin factor-ul 'prof' şi apoi, alipind numele), clasa şi numărul de ore pe care aceştia sunt cuplaţi:
cpl <- map_df(seq_along(cpl), function(i) tibble(cup = paste(c(as.character(cpl[[i]]$prof)), collapse = ""), cls = cpl[[i]]$cls[1])) %>% count(cup, cls) # A tibble: 11 x 3 cup cls n cup cls n 1 p06p15 10A, 10 B 1 7 p26p42 10E 5 2 p06p15 10C, 10 D 1 8 p27p35 12E 5 3 p06p15 10E, 10 F 1 9 p30p31 11E 5 4 p06p15 10G 1 10 p30p31 9E 5 5 p06p15 9A, 9 B 1 11 p30p42 9A 4 6 p06p15 9C, 9 G 1
Se vede că 10G nu a putut fi cuplată cu o altă clasă, încât la 10G cei doi profesori vor face ora ("Des" şi respectiv "Muz") cu câte o jumătate de clasă (schimbând jumătăţile, în săptămâna următoare).
Avem 6 cuplaje de profesori (deci 6 profesori „fictivi”) şi 5 perechi de clase cuplate; de exemplu, profesorul fictiv p30p31 va prelua cele 10 ore partajate de profesorii p30 şi p31 la clasele 11E şi 9E – cu alte cuvinte, avem de eliminat din DF câte 5 ore la clasele 11E şi 9E ale profesorilor p30 şi p31, înscriindu-le profesorului fictiv p30p31, pe care trebuie să-l adăugăm în DF. Şi avem de înlocuit "10A, 10 B" cu "10A" la p06 şi cu 10B la p15 – şi analog, pentru celelalte perechi de clase cuplate (dar va trebui să nu uităm nici un moment, de aceste perechi de clase…).
Să explicităm întâi, din cpl, vectorul celor 5 perechi de clase:
twins <- cpl %>% filter(nchar(cls) > 3) %>% pull(cls) # chr [1:5] "10A, 10 B" "10C, 10 D" "10E, 10 F" "9A, 9 B" "9C, 9 G"
şi să înlocuim apariţiile acestora la p06 şi p15, cum am precizat mai sus:
DF <- DF %>% mutate(cls = ifelse(cls %in% twins, ifelse(prof == "p06", str_extract(cls, "\\w+"), # "10A" etc. la p06 str_replace_all(str_extract(cls, " \\d+ \\w+"), # " 10 B" " ", "") # "10B" (fără spaţii) la p15 ), cls) )
Acum, în DF, primele clase din cele 5 cuplaje de clase apar la p06, iar ultimele apar la p15. Putem verifica şi clasele (nu mai apar perechi), în număr de 35:
> unique(DF$cls) %>% sort() [1] "10A" "10B" "10C" "10D" "10E" "10F" "10G" "11A" "11B" "11C" "11D" "11E" [13] "11F" "11G" "12A" "12B" "12C" "12D" "12E" "12F" "12G" "12H" "5A" "5B" [25] "6A" "6B" "7A" "8A" "9A" "9B" "9C" "9D" "9E" "9F" "9G"
Bineînţeles că salvăm DF, astfel modificat, din nou în "DF.rds".
Integrarea profesorilor fictivi
Să ne ocupăm acum şi de cuplajele de profesori; le extragem întâi, din cpl:
twns <- cpl %>% filter(nchar(cls) <= 3) cup cls n 1 p06p15 10G 1 2 p26p42 10E 5 3 p27p35 12E 5 4 p30p31 11E 5 5 p30p31 9E 5 6 p30p42 9A 4
Ca idee (exemplificând pentru linia 2), depistăm liniile din setul DF pe care în coloana prof apare p26 sau p42 şi în coloana cls apare 10E, iar pe acele dintre aceste linii care au câte o aceeaşi valoare în câmpurile zi şi ora, înscriem ca „profesor” (fictiv) "p26p42"; să observăm că astfel, vor fi afectate 2×5 linii – deci mai trebuie să şi eliminăm 5 dintre acestea.
