Recunoașterea textului și extragerea datelor unui orar școlar prezentat în format PDF (II)
[1] v. partea I-a
Scrierea de mână și fonturi cursive
Abecedar-ul (… și doamna învățătoare) ne-a învățat scrierea „de mână”:

Conform liniaturii caietului, literele sunt înclinate spre dreapta (cu 18 grade), au câte o aceeași formă când apar într-un cuvânt sau altul și în cadrul fiecărui cuvânt în care apar, literele respective sunt legate între ele (prin „cârlige”). Adăugând și spațiul (cam uitat, în abecedare), ajungem până la urmă (după o anumită codificare specifică tipografiei digitale) la un font pentru scrierea caligrafică.
Obs. Scrierea ilustrată în imaginea de mai sus… este cam lăbărțată (foarte lentă) și girează în timp (dacă nu este complementată), o gândire lăbărțată, lipsită de libertate și spontaneitate. S-ar cuveni ca scrierea impusă de abecedar — de pe când instrumentele de scris erau tocul cu peniță și călimara cu cerneală — să fie (în sfârșit) revizuită, încurajând de la bun început un stil mai dinamic.
Analizând scrierea de mână oficializată prin „abecedare” într-o țară sau alta, Primarium constituie și oferă fonturi corespunzătoare; ilustrăm familia de fonturi Playwrite RO:
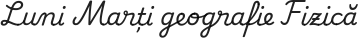
Un font cursiv mai dinamic decât cele evocate mai sus este cel folosit pentru redarea orarului școlar vizat în [1]; mai redăm aici o mostră:

Această scriere „de mână” este și ea, bazată cumva pe un anumit font (existent undeva, dar n-am reușit să-l identificăm); se vede ușor că de exemplu, litera "a" apare la fel în oricare cuvânt (ori, când scrii „de mână” — pentru o aceeași literă apar inevitabil variații grafice mai mari sau mai mici, față de glifa „standard” asociată caracterului respectiv și deseori, ca să o recunoști trebuie să ții seama și de contextul „de mână” în care apare ea).
Am constatat în [1] că tesseract nu poate recunoaște suficient de bine, textul scris astfel; pe de o parte, fiindcă nu cunoaște fontul care este implicat; pe de altă parte, fiindcă textul respectiv a fost formatat defectuos și iarăși, a fost scanat cam defectuos (tesseract face el însuși, niște corecții — dar chiar nu poate „repara” anumite lucruri).
Textul va fi fost organizat pe linii și coloane de celule, dar pagina respectivă a fost introdusă în scanner cam neglijent, fiind ușor rotită; pe imaginea din pagina PDF rezultată, liniile deviază puțin de la orizontală (încât aspectul liniilor care delimitează celulele tabelului variază de la o celulă la alta — ceea ce îngreunează separarea între conținuturi).
Pe de altă parte, conținuturile celulelor au fost formatate defectuos, despărțind pe două rânduri, mai mult sau mai puțin arbitrar, denumirile prea lungi; pentru unele rânduri de celule, tesseract asociază două benzi orizontale de pixeli (una pentru numele zilei plus denumirile disciplinelor și una pentru numele profesorilor), dar pentru altele va asocia trei sau mai multe benzi (neavând cum să înțeleagă că, de exemplu, "antreprenori" de pe un rând și "ala" de pe rândul următor trebuie alipite pe o aceeași bandă).
Numele disciplinelor sunt centrate în celule, iar numele profesorilor (care sunt scrise și prea mic) sunt aliniate la dreapta, dar fără "padding" — ceea ce duce uneori și la cuvinte care includ '|' (separatorul de celule).
La început ne interesa doar să obținem textul (pentru ca apoi, să extragem și să organizăm datele orarului, permițând investigări și prelucrări asupra acestora); constatând în [1] că nu reușim folosind direct tesseract, ar fi suficient să apelăm la pen2txt.com, sau mai bine cum am văzut între timp, la cloud.google.com/vision (unde pe lângă alte avantaje, prețurile sunt mult mai mici). Dar cu timpul, sporind documentarea asupra OCR, a ajuns să ne intereseze problema în sine: ce-i de făcut pentru ca tesseract (de pe calculatorul propriu) să recunoască suficient de bine, textul cursiv (într-un font necunoscut) existent pe o imagine grafică?
