Recunoașterea textului și extragerea datelor unui orar școlar prezentat în format PDF (I)
[1] V.Bazon - De la seturi de date și limbajul R, la orare școlare //books.google.ro/books?id=stfwEAAAQBAJ
[2] Încă un experiment, pe orarul unei școli (I)
[3] V. Bazon - Caractere vechi și noi, cu Postscript, LaTex și R //books.google.ro/books?id=SaAJEAAAQBAJ
De obicei, orarele școlare sunt constituite folosind aplicația ascTimetables și sunt postate pe internet în format PDF; de obicei, fișierul PDF respectiv a provenit imediat din cel generat în final de ascTimetables și atunci putem extrage textul (ajungând apoi la datele orarului) folosind Ghostscript sDEVICE=txtwrite, sau un convertor / pachet "PDF to Excel" (v. [1], [2]).
Dar sindromul alambicat al creativității atinge uneori și pe cel de folosește ascTimetables pentru a obține orarul școlii… În loc de a converti imediat (click "... as PDF") fișierul HTML (sau Excel) obținut de sub ascTimetables — implică un font caligrafic, achiziționat ad hoc într-un fel sau altul, pentru calculatorul propriu; doar că pe un alt calculator, de obicei, fontul respectiv va fi aplicat numai în prezența licențelor comerciale necesare (altfel, de regulă va fi substituit automat prin unul dintre fonturile instalate).
Ce-i de făcut? Probabil că o persoană plină de inventivitate tipărește de pe propriul calculator (pe care și-a instalat legal fontul comercial respectiv) paginile documentului original și apoi folosește un scanner, obținând un fișier PDF conținând imaginile scanate ale paginilor (încât orice alt utilizator, indiferent de licențele de care dispune, va putea vedea exact același document ca și cel original (dacă acesta a fost scanat cu suficientă acuratețe)).
De!… Ce înveți la "TIC"? nu informatică, drept știință (nu-ți trebuie, pentru "Certificatul de competențe digitale") — ci să folosești aparatura (și meniurile aplicațiilor Microsoft).
Redăm aici prin instrumentul "Take a screenshot" pagina corespunzătoare uneia dintre clase, din documentul PDF scanat (preluat de pe internet și deschis prin browserul Firefox, pe calculatorul nostru); precizăm că în prealabil, a trebuit să rotim pagina cu $90^\circ$ în sens antiorar (documentul PDF o încorporase în formatul implicit "Portrait", nu în format "Landscape"):

Imaginea redată este în format PNG (deschizând-o într-un alt tab—pe lângă faptul că astfel va apărea mărită—se poate constata că ea provine din fișierul gimnaziu.PDF-5A.png); admirăm desigur textul „de mână” (cursiv) care apare pe imagine, dar acesta nu poate fi extras ca atare, prin procedeele obișnuite evocate mai sus — de data aceasta este necesar să apelăm la produse care implementează "Optical Character Recognition" (precizăm că am încercat și să depistăm fontul implicat — apelând (doar într-o doară) la //www.myfonts.com/pages/whatthefont…).
Sunt multe site-uri care oferă (on-line) servicii OCR și destule clamează de "cel mai bun"; dar mai toate pe care le-am încercat (sub lozinca "free trial") — dezamăgesc.
Am nimerit unul singur care merită lăudat: pen2txt.com; textul furnizat pentru imaginea redată mai sus are numai vreo două erori (dintre care una este consecință firească a obiceiului specific celor care produc manual „tabele”, de a separa pe două rânduri un conținut indivizibil existent într-o celulă de tabel — vezi "Marți", numele de profesor din celula "informatică"). Deocamdată, deși oferta 30€ / 250 pagini / lună este convenabilă, ne abținem să inițiem un aranjament; se pare că ar trebui să operăm pagină cu pagină (câte o singură imagine), în loc de a le transmite cumva în bloc — ceea ce nu ne mai convine…
Există desigur, aplicații, proiecte și pachete OCR open source (în care n-o să dăm peste restricții precum "câte o singură imagine"); cel mai adesea, acestea angajează (din $\mathbf{C}$, Python, $\mathbf{R}$, sau alte limbaje) „motorul” Tesseract (creat între 1985-1994 în laboratoarele firmei Hewlett-Packard, lansat ca open source în 2005, sponsorizat și dezvoltat apoi de către Google).