La implementarea acestei idei avem de ţinut seama de faptul că variabila DF$prof este deja de tip factor ordonat (şi am avea de modificat nivelele deja stabilite ale acestuia); noi preferăm să folosim operaţii generale "_join()", care dacă este cazul, transformă în mod implicit tipurile de date (în loc de "factor" <ord> vom avea <chr>).
Înfiinţăm întâi o funcţie prin care să desprindem profesorii implicaţi într-un cuplaj:
split_twin <- function(cup) # extrage profesorii din cuplaj strsplit(cup, "(?<=.{3})", perl=TRUE)[[1]]
Șablonul de expresie regulată "(?<=.{3})" (positive lookbehind) operează astfel,
asupra șirului dat: avansează până ce în spate rămân 3 caractere, le produce și
apoi repetă din noua poziție curentă; split_twin("xyzuvwabcd") de exemplu,
ne dă vectorul format din "xyz", "uvw", "abc" și restul "d".
Subliniem că fără operatorul de selectare final ’[[’, funcția de mai sus producea nu un vector, ci o listă care conține vectorul respectiv.
Pentru o linie indicată din twns, următoarea funcţie produce un tabel tibble care conţine cele 2×n linii – unde n este valoarea din coloana twns$n – din DF, descrise mai sus (şi îi adăugăm o coloană de cuplare):
trace_twn <- function(i) { pr <- split_twin(as.character(twns[i, 1])) cl <- twns[i, 2] ls2 <- DF %>% filter(cls %in% cl & prof %in% pr) %>% split(list(.$zi, .$ora)) trc <- map_df(seq_along(ls2), function(j) if(nrow(ls2[[j]]) > 1) ls2[[j]]) trc %>% mutate(twns[i, 1]) # înscrie profesorul fictiv, pe o nouă coloană } # de exemplu: print(trace_twn(6)) prof zi ora obj cls cup 1 p30 Ma 1 Eng 9A p30p42 2 p42 Ma 1 Eng 9A p30p42 3 p30 Ma 2 Eng 9A p30p42 4 p42 Ma 2 Eng 9A p30p42 5 p30 Jo 4 Eng 9A p30p42 6 p42 Jo 4 Eng 9A p30p42 7 p30 Jo 5 Eng 9A p30p42 8 p42 Jo 5 Eng 9A p30p42
Dintre cele 2×n linii apărute la profesorul fictiv, vor trebui păstrate numai n ("p30p42" apare pe 8 linii, dar sunt numai 4 ore în cuplajul pe clasa 9A al celor doi profesori – anume, "Ma" ora 1 şi 2 şi "Jo" ora 4 şi 5).
Aplicăm trace_twn() tuturor liniilor din twns şi reunim prin map_df() tabelele rezultate, obţinând obiectul tibble del; prin anti_join(), eliminăm din DF liniile aduse în del (ignorând câmpul final del$cup), apoi înlocuim valorile din del$prof cu acelea din del$cup şi eliminăm coloana del$cup; în final, prin full_join() adăugăm în DF liniile din del şi prin distinct() eliminăm liniile duble (încât din fiecare 2×n linii care înregistrau orele cuplate în del, rămân n linii):
del <- map_df(1:nrow(twns), trace_twn) # ; print(del) DF <- anti_join(DF, del[-6]) # implicit, factorul $prof este degradat la <chr> del$prof <- del$cup # fixează profesorii fictivi pe orele cuplate del$cup <- NULL DF <- full_join(DF, del) %>% distinct() # DF %>% print(n=Inf)