Am încercat un timp recomandarea obișnuită, care constă în ajustarea prealabilă a imaginii (reglând orientarea textului, luminozitatea, contrastul, mărimea și rezoluția, etc. — folosind Imagemagick și chiar OpenCV); dar chiar și dacă nimeream valorile optime ale parametrilor implicați, rezultatul OCR final este mereu, departe de așteptări — recomandarea menționată este eficace numai dacă ar fi vorba de un text obișnuit (scris de mașină, nu „de mână”).
Deci soluția trebuie căutată plecând totuși de la fontul cursiv specific textului respectiv. Nu cunoaștem acest font… totuși vedem pe imagine, glifele componente; n-am avea decât să desprindem de pe imagine aceste glife, să constituim cu ele un nou font (folosind FontForge, să zicem) pe care apoi să-l integrăm cumva în tesseract…
De fapt, nu-i necesar să constituim noi „un nou font” — vom vedea că este (aproape) suficient să specificăm litera care trebuie recunoscută, pentru fiecare glifă.
De la capăt…
Pe site-ul școlii respective am găsit — ca "Fisiere atasate" pentru "orar valabil din 14 septembrie 2021" — cinci link-uri, precum:

Pe acțiunea "/download/" sunt montate și alte link-uri, de exemplu: https://cnstefancelmare.ro/download/1091-salarii_31_03_2024.pdf, sau https://cnstefancelmare.ro/download/237-Kit_code_blocks_16.0.1.rar. Cele 5 fișiere PDF pentru orar au indecșii 347..351 (de exemplu, "351-gimnaziu.PDF"); le putem descărca pe toate, de exemplu prin curl:
cd 24aug/CNSM curl -O "https://cnstefancelmare.ro/download/[347-351]-.PDF" ls # listăm numele fișierelor descărcate în subdirectorul curent CNSM/ 347-.PDF 348-.PDF 349-.PDF 350-.PDF 351-.PDF
Este firesc să reunim cele 5 fișiere (folosim Ghostscript), obținând orarul școlii într-un singur fișier PDF; toate paginile au fost așezate pe verticală, dar dacă vrem să „decupăm” literele (de pe ecran, prin Screenshot) — trebuie să le rotim antiorar cu $90^\circ$ (folosim qpdf):
gs -sDEVICE=pdfwrite -o CNS.pdf `ls` qpdf CNS.pdf --rotate=-90 --replace-input
Cele 27 de pagini rezultate în "CNS.pdf" conțin orarul câte uneia dintre clase, într-un același format-vizual tabelar (nu chiar "tabel", fiindcă PDF nu prevede structuri de date):
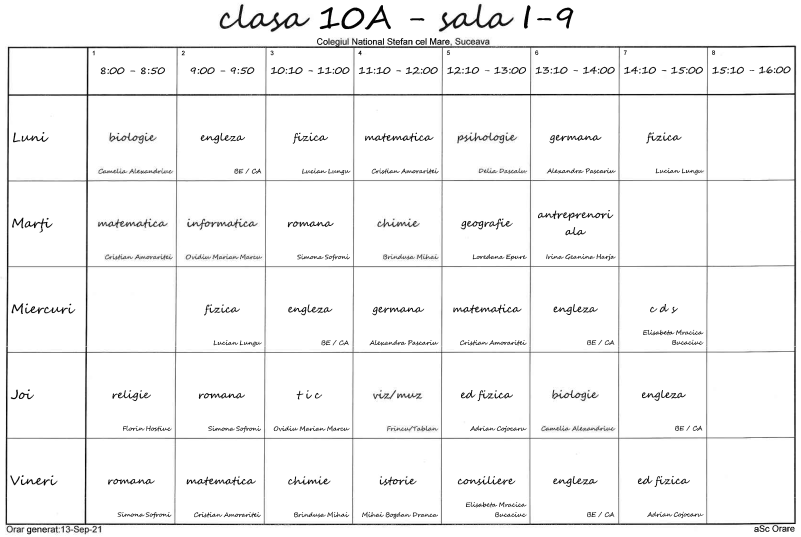
Nu ne interesează antetele și subsolurile (precum "Clasa ...", "Colegiul...", "Orar generat...") și nici capul de tabel (același pe toate paginile: "1 8.00 - 8.50..."); pentru a reconstitui numele claselor este suficient să reținem că primele 5 pagini corespund respectiv claselor 9ABDEF (lipsește "9C") — apoi urmează câte 6 pagini respectiv pentru clasele a 10-a, a 11-a și a 12-a ("ABCDEF"), iar la sfârșit avem câte o pagină pentru clasele 5..8.