Nu ne așteptăm să obținem imediat, rezultate bune (cum ar fi prin aplicația comercială de la //pen2txt.com) — dar folosind produse open source și asumându-ne anumite eforturi cognitive, avem șansa de a investiga și a ne lămuri lucrurile, în cunoștință de cauză.
Mai întâi (prin Synaptic Package Manager), am verificat ce pachete (din distribuția Ubuntu-Linux 22.04) sunt deja instalate — folosisem anterior (v. [3]) ghostscript, ImageMagick și diverse aplicații (v. Evince) sau programe utilitare bazate pe Poppler — și am instalat tesseract-ocr, precum și unele aplicații OCR la care ne vom referi mai jos.
Dar subliniem că extragerea textului din fișierele PDF respective nu este pentru noi, un scop în sine — intenționăm de fapt să analizăm datele respective și să constituim pe seama lor (ca și în [2]), un orar echilibrat (exploatând din nou, programele $\mathbf{R}$ din [1]).
Dar până să putem vorbi de datele orarului, examinăm aici diverse posibilități de a extrage textul de pe imaginile conținute într-unul dintre cele 5 fișiere PDF.
Cadrul de lucru
Copiem "gimnaziu.PDF" într-un subdirector de lucru; va fi suficient să considerăm fișierul PDF corespunzător uneia dintre clase. Extragem pagina 1 (a cărei imagine rotită am redat-o mai sus) și îi schimbăm orientarea; rezultatul depinde în unele privințe, de instrumentul pe care îl folosim pentru aceasta:
qpdf gimnaziu.PDF --pages . 1 -- --rotate=-90 qpdf-5A.pdf pdfinfo qpdf-5A.pdf | grep 'Page\|PDF' Pages: 1 Page size: 595.2 x 841.92 pts (A4, Landscape) Page rot: 270 # = -90 PDF version: 1.3
Pagina extrasă și rotită prin qpdf, păstrează formatul "PDF 1.3" al fișierului inițial și aceleași caracteristici referitoare la font (prin pdffonts vedem că este vizat, dar neîncorporat în fișier, fontul numit generic "Helvetica").
Dacă folosim Ghostscript pentru a extrage pagina 1 și apoi o rotim (tot prin qpdf), atunci fișierul rezultat 5A.pdf are formatul "PDF 1.7" și este de dimensiune sensibil mai mare decât în cazul precedent — fiindcă acum, fontul este și înglobat în fișier:
gs -sDEVICE=pdfwrite -dNOPAUSE -dBATCH -dSAFER \
-sPageList=1 -sOutputFile=5A.pdf gimnaziu.PDF
qpdf 5A.pdf --rotate=-90 --replace-input
Producer: GPL Ghostscript 9.55.0
PDF version: 1.7
pdffonts 5A.pdf
name = IQIZVV+Helvetica # n-am înțeles de unde vine "IQIZVV+"...
type = Type 1C
encoding = WinAnsi
emb = Yes # "embedded" (încorporat în fișier)
Puteam roti și prin convert (din ImageMagick), în loc de qpdf:
convert -rotate -90 -density 200 5A.pdf gs_conv-5A.pdf # PDF 1.4
sau, puteam extrage și roti prin pdfjam (din pachetul LateX pdftools):
pdfjam --landscape --angle 90 gimnaziu.PDF '1' --outfile jam_5A.pdf # PDF 1.3
Dintre fișierele obținute mai sus alegem să păstrăm 5A.pdf, singurul caz în care avem și un font încorporat în mod explicit (și poate că, pe lângă extragerea textului din imagine, încercăm să lămurim și legătura acestuia cu fontul Helvetica încorporat în 5A.pdf).
Experimente bazate pe Ghostscript
Începând cu versiunea 9.53, Ghostscript prevede "output devices" și pentru OCR, angajând ca „motor” biblioteca tesseract.