Având şi profesorii fictivi în DF, să convertim prof iarăşi în factor ordonat (descrescător după numărul de ore); pentru aceasta, folosim table() – care în cazul de faţă, contorizează liniile pe care apare în DF fiecare profesor:
srt <- sort(table(DF$prof), decreasing=TRUE) DF$prof <- factor(DF$prof, levels = names(srt), ordered=TRUE) DF <- DF %>% arrange(prof) saveRDS(DF, file = "cniv.RDS")
În final, în DF (salvat în "cniv.RDS") avem 1010 linii de date, pentru cele 5 variabile (dintre care, prof este factor ordonat); redăm şi o selecţie aleatorie de 5 linii (între care şi una corespunzătoare unuia dintre profesorii fictivi):
> str(DF) # inspectăm din consolă tibble [1010 × 5] (S3: tbl_df/tbl/data.frame) $ prof: Ord.factor w/ 72 levels "p01"<"p02"<"p03"<..: 1 1 1 1 1 1 1 1 1 1 ... $ zi : chr [1:1010] "Lu" "Lu" "Lu" "Lu" ... $ ora : chr [1:1010] "1" "2" "3" "4" ... $ obj : chr [1:1010] "BIOLOGIE" "BIOLOGIE" "BIOLOGIE" "BIOLOGIE" ... $ cls : chr [1:1010] "9B" "9D" "12G" "12G" ... > print(slice_sample(DF, n=5)) # A tibble: 5 x 5 prof zi ora obj cls 1 p30p31 Mi 3 Eng 11E 2 p13 Ma 3 Mate 7A 3 p05 Lu 6 Cons 6A 4 p11 Ma 4 Istoria com 12D 5 p14 Jo 3 EdFiz 5A
Poate că vom face un alt orar pe datele din DF – încercând o repartizare echilibrată a lecţiilor; avem vechiul orar în "cniv.RDS" (păstrând posibilitatea unor alte investigaţii ulterioare asupra acestuia), iar în intenţia lucrului la un nou orar, eliminăm coloanele zi şi ora ale vechiului orar şi salvăm în "DF.rds":
DF <- DF %>% select(prof, cls, obj) saveRDS(DF, file = "DF.rds") # 1010 linii prof|cls|obj
Să observăm că pentru a repartiza lecţiile pe zile şi ore (generând alte orare posibile) nu avem nevoie nici de coloana "obj" – totuşi am păstrat-o, vrând deocamdată să producem nu vreun alt orar, ci doar un "tabel de încadrare" (în care s-ar cuveni să figureze şi obiectele).
Simplificarea denumirii obiectelor
În cataloagele şcolare ale claselor, fiecărui obiect de studiu îi corespunde câte o rubrică (pentru a înregistra zilnic, notele şi absenţele elevilor) şi regula este de a înregistra denumirea oficială (oricât ar fi de lungă) a obiectului, pe fiecare pagină de câte trei elevi; pe orar se folosesc fireşte, abrevieri (dar cât mai sugestive) ale denumirilor.
În catalogul unei clase apar mai puţin de 20 de obiecte, dar în orarul şcolii apar obiectele de la toate clasele (cu diverse „profile”) şi în total pot fi şi 100 de obiecte. Ar trebui denumite desigur toate obiectele, iar abrevierea denumirilor ar trebui să păstreze cumva un acelaşi tipar.
În cazul orarului de faţă, obiectele sunt denumite ad-hoc, respectând parţial un şablon unitar; întâlnim "Geo", "Fiz", "Lat" (ceea ce este foarte bine, pentru "Geografie", "Fizică", "Latină"), etc. dar şi "BIOLOGIE" (era preferabil "Bio"), "Mate" (de ce nu Mat?), "Istoria com", "Info/Robotica", "Ed_cetatenie_democratica", etc.