Fișierele inițiale fuseseră constituite prin scanare, deci paginile conțin câte un obiect-imagine (nu text…); pe de altă parte, vrem să folosim direct tesseract (și nu prin Ghostscript ca în [1], nici prin Python, sau R…) — caz în care va trebui să furnizăm câte un fișier-imagine (nu pagini PDF).
Separăm din CNS.pdf imaginile respective — alegând ca format, PNG monocolor, cu rezoluția de $300px$ — și (în urma unui mic experiment, pentru a stabili coordonatele unor blocuri) excludem antetele, subsolurile și capetele de tabel prin:
pdftocairo -png -mono -r 300 -x 0 -y 494 -W 3508 -H 1808 CNS.pdf
Pentru ca tesseract să recunoască suficient de bine textul, trebuie ca imaginea respectivă să fie suficient de „bună” (să nu aibă pete, nici „purici”; să aibă un nivel optim de luminozitate și contrast; liniile trasate orizontal și vertical în jurul celulelor de tabel trebuie conturate clar și uniform; rezoluția recomandată este $300px$, totuși ea trebuie corelată cu aspectele menționate).
Anterior, încercasem după recomandările uzuale, convert din ImageMagick (și deasemenea, diverse funcții din OpenCV) — dar n-am nimerit valori potrivite pentru parametrii ceruți; în schimb, am constatat că pdfcairo elimină principalele artefacte și totodată, oferă un mecanism ușor de aplicat pentru a exclude părți din imagine.
Pentru ilustrare, alăturăm o captură de ecran de pe imaginea "CNS-23.png" rezultată prin comanda redată mai sus și respectiv, captura de ecran (dar mărită) corespunzătoare aproximativ aceleiași zone, în pagina PDF care conține imaginea respectivă:

Se vede (mai ales, privind dintr-o parte) că prima imagine (PNG) este mai „curată” (în a doua apar „paraziți” în jurul literelor). Desigur… numele profesorilor fiind scrise prea mic, devin mai slab conturate în PNG, decât erau în PDF; „soluția” cea mai simplă ar consta în mărirea rezoluției, de exemplu "-r 400" pare suficient — dar în acest caz trebuie modificați și parametrii -y și -H (setați mai sus corespunzător rezoluției de $300px$).
Redăm unul dintre cele 27 de fișiere PNG rezultate prin comanda pdftocairo de mai sus (pentru a observa că într-adevăr, am scăpat de antete, subsoluri și capete de tabel vizuale):
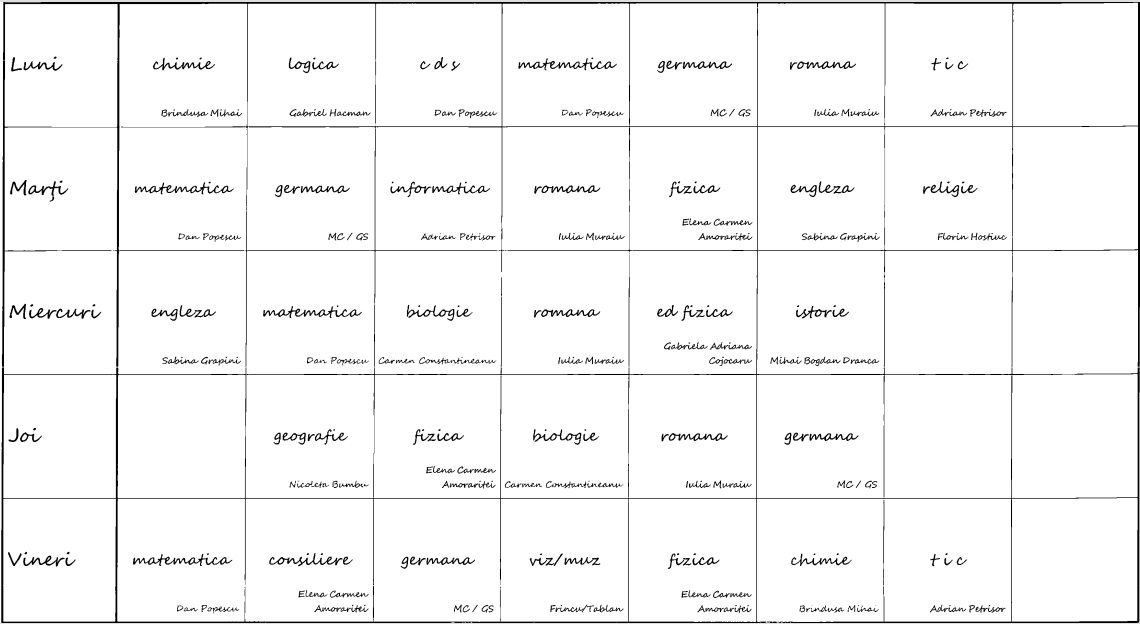
S-au scanat 27 de pagini tipărite și probabil, acestea au fost introduse manual, una câte una și aproape inevitabil, unele pagini au fost plasate cam rotit; pe imaginea redată se pare că nu, dar pe altele dintre cele 27, liniile deviază puțin de la direcția orizontală:

Poate că acest fapt nu contează prea mult (dacă abaterea este mai mică decât $3^\circ$), pentru recunoașterea textului — dar dacă vrem, putem corecta orientarea paginii prin:
convert CNS-14.png +deskew CNSw-14.png
(doar că astfel, fișierul rezultat ajunge să fie cam de 6 ori mai mare, decât cel inițial)
