Pigmentizarea programelor R
Să considerăm o secvenţă de cod (aici – una banală), în R:
# banal_prog.R
for(i in 1:10) {
if(i < 3) next
cat(i, "este mic\n")
if(i >= 5) break # nu interesează
}
Putem să o inserăm ca atare, în textul unui articol scris de exemplu în HTML sau în LaTeX – având grijă doar ca fontul folosit pentru cod (de regulă, unul monospaţial) să difere de cel de bază.
Dar de obicei, pentru scrierea programelor folosim un editor de cod-sursă (dar doar îl folosim pentru lucru, fără a ne pune problema de a analiza ce şi cum face el ca program), iar acesta marchează prin culori distincte, elementele sintactice specifice limbajului:
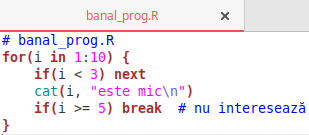
Desigur că putem inventa şi noi, anumite stiluri prin care să marcăm cuvintele-cheie, numele de funcţii, liniile de comentariu etc., în vederea redării textului-sursă al unui program. De exemplu, pentru a integra programul respectiv într-un document HTML, putem prevedea nişte clase CSS precum:
<!DOCTYPE html>
<meta charset="utf-8" /><title>Syntax Highlighting</title>
<style>
.kw {color: navy} /* Keyword */
.fn {color: blue} /* Function.Name */
.cm {font-size:0.9em} /* Comment */
.sg {color: maroon;} /* String */
.ct {color:Sienna} /* control caracter, de exemplu '\n' */
</style>
Apoi, includem textul programului într-un element <pre> şi aplicăm stilurile respective pe fiecare termen sintactic, folosind elemente <span class="...">:
<body>
<p>Text Text Text Text Text Text Text Text Text</p>
<pre style="background:white; font-size:1.1em; margin-left:2em">
<span class="cm"># banal_prog.R</span>
<span class="kw">for</span>(i <span class="kw">in</span> 1:10) {
<span class="kw">if</span>(i < 3) <span class="kw">next</span>
<span class="fn">cat</span>(i, <span class="sg">"este mic<\span><span
class="ct">\n</span><span class="sg">"</span>)
<span class="kw">if</span>(i >= 5) <span class="kw">break</span> <span
class="cm"># nu interesează</span>
}
</pre>
<p>Text Text Text Text Text Text Text Text Text</p>
</body>
iar la redarea în browser vom obţine:

Doar că, dacă avem de redat mai multe secvenţe de cod (nebanale), nu ne-ar conveni deloc să înlocuim manual, în textul de program pastat în fişierul HTML respectiv, fiecare cuvânt-cheie cu <span class="kw">cuvânt-cheie_curent</span>, fiecare comentariu cu <span class="cm">comentariu_curent</span>, ş.a.m.d.
Mai că n-ar fi greu, să întocmim un program prin care să automatizăm înlocuirile menţionate – chiar dacă ar trebui să avem grijă de a separa corect termenii, ţinând seama de contextul în care apar (de exemplu, "for" nu trebuie marcat dacă el apare în "formula"). Am pleca de la o listă de termeni sintactici, reprezentaţi prin expresii regulate care să specifice contextul în care trebuie consideraţi ca atare (de exemplu, "\bfor[^\w]", care înseamnă că "for" trebuie să nu aibă vreun prefix – ca în "informare" – şi să nu fie urmat de o literă sau cifră); am completa lista respectivă, asociind fiecărui termen component o anumită culoare de redare, sau mai general o anumită specificaţie de formatare; apoi rămâne de asigurat citirea şi parcurgerea textului de program furnizat, înlocuind fiecare apariţie de termen existent în lista noastră, conform stilării asociate acestuia.
Dar există deja programe foarte bune, pentru aceasta; pachetul Pygments (folosit de obicei prin programul pygmentize) asigură despărţirea în "tokeni" a codului-sursă furnizat – recunoscând sintaxa specifică pentru o gamă foarte largă de limbaje – şi asocierea acestora cu diverse specificaţii de formatare; este vizată atât redarea în HTML (cu alegere din mai multe seturi de clase CSS), cât şi în LaTeX (prin anumite seturi de macrouri), ba chiar şi pentru ecran (prin comenzi ANSI ESC[).
De exemplu, să afişăm (pe ecran) programul ca atare (prin comanda Bash cat) şi apoi, în urma formatării prin pygmentize:
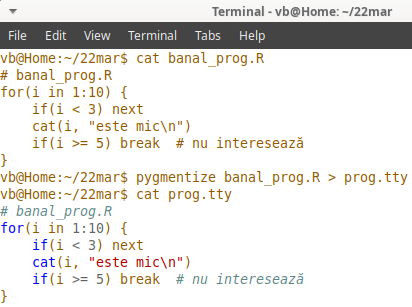
pygmentize a recunoscut (după extensia ".R" din numele de fişier) că este vorba de limbajul R, a folosit analizorul sintactic (sau "lexer") pentru limbajul R (producând „arborele sintactic” al programului indicat) şi neavând indicat un format (html, latex, etc.) – a folosit formatarea pentru "terminal" (şi a scris rezultatul în fişierul indicat prog.tty, pe care l-am redat apoi pe ecran, folosind iarăşi comanda cat).