Ne gândim să înlocuim aceste denumiri, prin secvenţe de cel mult 5 caractere. Dar bineînţeles că nu vom înlocui în coloana DF$obj, fiecare apariţie a obiectului, cu noua lui denumire… Folosim iarăşi valenţele tipului factor: transformăm $obj în factor, modificăm denumirile în vectorul afişat de levels(obj) şi apoi atribuim vectorul modificat, lui levels(DF$obj):
DF$obj <- factor(DF$obj, ordered=TRUE) lev <- levels(DF$obj) # > str(lev) ##(inspectăm şi modificăm denumirile) # chr [1:45] "ACR" "Astron" "BIOLOGIE" "Chim" "CivEn" "Cons" "Cor" "Des/Muz" ... lev <- c("ACR", "Astr", "Bio", "Chi", "CivEn", "Cons", "Cor", "D1M2", "Econ", "edCD", "edAnt", "edF", "edIC", "edMA", "edPV", "edTh", "edFin" "Eng", "Filo", "Fiz", "Fra", "Geo", "GeoAn", "gâCri", "Gram", "InfL", "InfT", "InfRB", "Ist", "IstAn", "IstCM", "Lat", "LitUn", "Log", "Mat", "Mat1", "opMat", "Patri", "Psi", "Rel", "Rom", "Soc", "Sti", "stSoc", "TIC") levels(DF$obj) <- lev saveRDS(DF, "DF.rds")
"D1M1" ar însemna "Des/Muz", amintind şi alternarea săptămânală a celor două obiecte; "gâCri" e cam urât desigur, dar la fel şi "Gindire Critica" în loc de "Gândire Critică" (pe orarul original nu se folosesc diacritice, nici măcar pentru numele profesorilor). Dar nu ne-am propus aici decât o exemplificare, nu neapărat foarte bună, pentru abrevierea unitară a denumirilor de obiecte (arătând şi cum le redenumim, prin factor); desigur că abrevierea cea mai bună, în orice caz cea mai uniformă, ar fi… "o01", "o02" etc.
Tabelul de încadrare
Tabelul de încadrare conţine toate datele necesare elaborării unui orar, serveşte pentru verificarea corectitudinii orarului şi este uşor de modificat dacă pe parcursul anului şcolar apare necesitarea modificării orarului.
Pentru a fi util, tabelul de încadrare trebuie să fie concis – o coală "A4" ar trebui să fie suficientă pentru a-l reda; trebuie să conţină profesorii, clasele şi numărul de ore pe săptămână ale profesorilor, la clasele respective – cu anumite convenţii simple pentru a evidenţia eventualele cuplaje.
Am exclude obiectele, pentru un motiv simplu: pot fi mai mulţi profesori care fac nu un singur obiect, ci mai multe, la diverse clase – iar în această situaţie tabelul s-ar întinde prea mult (în plus, coloana obj nu este necesară, pentru generarea unui orar).
Din "DF.rds" obţinem matricea de încadrare folosind table():
DF <- readRDS("DF.rds") frm <- addmargins(table(DF[c('prof', 'cls')])) # 'table' int [1:73, 1:36] 2 0 1 0 0 0 3 1 0 0 ... # - attr(*, "dimnames")=List of 2 # ..$ prof: chr [1:73] "p01" "p02" "p03" "p04" ... # ..$ cls : chr [1:36] "10A" "10B" "10C" "10D" ...
Valorile matricei fiind numere întregi (numărul de ore ale profesorilor, la clasele respective) – am putut folosi addmargins(), care a calculat „marginile” matricei (totalurile pe linii şi pe coloane) şi le-a alipit în dreapta (pe o nouă coloană, "Sum") şi dedesubtul matricei (pe o nouă linie, numită "Sum") furnizate de table().
Subliniem că $prof şi $cls sunt atribute ale matricei, notând liniile si coloanele acesteia; de exemplu, prin attr(frm, "dimnames")$cls putem afişa numele coloanelor (numele claselor şi în final, "Sum").
Prin print(frm, width=150) putem afişa imediat matricea de încadrare – dar într-un format neconvenabil (este prea mare spaţiul dintre coloanele); folosind însă cat(), putem reda matricea în ce format dorim.