Inspectând cele 27 de imagini, constatăm că nu ar fi cazul să corectăm orientarea (devierile, existente pe unele pagini, fiind neglijabile); dar când va fi să „decupăm” litere sau mici porțiuni din imagine, vom prefera să lucrăm pe pagini corect orientate (pentru a nu altera caracterul de ușoară înclinare spre dreapta, specific scrierii respective).
Acum putem încerca să folosim direct, tesseract; fișierul implicat de obicei pentru recunoașterea textelor scrise în limba română este tessdata/ron.traineddata:
tesseract CNS-02.png stdout -l ron # "-02.png" corespunde clasei 9B Lun romana motematua fuzica UWforie geografie engleza spamiola Sumona- Sofronie Dan Portsew Sorin Golda Diudina Pedrisor Loreaama Epure Sabina Grapini, Anda Perjw M arțu Logica co 0 3 matematiea romana religie Chimie spaniola. Gabriel. Harman Dan. Popesen Dau Poate Simona Sofroni. Florin Hostiue Florin. loan. Cojotaru- Anda Perju Dame Pope | Cormar. Cortantintaruin Simona Sofroni, Sorin Gotda Florin loa Cojocaru Ratucae Costin amar Jov romana engleza rue consiliere biologie Uunformahea Simona Sofroni, Sabina Grapini, Raluca Coyhineanan Radu Coyhntanare | Carmen Corsair taran Raluca Cosi anate Vunzru ed fizica matemahiea VUz/ muz fizica formatie a truc Gabriela Adriana Cojotaru Das Pope Frincuy Tablam Sorin Goloda Raluca Coytimnanan Raluca Coytineamu
Rezultatul — care în acest caz este (evident) nesatisfăcător — depinde și de versiunea tesseract (dar depinde esențial, de calitatea fișierului ".traineddata" implicat pentru recunoașterea textului); precizăm că între timp, am instalat tesseract 5.4.1, în loc de versiunea oficială 4.1 din Ubuntu 22.04.
Calea recomandată pentru a crește calitatea recunoașterii textului constă în „extinderea” fișierului ".traineddata" asociat uneia dintre limbi (în principiu, pentru "eng"), specificând într-un anumit mod (care vizează ceea ce se cheamă "training") suficient de multe perechi de mici fișiere — un fișier-imagine pentru o zonă-linie (sau chiar pentru o glifă) decupată din imaginea de pe care s-a cerut recunoașterea textului și un fișier-text care să redea conținutul textual corect de recunoscut pentru acea zonă.
Desigur, mai există o cale de urmat (caracteristică produselor open-source), pentru o cât mai bună adecvare la necesitățile proprii — simplă în principiu (parcă mai simplă și mai sigură, decât studiul pe deasupra, al documentației încâlcite și trunchiate asociate), dar care necesită de obicei mult efort cognitiv și maximă concentrare: a studia codul-sursă (începând probabil cu fișierele-header ".h" din /usr/include/tesseract), sperând că dacă îl înțelegi suficient de bine, atunci vei putea să-l adaptezi cazului propriu.
De fapt, Tesseract pune la dispoziție o interfață de programare ("API"), care dacă este bine însușită, ne-ar permite să disecăm lucrurile și eventual, să intervenim cumva în anumite puncte ale procesului de recunoaștere a textului.
vezi Cărţile mele (de programare)