Opțiunea -sDEVICE=ocr
declare -x TESSDATA_PREFIX=`locate -r '\/tessdata$'` # /usr/share/tesseract-ocr/4.00/tessdata gs -q -sDEVICE=ocr -r300 -sOCRLanguage="eng+ron" -o 5A.txt 5A.pdf # -r1000
Subdirectorul tessdata/ conține fișiere de configurare a unor parametri (grupate în subdirectoarele configs/ și tessconfigs/), fișierul-font special pdf.ttf (din care lipsesc glifele caracterelor, cum vedem imediat prin FontForge) și un anumit număr de fișiere voluminoase, cu extensia .traineddata:
ls $TESSDATA_PREFIX configs Latin.traineddata pdf.ttf tessconfigs eng.traineddata osd.traineddata ron.traineddata
Pentru a analiza imaginea dată, recunoscând (cu un anumit grad de încredere) textul scris în limba română pe acea imagine (și analog, pentru multe alte limbi) — va fi consultat fișierul ron.traineddata, în care au fost colectate și organizate din timp, numeroase șabloane (într-o multitudine de fonturi și stiluri) de litere și cuvinte din limba respectivă.
Redăm rezultatul obținut în "5A.txt", numerotând cumva liniile:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | Colegiul National Stefan cel Mare, Suceava 1 2 3 4 5 6 7 8 . 8:00 - 8:50 9:00 - 8:50 |10:10 11:00 |11:10 - 12:00 | 12:10 - 13:00 |13:10 - 14:00 | 14:10 - 15:00 | 15:10 - 16:00 Lune ea sociala biologie matematica engleza Utorie Delia Dasale Camelia Alexaneriae | Raluca Crisantha Alexa Daria Margimeam | Mihai Bogdan Drance Martv romana reugu coy matematica | informatia coy Mihaela Cristina lonela~Andveca Sandru Florin Hotie Adrian Frinew | Raluca Crisantha Alexa Hatna Nicoleta Bordo Miercuri | ed vizuala romana ed muzicala storie consiliere geografie Adrian Frinew | lonala- Andreea Sandrw Lucian Tablaw | Mihat Bogdan Dranca Nicoleta Bumbw Nicoleta Busi Jou coy eo fizica germana romana matemotiter Raluca Crisantha Alena Adrian Cojocarw Camelia Mafiei | Ionela Andreea Sandy | Raluca Crisanthe Alexa Vuneru germana romana truc matematica engleza eo fizica Mihaela Cristina Comelia Maftei | lovea Andreea Sandru Hatmanuw | Raluca Crisantha Alene Daria Margintan Adrian Cojocarw Orar generat:13-Sep-21 aSc Orare |
Să observăm mai întâi, că titlul "Clasa 5A - sala P11" nu a fost recunoscut ca text — pentru că pe imaginea respectivă, literele care formează acest text sunt foarte mari față de restul textului (și zona respectivă a fost neglijată: la rezoluția globală respectivă, ea este doar o „zonă-imagine”).
Titlul va fi recunoscut ca text — cam așa: "clasa SA - sola P-11" — numai dacă micșorăm rezoluția adoptată pentru interpretarea imaginii, înlocuind în comanda de mai sus -r300, de exemplu cu -r100; numai că astfel, restul textului din imagine rămâne mult prea mic pentru a mai putea fi (suficient de bine) recunoscut…
Textul cu font obișnuit (nu scris „de mână”) din primele două linii (nenumerotate mai sus) și din ultima linie a fost recunoscut ca text fără nicio problemă (după diversele documentații consultate, problemele de recunoaștere apar la textele scrise „de mână”); probabil, aplicația care a asigurat scanarea (v. SANE) va fi recunoscut ea însăși acest text și poate va fi ascuns undeva în fișierul PDF constituit ca rezultat al scanării, definiția fontului (Helvetica) pe care îl asociase textului respectiv…
Să observăm totuși caracterul ".", adăugat pe a doua linie…; „recunoașterea” ca text se datorează în acest caz prezenței unor pixeli „paraziți” (reflectând de obicei micile defecte ale colii de hârtie introduse în scanner, cum ar fi câte o pată micuță), la dreapta lui "8" — cum se observă pe această imagine mărită a zonei respective:
![]()
Mărind suficient rezoluția, de exemplu cu -r600, paraziții respectivi vor fi mult dispersați între ei, încât nu vor mai fi luați în seamă (iar în "5A.txt" va apărea doar "1 2 3 4 5 6 7 8", fără "." în final).