Pe fiecare nivel (10, 11, 12, 5, 6, etc.), clasele sunt notate cu "A", "B", etc. Vom produce un „antet” conţinând numai literele de clasă, notând nivelele câte o singură dată, deasupra literei "A" – plecând de la:
CLS <- sort(unique(DF$cls)) # 10A 10B ... 10G 11A 11B ... 11G 12A ... 12H 5A ... lCLS <- str_extract(CLS, "[A-Z]") # A B ... G A B ... G A B ... H A B A B ... colnames(frm) <- c(lCLS, "+") # coloana "Sum" devine "+" (un singur caracter) frm[frm == 0] <- '.' # implicit, valorile întregi devin toate, "character"
Următoarea secvenţă scrie (folosind repetat cat()) în fişierul indicat funcţiei sink(), tabelul de încadrare cu antetul specificat mai sus şi cu formatarea intenţionată:
sink("incadrare.txt") cat(" 10___________ 11___________ 12_____________ 5__ 6__ 7 8 9____________\n") cat(" ", colnames(frm), "\n") nr <- nrow(frm) for(i in 1:(nr-1)) { nume <- rownames(frm)[i] wd <- if(nchar(nume)==6) "" else " " cat(nume, wd, frm[i, ], "\n") } cat("Total ") for(i in seq(1, ncol(frm), 2)) cat(frm[nr, i], " ") cat("\n ") for(i in seq(2, ncol(frm), 2)) cat(" ", frm[nr, i]) cat("\n ", colnames(frm), "\n") cat(" 10___________ 11___________ 12_____________ 5__ 6__ 7 8 9____________\n") sink()
10___________ 11___________ 12_____________ 5__ 6__ 7 8 9____________
A B C D E F G A B C D E F G A B C D E F G H A B A B A A A B C D E F G +
p01 2 . 2 1 . 1 2 . . 1 . . . . . . 1 . 1 1 2 3 1 . . . 2 1 2 2 . 1 1 . . 27
p02 . . . . . 2 . 1 1 . 2 2 2 1 . 1 . 3 . 2 . . 1 1 . 1 1 . 1 . 1 . 2 2 . 27
p03 1 5 . . 1 1 . . . 5 . . 2 2 . . . 1 . . . 2 2 . . 1 2 . . . . . . . . 25
p04 . . . . . 2 . 1 . 4 1 . 1 . 3 . 1 . . . . 3 . . . . . 2 . . 3 2 . 2 . 25
p05 . . . . . . 2 4 . . 2 . . . . . . . . 2 2 . . 2 2 . . . . . 4 2 . . 2 24
p07 . . 3 1 . . . . 7 . . . . . . . . . 1 . . . . . . . . . 3 6 . . . 2 1 24
p08 3 . . . . . . . 3 . . 1 1 4 . . . 1 . . 4 . . . 2 . . . . 3 . . 2 . . 24
p06 1 . 1 . 1 . . . . . 1 1 1 . . . . 1 2 2 . . 1 1 1 2 1 1 1 . 1 1 1 1 . 23
p09 . . . . 1 . 2 1 1 . . . . 3 . . 1 . . . 2 2 . . . . 2 . 2 2 . 1 . 1 2 23
p10 . . 3 . . . . . 3 . 4 . 1 . . . . 1 1 . 3 3 . . 4 . . . . . . . . . . 23
p11 . . . . . 3 . 1 . . 4 . 3 . 1 1 1 1 . . . . . 2 1 . . . 1 1 . 2 . . . 22
p12 . . . . . . . . . . . . . . 1 1 1 3 2 2 1 1 . . . . . . 1 1 1 2 2 2 1 22
p13 . . . . . . . . . . . . . . . . 5 . . . . . 4 . . 5 4 . . . 4 . . . . 22
p14 2 2 . . . . . 1 1 . . . . 1 1 . . . . . . . 3 2 2 2 2 . 1 . 1 . . . 1 22
p16 1 . . . 3 . 1 . 1 . . 2 . . . . . . 3 . . . 2 . . 1 2 2 . . 1 . . 2 . 21
p15 . 1 . 1 . 1 . . . . 1 1 . . . . . 1 . 1 . 1 1 2 1 1 1 1 . 1 . 1 1 1 1 20
p17 4 . . 2 . . . . 5 . . . . . . . . . . . . . . . . . . 5 . 4 . . . . . 20
p18 2 . . . 2 2 . 2 . . . . . . . 2 . . . . . . . 2 . 2 . . . 2 2 . 2 . . 20
p19 . . . . . 2 4 . . . . . . . . 4 . 2 . . . 4 . . . . . . 4 . . . . . . 20
p20 . . . . . . 2 . . . . 3 3 2 . . . . . 3 . 2 . . . . . 2 2 . . . . . . 19