Dar avem de observat că "in", "break" şi "next" nu mai apar (precum mai sus, în cazul editorului de cod-sursă) ca fiind „cuvinte-cheie”; preluând din prog.tty formatarea folosită pentru "for" şi aplicând-o lui "break" (prin comanda Bash echo), putem vedea direct cum ar fi trebuit să fie redat acesta:
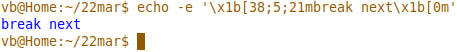
Precizăm că prin "\x1b[38m" se comandă terminalului comutarea pe o anumită culoare de afişare (analog cu specificaţia CSS din <span style="color:blue">), iar opţiunea "-e" forţează echo să interpreteze secvenţele de comenzi "ESC[" (care încep cu "\x1b[").
Este cumva justificată, „scăparea” menţionată mai sus: în fond, în R "else", "break", "next", "repeat" sunt funcţii, deci riguros vorbind, ar trebui invocate ca funcţii (de exemplu, repeat({...}) şi nu cum se obişnuieşte (în urma unei derogări tacite); dacă înlocuim "break" cu break(), next cu next(), etc. atunci pygmentize va reda programul la fel ca şi editorul de cod-sursă.
Dar oare ce ar trebui modificat, în lexerul de R din Pygments, pentru ca termenii evocaţi mai sus să fie marcaţi ca şi funcţiile? Desigur, documentaţia descrie destul de clar cum să defineşti un lexer propriu şi să-l integrezi în Pygments, dacă ai nevoie – însă pretenţia de a marca suplimentar încă vreo câteva cuvinte este chiar prea mică, pentru a ne gândi serios să scriem un alt lexer…
Să copiem în directorul de lucru lexerul respectiv şi să-l inspectăm:
cp /usr/local/lib/python3.8/dist-packages/pygments/lexers/r.py .
În subclasa de obiecte "lexer" SLexer, găsim definiţia dicţionarului tokens{}, în care cheia 'root' specifică ordinea în care sunt scanate porţiuni (constituite prin anumite expresii de selectare) din textul curent de program, asociind fiecăreia câte o anumită clasificare (rezultând în final, arborele sintactic al programului respectiv):
'root': [ # calls: (r'(%s)\s*(?=\()' % valid_name, Name.Function), include('statements'), # include 'comments', 'keywords', etc. (r'\{|\}', Punctuation), (r'.', Text), ],
Conţinutul de sub cheia 'root' are (aproximativ) această semnificaţie: se verifică întâi dacă textul curent citit din program reprezintă un nume de funcţie – caz în care porţiunea respectivă este reţinută şi calificată drept Name.Function, apoi se scanează următoarea porţiune de text; dacă nu este un nume de funcţie, se verifică dacă este un comentariu – dacă da, se reţine, se califică drept 'Comment.Single' şi se scanează mai departe textul programului; analog se procedează, succesiv, pentru 'Name', 'Punctuation', 'Keyword.Reserved', 'Operator', etc.
valid_name desemnează orice secvenţă de caractere alfanumerice (plus '.') care începe cu o literă, astfel că '(%s)\s*(?=\()' – unde (%s) ţine loc de un "valid_name" – reprezintă într-adevăr, orice apelare de funcţie (începe cu literă, conţine litere, cifre, eventual "_", sau "." şi se încheie cu "(").
Deci "break" (fără adăugarea unei paranteze deschise) nu va fi calificat, când va fi întâlnit în text, ca "Name.Function"; bineînţeles că nici drept "Comment.Single" şi ajungând la testul de "Name", se conchide că asta este: un "Name" (după care se scanează următoarea porţiune de text). Abia mai târziu – după ce s-a trecut de "break", "else" etc., calificaţi deja ca Name – urmează verificarea de "Keyword.Reserved".
Probabil că soluţia cea mai simplă, pentru a marca drept "Name.Function" şi "break", "next" etc., constă în a forţa ca verificările să înceapă cu aceşti termeni – explicitându-i chiar pe primul loc în 'root':
'root': [ # calls: (r'\b(else|next|break|repeat|in)\b', Name.Function), (r'(%s)\s*(?=\()' % valid_name, Name.Function), include('statements'), ### ... ],
Iar pentru a evita vreun eventual conflict, excludem termenii respectivi din "Keyword.Reserved", lăsând numai:
'keywords': [ (r'(if|for|while|return|switch|function)' r'(?![\w.])', Keyword.Reserved), ],
După aceste două modificări, copiem înapoi fişierul "r.py":
sudo cp r.py /usr/local/lib/python3.8/dist-packages/pygments/lexers/
şi putem verifica imediat că acum "break", "next" etc. sunt marcate corect:
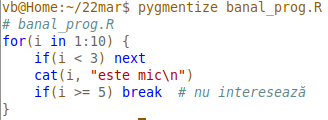
Desigur, poate că într-o versiune viitoare a pachetului Pygments, SLexer va fi modificat (probabil, mai bine decât am făcut-o noi mai sus); dar dacă nu, atunci va trebui să avem grijă ca, după instalarea noii versiuni, să recopiem în lexers/ fişierul "r.py" pe care-l înscrisesem mai sus în directorul curent (modificând fişierul original în două locuri, pentru a marca drept "Name.Function" şi cuvinte-cheie ca break, else etc.).
vezi Cărţile mele (de programare)