Existența unor „paraziți” în zonele din imagine aferente unor porțiuni de text explică și unele dintre „stâlcirile” de cuvinte apărute; de exemplu, în linia 3 avem "ea sociala" (în loc de "ed") — în schimb în linia 8 apare corect "ed vizuala" și "ed muzicala" (sau vezi "Bumbw" și "Busi" în loc de "Bumbu" cum ar fi fost corect în liniile 9 și 10, unde iarăși apar paraziți).
Cele observate mai sus induc unele bune practici, care pe lângă faptul că țin de „bun-simț”, sporesc șansele de recunoaștere ulterioară a textului: a evita folosirea într-o aceeași pagină, a unor dimensiuni de text foarte diferite între ele (porțiuni de text scrise cu mărime foarte mare, alături de porțiuni de text scrise normal sau cu o mărime foarte mică); a avea grijă ca pagina de hârtie de pe care scanner-ul va produce imaginea să nu aibă defecte (mici pete, sau diverse urme). În plus este important ca liniile orizontale și verticale care delimitează celulele de tabel (dacă există) să fie trasate cu o linie uniformă (ca grosime și densitate), pentru a spera la o interpretare ca tabel de date a imaginii respective.
Artefactele rămase pe imagine (precum și aspecte de contrast și luminozitate) mai pot fi eliminate sau corectate, prin diverse programe de transformare a imaginii; dar unele defecte de recunoaștere a textului nu prea pot fi corectate automat — fiind urmarea firească a unor „proaste practici”; iată un exemplu:

În principiu, analiza imaginii duce întâi (având în vedere și liniile care separă celulele) la separarea unor „linii” sau benzi orizontale de o anumită înălțime; se analizează apoi pe rând, fiecare bandă de pixeli, căutând o separare în cuvinte și caractere (cât mai potrivită cu șabloanele și caracteristicile înregistrate în fișierele .traineddata).
Pentru imaginea redată mai sus (extrasă de pe "5A.pdf"), am avea trei benzi; dar banda a doua conține numai "Mihaela Cristina" (recunoscut ca atare — v. linia 6 din "5A.txt"), în timp ce "Hatmanu" (care completează numele) aparține celei de-a treia benzi (v. linia 7, corespunzătoare acesteia, în care completarea de nume este stâlcită în "Hatna"; a observa pe imagine, „paraziții” existenți în jurul numelui respectiv).
Numele (precum aici "Mihaela Cristina Hatmanu") este de fapt o entitate indivizibilă și este un prost obicei, acela de a-l separa „pe două rânduri” (văzând că „nu încape” în celula respectivă și confundând ceea ce vedem cu ceea ce este de fapt).
Deasemenea… este un prost obicei, acela de a înregistra numele de persoane (într-un tabel de date) în forma „elegantă”, prenume plus nume de familie (fiindcă ordonările și căutările de date pretind firește, ca numele de familie, nu prenumele, să fie primul indicat).
Opțiunea -sDEVICE=hocr
Fișierul 5A.txt obținut mai sus conține textul (separat în paragrafe, cuvinte și caractere individuale) recunoscut prin OCR pe imaginea aferentă paginii 5A.pdf; formatul hOCR asigură în plus, înregistrarea unor informații contextuale — cum este poziționată în cadrul imaginii respective, zona de pe care s-a recunoscut elementul curent de text și în ce măsură este valabilă interpretarea ca text care s-a asociat acelei zone — iar pentru înregistrarea acestora se folosește limbajul de marcare XML (în principal, elementele <p>, <div> și <span>, prevăzute cu anumite atribute class, id și title, cu valori corespunzătoare).