p21 . . 4 . . . . 5 . . . . . . 5 . . . . . . . . . 5 . . . . . . . . . . 19
p22 . . . 4 . 4 . . . 3 . . 4 . . . . 3 . . . . . . . . 1 . . . . . . . . 19
p23 1 . . . . . 1 . . . . 1 1 . 1 1 . . 1 . 1 . 1 1 . 1 . 1 1 1 1 1 1 1 1 19
p24 . . . . . 4 . . . 2 3 . . . . 2 . . . 4 . 3 . . . . . . . . . . 1 . . 19
p25 . . . 4 . . . . 2 . . . 3 . 4 . 3 . . . . . . . . 2 . . . . . . . . . 18
p28 . . . . . . . . 2 2 2 . . . 2 . . 2 . . . . 2 . 2 . 2 . . . . 2 . . . 18
p29 . . 2 1 1 1 2 . . 1 1 1 1 . . 1 . 1 1 1 . 1 . . . . . . . 1 . . . 1 . 18
p32 . . . . 2 . . . . . 2 . . . . . . . . . . . . 4 . . . . . . . 2 2 2 4 18
p33 . . . . . . . 3 . . . . . . . . 3 . . . . . . . . . . 4 . 4 . . . . 4 18
p34 . 3 . 2 . . 3 . . . . . . . . . 3 . . . . . . . . . 2 . . . . . . . 3 16
p36 . . . . . . . . . . . . . . . . . . 4 . . . . . . 4 . . . . 4 . 4 . . 16
p37 . 1 1 3 . . . . . 1 . . . 1 . . . 3 . 3 1 1 . . . . . . . . . . . . 1 16
p38 . 4 . . . . . . . 5 . . . 3 . . . . . . 4 . . . . . . . . . . . . . . 16
p39 . 1 1 1 1 1 . 1 1 1 1 . . 1 . . 1 1 . 1 . 1 . . 1 . 1 . . . . . . . . 16
p40 . . . . . . 3 . . . . 5 . . . . . . . . . . 4 . . . 4 . . . . . . . . 16
p41 1 1 1 1 1 1 1 1 . 1 2 1 2 1 . . . . . . . . . . . . . 1 . . . . . . . 16
p43 . . 3 . 2 . . 3 . . . . . . . 3 . . . . . . . . . 2 . . 3 . . . . . . 16
p44 2 2 2 1 . 1 . . . 1 . . . . 1 1 . . . . . . . . . . . 2 . . 2 . 1 . . 16
p45 . . . . . . . . . . . . . . 3 . . . . 5 . . . . . . . . . . . 4 . 4 . 16
p26 . . 2 . . . 4 . . . . 1 . . . . . . . . . . 2 . . . . . . . . 4 . . . 13
p27 4 . . . . . . . . . . . . . . . . 3 . . . . . 2 2 . . 2 . . . . . . . 13
p46 3 3 . . . . . . . . . . . . . 3 . . . . . . . 4 . . . . . . . . . . . 13
p47 . 2 . . . . . 1 1 . . . . . 1 1 . . . . . . . 1 . 2 . . . . 2 . . . 2 13
p48 1 . . . . . . . . . . . . . . 7 4 . . . . . . . . . . . . . . . . . . 12
p49 . . . 1 1 1 . . . . . 2 2 . . . . . 1 1 . . . . . . . . . . . 1 1 1 . 12
p35 . 2 . . . . . 4 . . . . . . . . . . 1 . 4 . . . . . . . . . . . . . . 11
p50 . . . . 4 . . . . . . . . 3 . . . . . . . . . . . . . . 4 . . . . . . 11
p51 1 1 1 2 2 2 1 . . . . . . . . . . . . . . . . . . . . 1 . . . . . . . 11
p30p31 . . . . . . . . . . . 5 . . . . . . . . . . . . . . . . . . . . 5 . . 10
p31 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2 2 . . . 4 8
p52 . . 1 2 . . 1 . . . . . . . . . . . . . 1 1 . . . . . 2 . . . . . . . 8
p42 . . . . 1 . . . . . . . . 4 . . . . . . . . . . . . 2 . . . . . . . . 7
p53 . . . . . . . . . . . . . . 4 . . . . . . . . . . . . 1 . . . . 2 . . 7
p54 . . . . . . . . . . . . . . . . . . 3 . 2 . . . . . . . . . . . . . 2 7
p55 . . . . 1 . . . . . . . . 2 . . . . . . . . . . 2 . . . . . . . . 1 . 6
p56 . . . . . . . . . . . . . . . . . . . . . . 1 1 1 1 1 1 . . . . . . . 6
p57 . . . . . . . . . . . . . . . . 1 . . . 1 . . . . . . 2 . . . 1 1 . . 6
p58 1 . . . 2 . . . . . . . . . . . . . . . . . . . 1 . . . . 1 . . . . 1 6
p59 . 1 . . . . . . . 1 . . . . 1 . 1 . . . . . . . . . . . . . . 2 . . . 6
p60 . 2 . 2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2 . 6
p26p42 . . . . 5 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
p27p35 . . . . . . . . . . . . . . . . . . 5 . . . . . . . . . . . . . . . . 5
p61 . . . . . . . . . . 2 1 1 . . . . 1 . . . . . . . . . . . . . . . . . 5
p62 . . . . . . . . . . . . . . . . . . . . . . 1 1 1 1 1 . . . . . . . . 5
p30 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4 . 4
p30p42 . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4 . . . . . . 4
p63 . . 2 . . . . . . . . . . . . . 2 . . . . . . . . . . . . . . . . . . 4
p64 . . . . . . . . . . . . . . . . . . 2 . . . . . . . . . . . . . . . . 2
p65 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2 . . 2
p06p15 . . . . . . 1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
p66 . . . . . . . . 1 . . . . . . . . . . . . . . . . . . . . . . . . . . 1
p67 . . . . . . . . . . . 1 . . . . . . . . . . . . . . . . . . . . . . . 1
Total 30 29 31 30 29 28 28 28 28 28 28 26 28 31 30 29 31 30
31 29 29 29 28 28 28 28 28 28 28 26 28 31 31 29 29 1010
A B C D E F G A B C D E F G A B C D E F G H A B A B A A A B C D E F G +
10___________ 11___________ 12_____________ 5__ 6__ 7 8 9____________
Cuplaje de clase: 10AB, CD, EF; 9AB, CG: p06/p15
Profesorii apar în ordinea stabilită prin factorul DF$prof, deci în ordinea descrescătoare a numărului de ore. Totalurile de ore pe coloane au fost redate pe două linii, alternativ; astfel, putem distinge că "10A" are 30 de ore, iar clasa imediat următoare "10B" are 31 de ore ş.a.m.d. (dacă le-am fi redat pe o singură linie, trebuia să le separăm prin spaţiu şi atunci, liniile se lărgeau prea mult).
La sfârşitul tabelului, am consemnat direct şi cuplajele de clase; nu pare necesar să mai menţionăm şi semnificaţia unor „profesori” ca "p30p31"…
Având (ca fişier-text) tabelul de încadrare redat mai sus („abstract” – nu ştim cine sunt profesorii şi nu mai ştim de pe unde vom fi preluat datele), putem aplica programele prezentate pe aici (în cursul anului 2021) pentru a obţine un orar „echilibrat” în privinţa repartizării lecţiilor pe zile, clase, profesori şi obiecte. Precizăm că între timp, am definitivat programele respective – de repartizare omogenă pe zile şi pe orele zilei, de corectare a suprapunerilor ascunse induse de cuplaje, de reducere a ferestrelor, etc. – şi le-am „documentat” (în paralel cu dezvoltarea programelor) într-o carte (cu LaTeX, desigur) de 100 de pagini – De capul meu prin problema orarului şcolar.
(aaa… costă 100 lei: 80 către ceea ce ţine de Free Software Foundation, 50 mie, iar restul constituie desigur, erori de difuzare – se ştie desigur, împărţirea nu este exactă niciodată)
vezi Cărţile mele (de programare)