N-avem decât să edităm comanda precedentă, înlocuind cu "hocr" și cu ".html":
gs -q -sDEVICE=hocr -r300 -sOCRLanguage="eng+ron" -o 5A.html 5A.pdf
Ilustrăm rezultatul cu acest fragment, extras din fișierul 5A.html:
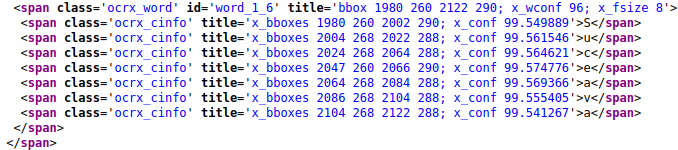
"class='ocrx_word'" marchează un „cuvânt” — aici, al 6-lea (marcat cu "id='word_1_6'") din <span>-ul mai larg asociat primei linii din fișierul 5A.txt (redat mai sus); în bbox sunt specificate coordonatele colțurilor stânga-sus și dreapta-jos ale zonei dreptunghiulare de pe care s-a recunoscut cuvântul respectiv (măsurate în pixeli, plecând de la colțul stânga-sus al întregii imagini); x_wconf înregistrează gradul de încredere față de recunoașterea cuvântului respectiv. Span-ul asociat astfel cuvântului, are drept conținut nu cuvântul respectiv, ci un număr de elemente <span> (cu "class='ocrx_cinfo'") — câte unul pentru fiecare dintre literele care compun acel cuvânt; prima literă 'S' are desigur același colț-stânga, iar ultima literă 'a' are același colț-dreapta (cu o mică diferență la ordonate) ca și întregul cuvânt (după cele 7 <span>-uri urmează </span>, care încheie formularea hOCR a primei linii din 5A.txt).
Dacă încărcăm 5A.html într-un browser și purtăm mouse-ul peste litera 'S' cu care începe cuvântul al 6-lea din prima linie, atunci browser-ul va produce undeva în vecinătatea literei respective un tooltip, vizualizând textul înscris în atributul title.
În particular, putem constata că tooltip-urile asociate cu "Mihaela Cristina" indică locul corect (deasupra numelui de familie de care fusese separat).
Folosind un editor de text putem corecta porțiunile de text incorect recunoscute prin OCR; apoi va fi ușor de extras din fișierul HTML corectat, datele orarului (numele de obiecte și de profesori, în ordinea lecțiilor clasei pe fiecare zi).
Însă cine preferă interfețe grafice (în cazul nostru, pentru tesseract-ocr), poate folosi și gImageReader (gimagereader-gtk, în distribuția Ubuntu):
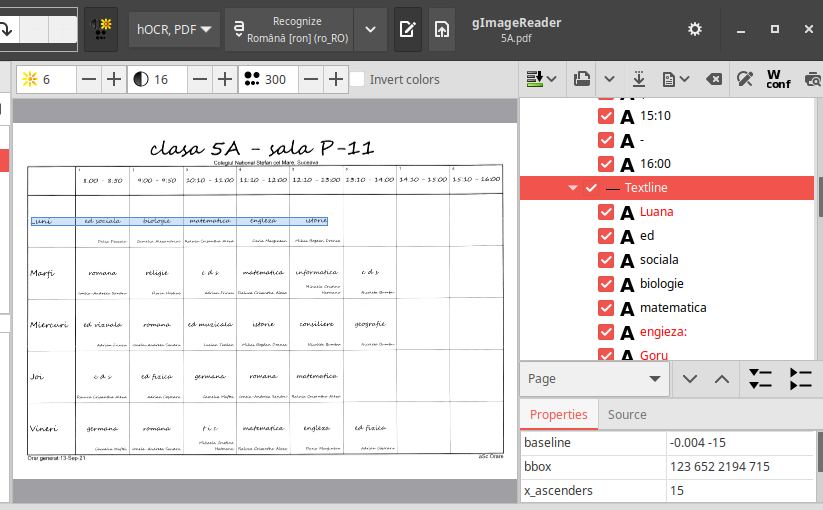
Textul recunoscut (după ce, folosind meniurile și butoanele, am încărcat
Extragerea datelor din formatul hOCR
Până să ne ocupăm coerent de „datele orarului”, să vedem cum am extrage datele din fișierul în format hOCR 5A.html obținut mai sus; folosim în acest scop biblioteca libxml2, exploatând-o din mediul $\mathbf{R}$.
5A.html reprezintă o singură pagină (există un singur element <div class='ocr_page'...>) și aceasta include un singur bloc de conținut (un singur element <div class='ocr_carea'...>), care conține un singur paragraf (un singur element <p class='ocr_par'...>) — iar acesta conține un anumit număr de elemente <span class='ocr_line'...>, asociate respectiv benzilor orizontale în care a fost separată imaginea inițială. Fiecare element de tip "ocr_line" include elemente <span class='ocrx_word'...>, câte unul pentru fiecare cuvânt recunoscut pe linia respectivă; iar sub span-ul cuvântului, avem câte un <span class='ocrx_cinfo'...> pentru fiecare literă din cuvântul respectiv.
(Asta e! Nu de la <table> pleacă reprezentarea, ci de la paragraf…)
Ne interesează datele la nivel de linie și cuvânt (și va trebui să concatenăm corespunzător datele aferente literelor), reprezentate în HTML ca valori (cu anumite nume) ale atributelor id și title, montate pe elementele "span" respective.
Următorul program (dar nu prea elaborat) produce în final două obiecte "list" — unul înregistrează coordonatele boxei pentru fiecare linie, iar celălalt conține câte un obiect "data.frame" pentru fiecare cuvânt de pe câte o aceeași linie:
library(xml2) # read_html(), xml_find_all(), xml_attr(), xml_text() library(stringr) # str_extract() și str_replace() doc <- read_html("5A.html") lines <- xml_find_all(doc, ".//span[@class='ocr_line']") get_bbox <- function(Node) # coordonatele boxei xml_attr(Node, "title") |> str_extract("bbox [\\d ]+") |> str_replace('bbox ', "") # |> strsplit(" ") |> unlist() get_wconf <- function(Node) # gradul de confidență xml_attr(Node, "title") |> str_extract("x_wconf [\\d]+") |> str_replace('x_wconf ', "") |> as.numeric() L <- list() # pentru linii W <- list() # pentru cuvintele de pe câte o linie for(line in lines) { lc <- xml_attr(line, "id") |> str_replace('line_', "") L[[lc]] <- get_bbox(line) words <- xml_find_all(line, ".//span[@class='ocrx_word']") nw <- length(words) W[[lc]] <- vector("list", nw) for(i in 1:nw) { wd <- words[i] bb <- get_bbox(wd) cf <- get_wconf(wd) chs <- xml_find_all(wd, ".//span[@class='ocrx_cinfo']") |> xml_text() |> paste0(collapse="") W[[lc]][[i]] <- list(chs, cf, bb) } } lDF <- lapply(names(L), function(num) t(list2DF(W[[num]]))) for(i in 1:length(lDF)) colnames(lDF[[i]]) <- c("Word", "Conf", "BBox") names(lDF) <- names(L)
Pentru ilustrare, redăm datele corespunzătoare primei linii recunoscute ca text:
> L[["1_1"]]
[1] "1399 260 2122 294"
> lDF[["1_1"]]
Word Conf BBox
"Colegiul" 95 "1399 262 1532 291"
"National" 95 "1546 262 1681 290"
"Stefan" 96 "1695 261 1800 290"
"cel" 95 "1813 262 1859 290"
"Mare," 96 "1873 261 1964 294"
"Suceava" 96 "1980 260 2122 290"
În coloana "Conf" avem „gradul de încredere”… dar n-am luat seama la nuanțe și ne-am cam păcălit, cum ne dăm seama văzând datele pentru linia 11:
> lDF[["1_11"]] Word Conf BBox "Jou" 75 "120 1740 215 1799" "coy" 44 "566 1745 687 1784" "eo" 55 "895 1744 955 1779" "fizica" 57 "965 1745 1113 1791" "germana" 47 "1264 1739 1485 1793" "romana" 76 "1650 1738 1844 1792" "matemotiter" 0 "1975 1741 2262 1779"
Avem două categorii de „încredere”: "x_wconf" pe care am reținut-o noi în coloana "Conf", este asociată cuvântului și exprimă șansele de a găsi cuvântul respectiv într-un dicționar al limbii; "x_conf" este asociată literei și măsoară încrederea că litera respectivă corespunde cel mai bine, zonei de pixeli curent analizate.
Practic n-avem nevoie, de valorile "x_wconf": știm și fără a consulta "Conf", care cuvinte sunt corecte și care (de exemplu "matemotiter") sunt în afara dicționarului limbii române…
Ceea ce ar fi trebuit să ne intereseze sunt valorile "x_conf", pe care în programul de mai sus le-am ignorat (pentru „avantajul” de a nu adânci lucrurile până la nivelul literelor).
vezi Cărţile mele (de programare)